pandas合并、处理csv文件、随机抽样
Merge/Join .csv (合并csv文件)
作者:Can_9420
import pandas as pd
ratings = pd.read_csv('C:/Users/Can/Desktop/RS Project/ratings.csv')
movies= pd.read_csv('C:/Users/Can/Desktop/RS Project/movies.csv')
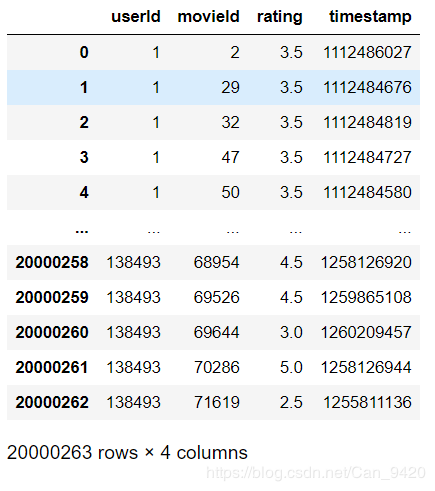
ratings.csv: users’ rating of movies
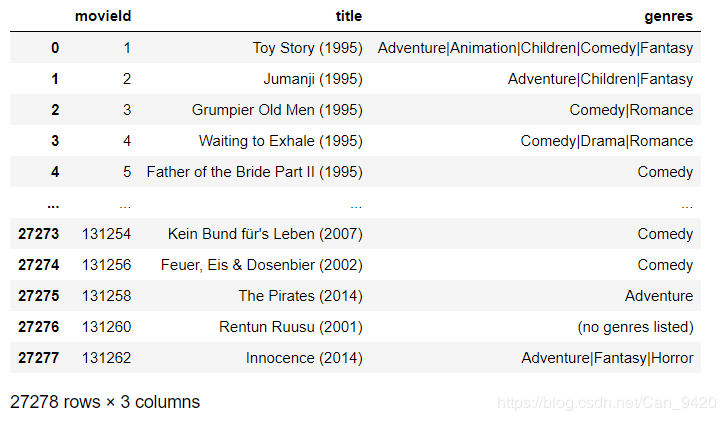
movies.csv: movies description
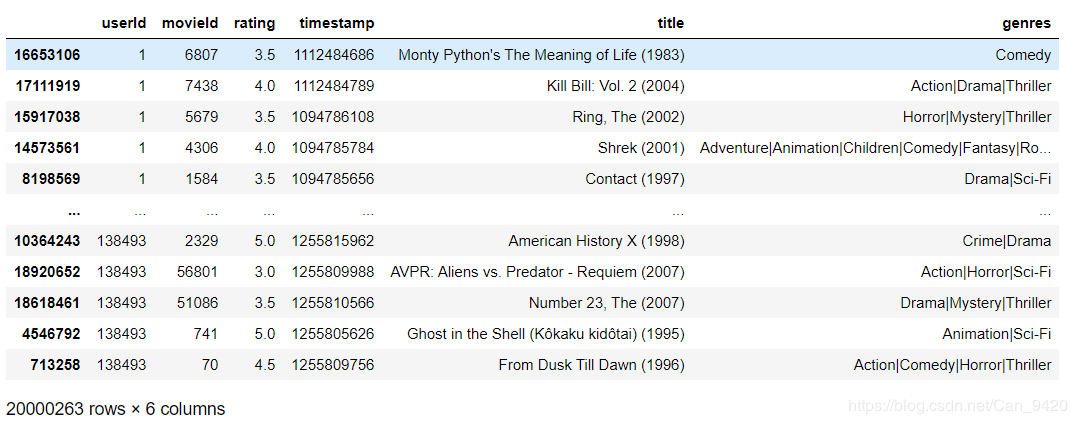
Merge合并
把两个csv文件合并,显示出每位用户给电影的打分以及电影详情。
data = pd.merge(movies, ratings, on=['movieId'], how='left')
data = data[['userId', 'movieId', 'rating', 'timestamp', 'title', 'genres']]
# check if there is null value and list the row
# 检查是否有null值,并列出null值行
data[data.isnull().values==True]
# delete null value row -- 删除有null值行
data.dropna(axis=0, how='any', inplace=True)
# convert datatype of a single row -- 转换datatype至原文件格式
data['userId'] = data['userId'].astype('int')
data['timestamp'] = data['timestamp'].astype('int')
# export combined csv -- 导出合并csv文件
data.to_csv('data.csv')
# read combined csv -- 读取合并csv文件
combined = pd.read_csv('C:/Users/Can/Desktop/RS Project/data.csv')
# delete useless column -- 删除无用列
combined = combined.drop('Unnamed: 0', axis=1) # axis默认为0删除行,1为删除列
# sort by userId
combined.sort_values('userId', inplace=True)
合并后的csv
# df.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
# n = number of rows(optional, cannot be used with frac) 抽取的行数;
# frac = fraction/proportion(optional, cannot be used with n) 抽取的比例;
# replace = Allow or disallow sampling of the same row more than once (boolean, default False) 是否为有放回抽样;
# weights (str or ndarray-like, optional) 权重
# random_state (int to use as interval, or call np.random.get_state(), optional) 整数作为间隔,或者调用np.random.get_state()
# axis = extract row or column (0->row, 1->column) 抽取行还是列(0是行,1是列)
# random select 10% from dataset
sample = combined.sample(frac=0.1, random_state=5, axis=0)
# export to csv file
sample.to_csv('userRating.csv')
作者:Can_9420
相关文章
Wilma
2020-04-12
Isoke
2020-11-16
Daphne
2020-05-13
Ula
2023-05-12
Crystal
2023-05-12
Jacuqeline
2023-05-12
Karli
2023-05-12
Kirima
2023-05-13
Bertha
2023-07-20
Tesia
2023-07-20
Heather
2023-07-20
Aggie
2023-07-20
Qamar
2023-07-20
Rose
2023-07-20
Bliss
2023-07-21
Lillian
2023-07-21
Tertia
2023-07-21
Malinda
2023-07-24