Pytorch学习(7)-损失函数
损失函数用于描述模型预测值f(x)和真实值y的差距大小。它是一个非负实值函数,通常用L(y,f(x))来表示。
损失函数越小,模型的鲁棒性就越好。
损失函数是经验风险函数的核心部分,也是结果风险函数的重要组成部分。模型的风险结果包括风险项和正则项,通常如下所示:
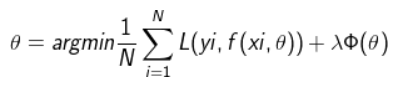
其中,前面的均值函数表示的是经验风险函数,L代表的是损失函数,后面的Φ是正则化项(regularizer)或者叫惩罚项(penalty term),它可以是L1,也可以是L2,或者其他的正则函数。整个式子表示的意思是找到使目标函数最小时的θ值。
二、常用的损失函数 铰链损失(Hinge Loss):主要用于支持向量机(SVM) 中; 互熵损失 (Cross Entropy Loss,Softmax Loss ):用于Logistic 回归与Softmax 分类中; 平方损失(Square Loss):主要是最小二乘法(OLS)中; 指数损失(Exponential Loss) :主要用于Adaboost 集成学习算法中; 三元组损失(Triplet-loss) 三、详细理解这节主要介绍三元组损失(Triplet-loss)函数。十八种损失函数见:https://blog.csdn.net/u011995719/article/details/85107524
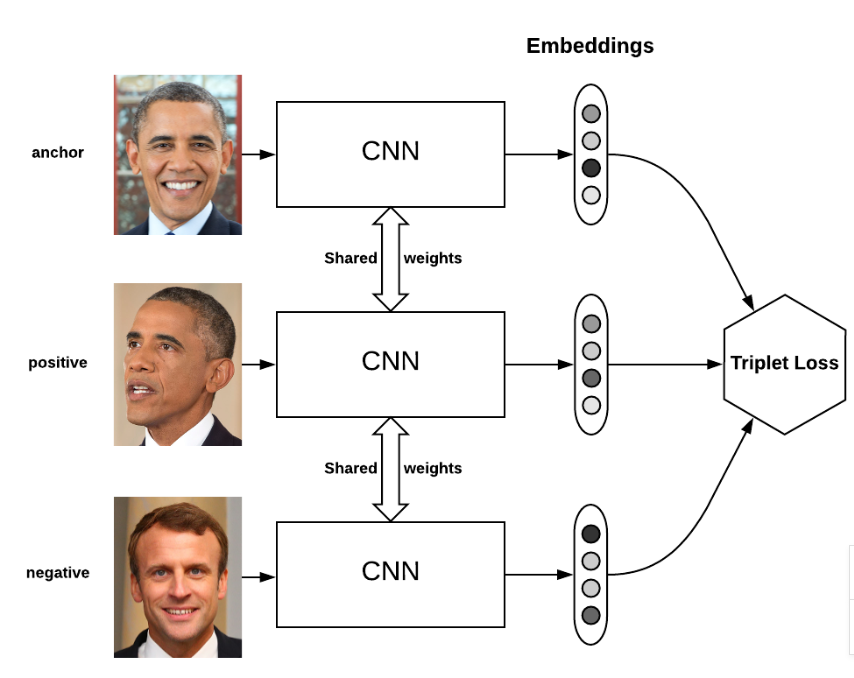
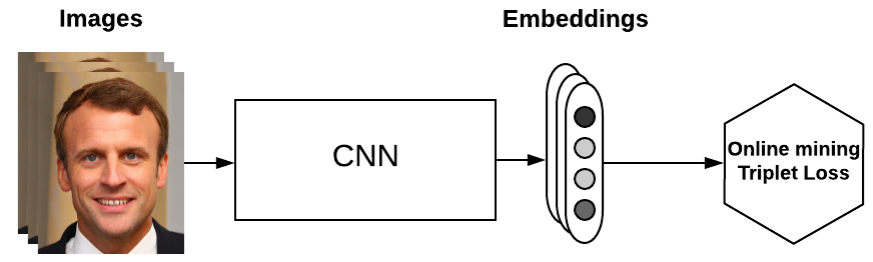
softmax最终的类别数是确定的,而triplet loss学到的是一个好的embedding,相似的图像在embedding空间里是相近的,可以判断是否是同一个人脸。 在深度学习训练中,我们需要尽可能的学习hard样本。是因为这些样本对损失影响较大,如果我们学习了很多对损失函数影响比较小的样本,会导致效果不好且浪费资源。比如正负样本不均衡时,负样本很多,如果一直学习负样本的话,训练起来对损失影响较小,所以我们会采取一些措施,将正负样本分来还要把最难分的样例分开。在此三元组损失函数中hard也是这个意思。 triplet-loss的思想: 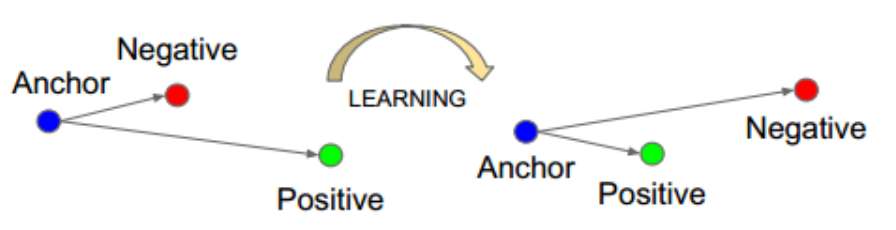
三重损失使一个anchor和一个正样本之间的距离最小化,两者具有相同的特性,并使一个anchor和不同特性的一个负样本之间的距离最大化。其中anchor为训练数据集中随机选取的一个样本,positive为和anchor属于同一类别的样本,而negative则为和anchor不同类的样本。学习后,使得同类样本positive样本更靠近anchor,而不同类的样本negative则远离anchor。
triplet-loss的数学表达式: 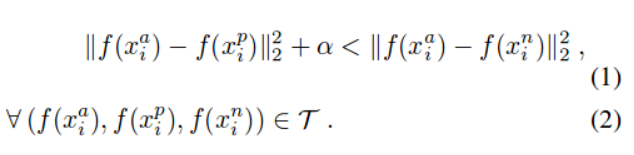
进一步的损失函数(目标函数)变为如下:
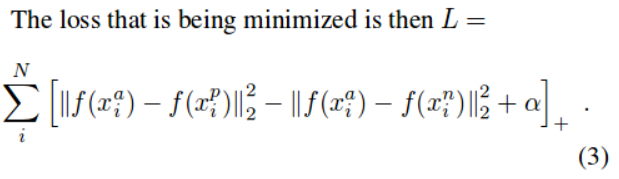
上式中的||*||为欧氏距离,所以:
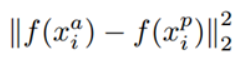 表示的是positive和anchor之间的欧氏距离
表示的是positive和anchor之间的欧氏距离
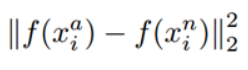 表示的是negative和anchor之间的欧式距离
表示的是negative和anchor之间的欧式距离
![]() 是指两者距离之间有一个最小的间隔(anchor和negative之间的距离和anchor和positive之间的距离)
是指两者距离之间有一个最小的间隔(anchor和negative之间的距离和anchor和positive之间的距离)
由损失函数可以看出:
当a与n之间的距离 < (a与p之间的距离 + ![]() )时,[]内的值大于0,就会产生损失。
)时,[]内的值大于0,就会产生损失。
当a与n之间的距离 > (a与p之间的距离 + ![]() )时,[]内的值小于0,损失为0。
)时,[]内的值小于0,损失为0。
上述目标函数标记为L,则当第i个triplet损失大于0的时候,仅就上述公式而言,有:
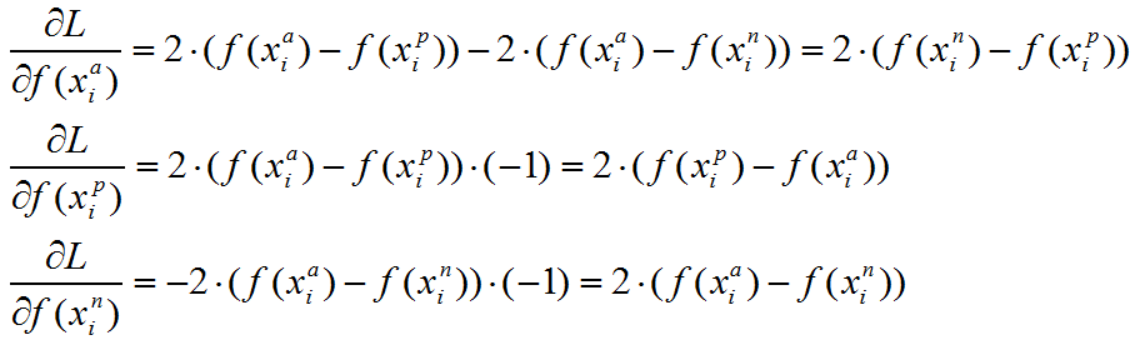
可以看到,对x_p和x_n特征表达的梯度刚好利用了求损失时候的中间结果,给的启示:如果在CNN中实现triplet loss layer,如果能够在前向传播中存储着两个中间结果,反向传播的时候就能避免重复计算。
三元组理解我们的目的是使loss在训练迭代中下降的越小越好,也就是要使得anchor与positive越接近越好,anchor与negative越远越好。
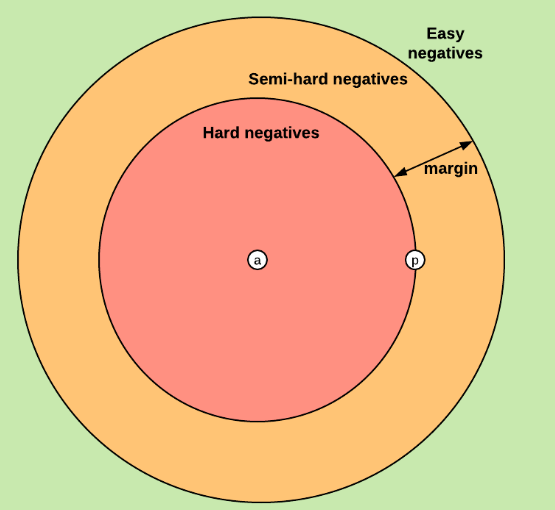
基于上面这些,分析一下margin值的取值:
当margin值越小时,loss也就越容易趋近于0,于是anchor与positive都不需要拉的太近,anchor与negative不需要拉的太远。就能使得loss很快趋近于0.这样训练得到的结果,不能够很好的区分相似的图像。
当margin越大时,就需要使得网络参数要拼命的拉近anchor、positive之间的距离,拉远anchor、negative之间的距离。如果margin值太大,很可能最后loss保持一个较大的值,难以趋近于0。
因此,设置一个合理的margin值很关键,这是衡量相似度的重要指标。简而言之,margin值设置越小,loss越容易趋近于0,但很难区分相似的图像。margin值设置的越大,loss值较难趋近于0,甚至导致网络不收敛,但可以较有把握的区分较为相似的图像。
损失函数确定好之后,如何在训练时寻找anchor对应的negative样本和positive样本成为一个要着重考虑的问题。那么这个损失函数具体是什么意思呢?
先选定a-p两元数组,然后在不是同一个人的里面找一个距离此人的距离小于![]() 的样本(这句话就对应上面的损失函数),因为这个是最难分的(从上面满足条件的样本中随机选的),所以为hard需要注意的是其中同一个人的图片不能作为negative,所以将其距离设为无穷大。这样的话就排除了那些同一人的样本,因为同一人的样本距离肯定小于
的样本(这句话就对应上面的损失函数),因为这个是最难分的(从上面满足条件的样本中随机选的),所以为hard需要注意的是其中同一个人的图片不能作为negative,所以将其距离设为无穷大。这样的话就排除了那些同一人的样本,因为同一人的样本距离肯定小于![]() 。
。

首先举个例子:
假设(batch_size, feat_dim)为(3,4),再简单点,令inputs为:
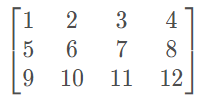
那么第一行(1,2,3,4)就代表第一个样本(S1),第二行(5,6,7,8)代表第二个样本(S2),以此类推。看一下样本之间的距离(欧氏距离)分布,为方便,用表示距离:

距离分布(开方之后)可以表示为矩阵D:
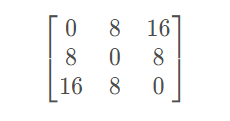
其中D(i,j)D(i,j)D(i,j)表示样本i,ji,ji,j之间的距离。
因为 ![]() ,而矩阵相乘 embeddings×embeddings.T中不仅包含了a∗ba*ba∗b的值,同时对角线上是向量平方的值,所以可以直接使用矩阵计算。
,而矩阵相乘 embeddings×embeddings.T中不仅包含了a∗ba*ba∗b的值,同时对角线上是向量平方的值,所以可以直接使用矩阵计算。
下面开始解析代码:
首先输入和例子一样:
inputs = torch.arange(1,13).view(3,4).float()
>>> inputs
tensor([[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.]])

n = inputs.size(0) # n = 3,为batch_size
# 每个数平方后, 进行sum(保持行数n不变),再扩展为(n,n)
dist = torch.pow(inputs, 2).sum(dim=1, keepdim=True).expand(n, n)
>>> dist
tensor([[ 30., 30., 30.],
[174., 174., 174.],
[446., 446., 446.]])
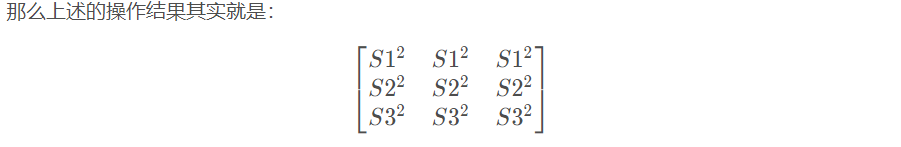
# 这样每个dis[i][j]代表的是样本i与样本j的平方的和
# 其中dist.t()是求矩阵dist的转置矩阵
dist = dist + dist.t()
>>> dist
tensor([[ 60., 204., 476.],
[204., 348., 620.],
[476., 620., 892.]])
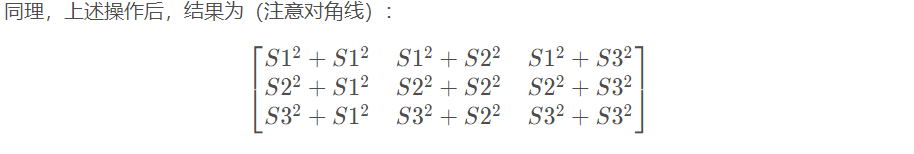
之后介绍一下函数addmm()的用法:1 * dist - 2(input@input.t())
# 1 * dist - 2(input@input.t())
dist.addmm_(1, -2, inputs, inputs.t())
>>> dist
tensor([[ 0., 64., 256.],
[ 64., 0., 64.],
[256., 64., 0.]])

最后,对上面进行开方,clamp做简单数值处理(为了数值的稳定性):小于min参数的dist元素值由min值取代。
根号下不能为0,0开根号没有问题的,但是梯度反向传播就会导致无穷大。
dist = dist.clamp(min=1e-12).sqrt()
>>> dist
tensor([[1.0000e-06, 8.0000e+00, 1.6000e+01],
[8.0000e+00, 1.0000e-06, 8.0000e+00],
[1.6000e+01, 8.0000e+00, 1.0000e-06]])
此时,样本对之间距离计算就到位了,下面进行的是hard样本挖掘。
七、hard样本挖掘
For each anchor, find the hardest positive and negative.
上一节操作输出的张量dist里面存储着各个样本之间的距离,首先看看targets:
targets:样本对应的标签(ground truth labels with shape——num_classes)
首先获取mask,类似掩模,# 这里 mask[i][j]=1 代表 i 和 j 的 label 相同(属于同一类别), mask[i][j]=0 则相反。
mask用于后面提取正样本和负样本。
# targets有n个类别,所以将它扩展成n*n的矩阵,判断该矩阵和转置矩阵对应元素之间是否相等
# 是否属于同一类别
mask = targets.expand(n, n).eq(targets.expand(n, n).t())
下面分别提取出正样本和负样本,对每个样本,在上面生成的距离矩阵中:
先过滤掉和它不同类别的样本对应的距离,剩下的就是和它同一类别的positive,然后再在剩下的positive中找到距离值最大的,就是我们需要的hard positive
寻找negative也是同理
for i in range(n):
dist_ap.append(dist[i][mask[i]].max().unsqueeze(0))
dist_an.append(dist[i][mask[i] == 0].min().unsqueeze(0))
详细解答上面代码:
在这之前已经得到了距离矩阵dist和掩膜mask。其中dist[i, j]和mask[i, j]:i和j表示两个样本,而dist[i, j]表示两个样本的距离,mask[i, j]表示两个样本是否为同一类别。
# 首先要指定所谓的hard样本是什么?
# 个人理解:它是同一人的不同姿态、衣服以及背景下的样本。
# 我们要做的就是找到同一类样本中距离最大的positive和不同类样本中距离最小的negative。
# 然后通过三元组损失,经过学习后,将上面距离大的缩小,将距离小的放大
# 下面详细解释一下
dist_ap.append(dist[i][mask[i]].max().unsqueeze(0))
dist_an.append(dist[i][mask[i] == 0].min().unsqueeze(0))
# ----------------------------------------------------------------
inputs = torch.arange(1, 13).view(3, 4).float()
n = inputs.size(0) # n = 3,为batch_size
# 每个数平方后, 进行sum(保持行数n不变),再扩展为(n,n)
dist = torch.pow(inputs, 2).sum(dim=1, keepdim=True).expand(n, n)
# 这样每个dis[i][j]代表的是样本i与样本j的平方的和
dist = dist + dist.t()
dist.addmm_(1, -2, inputs, inputs.t())
dist = dist.clamp(min=1e-12).sqrt()
print(dist)
targets = torch.arange(1, 4)
targets[2] = 1
mask = targets.expand(n, n).eq(targets.expand(n, n).t())
print(mask)
dist_ap, dist_an = [], []
# -------------------------------------------------------------------
# 上面代码都已经在前面见过了,所有假设input
# 此时经过计算得到的dist和mask为
tensor([[1.0000e-06, 8.0000e+00, 1.6000e+01],
[8.0000e+00, 1.0000e-06, 8.0000e+00],
[1.6000e+01, 8.0000e+00, 1.0000e-06]])
tensor([[ True, False, True],
[False, True, False],
[ True, False, True]])
# --------------------------------------------------------------------
# 现在开始解析
dist_ap.append(dist[i][mask[i]].max().unsqueeze(0))
dist_an.append(dist[i][mask[i] == 0].min().unsqueeze(0))
#--------------------------------------------------------------------
print(mask[0]) # 查看一下样本i=0与其它几个样本是否为同一类别,true为是。
tensor([ True, False, True]) # 发现0与0、3是同一类别的
#--------------------------------------------------------------------
print(dist[0][mask[0]]) # 再看一下相同类别之间的距离
tensor([1.0000e-06, 1.6000e+01]) # 分别为0和0,0和3
# ------------------------------------------------------------------
print(dist[0][mask[0]].max()) # 取其中最大的
tensor(16.)
print(dist[0][mask[0]].max().unsqueeze(0)) # 增加一维
tensor([16.])
# -------------------------------------------------------------------
# 上面就是查找同一类别中距离最大的样本
# 下面同理查找不同样本中距离最小的样本,省略。
拼接为新的tensor,计算相应的损失。
# cat使用用于将所有的hard样本距离拼接起来
dist_ap = torch.cat(dist_ap)
dist_an = torch.cat(dist_an)
y = torch.ones_like(dist_an)
loss = self.ranking_loss(dist_an, dist_ap, y)
作者:蓑衣老汉