随机森林 (Random Forests) 简单介绍与应用
简单来说,集成方法 就是组合多个模型,以获得更好效果。
1.2 两种集成方法 平均法(averaging methods):也有人直接称之为“袋装法”,所有算法进行 相互独立 训练得到各自的模型,然后再进行投票选择最好的模型。如 随机森林(Forests of randomized trees) 与 袋装法(Bagging methods) 。 提升法(boosting methods): 训练开始后,从第二个模型开始,每个模型是针对前一个模型进行加权叠加。如 自适应提升(Adaboost) 与 梯度树提升(Gradient Tree Boosting) 。 2 随机森林(Random Forests) 2.1 “森林”在随机森林中,集合中的每棵树都是 从训练集中抽取的替换样本中构建的。大量的这样的树,即构成了所说的“森林”。
2.2 “随机”在树的构造过程中分割每个节点时,可以从所有输入特征中找到最佳分割,也可以在1~max_features 范围中随机选取若干个特征进行分割节点操作。
这两种随机性来源的目的是降低森林估计器的方差。事实上,单个决策树通常表现出高方差,并且倾向于过度拟合。森林中的注入随机性使得决策树具有一定程度的解耦预测误差。
通过取这些预测的平均值,一些错误可以抵消。随机森林通过组合不同的树来减少方差,有时以稍微增加偏差为代价。在实践中,方差的减少通常是显著的,因此产生了一个整体上更好的模型。
简单分享一下sklearn官网的例子。
重要说明 sklearn的版本为0.22.1,之前的版本不一定能运行一下代码。
数据集来自于sklearn官网例子,已经内置于sklearn中,具体信息可以参考 https://scikit-learn.org/stable/datasets/index.html#wine-recognition-dataset
如果对ROC曲线不甚了解的话,不妨参考这篇大佬的文章.
这里只强调其中一点:AUC值越大,模型的分类效果越好。
代码1
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_roc_curve
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
# 使用官网自带的函数,y是类别,y 取值范围为 {1,2,3}
X, y = load_wine(return_X_y=True)
# 将多分类问题转换为二分类问题
y = y == 2
# 分割为训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 训练svc模型
svc = SVC(random_state=42)
svc.fit(X_train, y_train)
可以看到输出内容为:
SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=42, shrinking=True, tol=0.001,
verbose=False)
接着查看svc模型的ROC曲线图,代码如下:
代码2
# 效果展示
svc_disp = plot_roc_curve(svc, X_test, y_test)
plt.show()
可以看到如图所示的ROC曲线图:
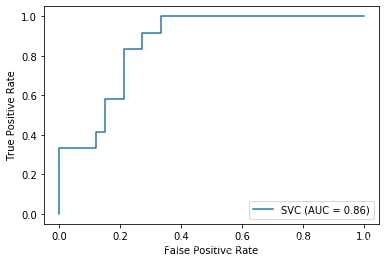
代码3
# 随机森林分类器
rfc = RandomForestClassifier(n_estimators=10, random_state=42)
# 拟合
rfc.fit(X_train, y_train)
ax = plt.gca()
rfc_disp = plot_roc_curve(rfc, X_test, y_test, ax=ax, alpha=0.8)
svc_disp.plot(ax=ax, alpha=0.8)
plt.show()
可以看到RandomForests与SVC的ROC曲线图如下:
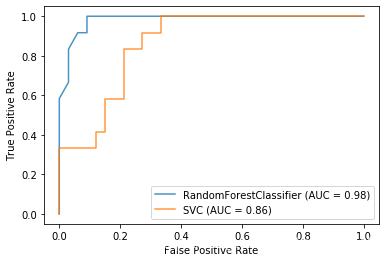
调参工作
svc模型参数中c默认为1实在太小,而随机森林却把参数n_estimators=10,看起来的确有些不公平,不妨调整一下。可以发现n_estimators=3时效果最佳,AUC=0.99,而SVC中的C=300时才能达到0.96的AUC。
更多例子参考sklearn官网例子,https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html#examples-using-sklearn-ensemble-randomforestclassifier
Smileyan
2020年3月1日 0:06
作者:smile-yan