pandas层次化索引以及索引的堆(Stack )和 聚合操作
pandas层次化索引
【小技巧】:使用stack()的时候,level等于哪一个,哪一个就消失,出现在行里;使用unstack()的时候,level等于哪一个,哪一个就消失,出现在列里。
(1). 创建多层列索引
作者:YimmyLee
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
1.索引的堆(stack)
stack()
unstack()【小技巧】:使用stack()的时候,level等于哪一个,哪一个就消失,出现在行里;使用unstack()的时候,level等于哪一个,哪一个就消失,出现在列里。
(1). 创建多层列索引
#三层索引
df = DataFrame(data = np.random.randint(0,150,size = (1,8)),
columns = [['a',"a","a","a","b","b","b","b"],
['期中',"期中","期末","期末",'期中',"期中","期末","期末"],
["一单元","二单元","一单元","二单元","一单元","二单元","一单元","二单元"]],
index = ["Python"])
df

level代表层级, 0表示第一层, 1表示第二层,以此类推 。 -1代表最内层, 此处未演示。
df.stack(level = 1)
#把列索引放到行索引上面
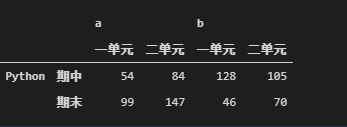
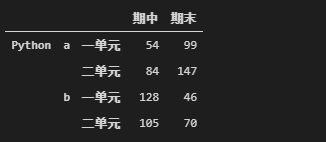
df.stack(level=(0,2))
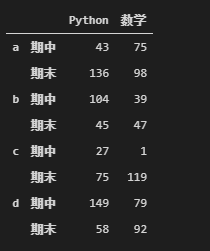
(2).创建多行行索引
df1 = DataFrame(np.random.randint(0,150,size = (8,2)),
index = pd.MultiIndex.from_product([list("abcd"), ["期中","期末"]]),
columns = ['Python',"数学"])
df1
df1.unstack()
#把第二层的行索引变成了最内层列索引
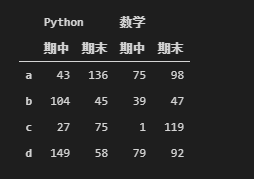
df1.unstack(level = 1)
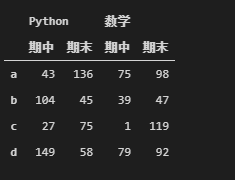
聚合操作也就是平均数,方差,最大值,最小值等。
【注意】
需要指定axis
【小技巧】和unstack()相反,聚合的时候,axis等于哪一个,哪一个就保留。
df1.div(10, axis = "index")
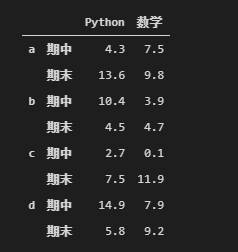
df1.sum(axis = 1) # 求和
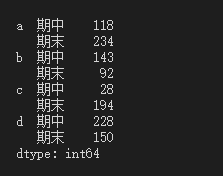
df1.std() #标准差:表示的是数据的离散程度
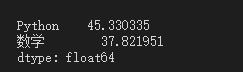
df4 = DataFrame(np.random.randint(0,150,size = (8,2)),
index = pd.MultiIndex.from_product([list("abcd"), ["期中","期末"]]),
columns = ['Python',"数学"])
df4
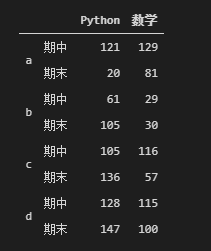
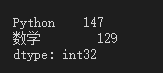
df4.max(axis=0)
本文链接:https://blog.csdn.net/weixin_44463903/article/details/104387199
作者:YimmyLee