分类问题损失函数 - 交叉熵
参考链接:https://zhuanlan.zhihu.com/p/61944055
信息熵: 表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。熵越大,随机变量或系统的不确定性就越大。公式如下: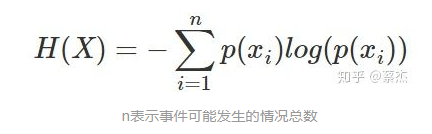 相对熵: 又称KL散度,用于衡量对于同一个随机变量x的两个分布p(x)和q(x)之间的差异。在机器学习中,p(x)从常用于描述样本的真实分布,而q(x)常用于表示预测的分布。KL散度值越小表示两个分布越接近。 公式如下:
相对熵: 又称KL散度,用于衡量对于同一个随机变量x的两个分布p(x)和q(x)之间的差异。在机器学习中,p(x)从常用于描述样本的真实分布,而q(x)常用于表示预测的分布。KL散度值越小表示两个分布越接近。 公式如下: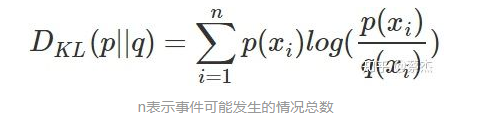 交叉熵(cross entropy): 将KL散度公式进行变形得到:
交叉熵(cross entropy): 将KL散度公式进行变形得到: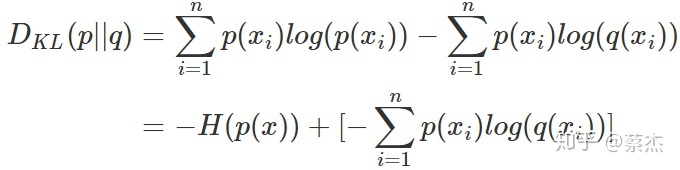
前半部分就是p(x)的熵,后半部分就是交叉熵:
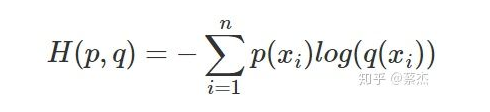
机器学习中,我们常常使用KL散度来评估predict和label之间的差别,但是由于KL散度的前半部分是一个常量,所以我们常常将后半部分的交叉熵作为损失函数,其实二者是一样的。 相对熵、交叉熵主要区别:
参考地址:https://www.zhihu.com/question/41252833/answer/195901726
相对熵:用来衡量两个概率分布之间的差异。
交叉熵:用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。 应用:
参考地址:https://blog.csdn.net/Biyoner/article/details/84728417
图像分割中最常用的loss function就是逐像素cross entropy。该损失函数分别检查每个像素,将类预测(深度方向的像素向量)与我们的onehot目标向量进行比较。
交叉熵的损失函数单独评估每个像素矢量的类预测,然后对所有像素求平均值,所以我们可以认为图像中的像素被平等的学习了。但是,医学图像中常出现类别不均衡(class imbalance)的问题,由此导致训练会被像素较多的类主导,对于较小的物体很难学习到其特征,从而降低网络的有效性。 类别不均衡:
参考链接:https://www.zhihu.com/search?type=content&q=class%20imbalance
机器学习中常常会遇到数据的类别不平衡(class imbalance),也叫数据偏斜(class skew)。以常见的二分类问题为例,我们希望预测病人是否得了某种罕见疾病。但在历史数据中,阳性的比例可能很低(如百分之0.1)。在这种情况下,学习出好的分类器是很难的,而且在这种情况下得到结论往往也是很具迷惑性的。
作者:temperamentalkj