TF-IDF和BM25算法原理及python实现
1 TF-IDF
TF-IDF是英文Term Frequency–Inverse Document Frequency的缩写,中文叫做词频-逆文档频率。


一个用户问题与一个标准问题的TF-IDF相似度,是将用户问题中每一词与标准问题计算得到的TF-IDF值求和。计算公式如下:
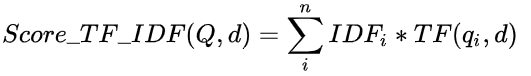
TF-IDF算法,计算较快,但是存在着缺点,由于它只考虑词频的因素,没有体现出词汇在文中上下文的地位,因此不能够很好的突出语义信息。
import numpy as np
class TF_IDF_Model(object):
def __init__(self, documents_list):
self.documents_list = documents_list
self.documents_number = len(documents_list)
self.tf = []
self.idf = {}
self.init()
def init(self):
df = {}
for document in self.documents_list:
temp = {}
for word in document:
temp[word] = temp.get(word, 0) + 1/len(document)
self.tf.append(temp)
for key in temp.keys():
df[key] = df.get(key, 0) + 1
for key, value in df.items():
self.idf[key] = np.log(self.documents_number / (value + 1))
def get_score(self, index, query):
score = 0.0
for q in query:
if q not in self.tf[index]:
continue
score += self.tf[index][q] * self.idf[q]
return score
def get_documents_score(self, query):
score_list = []
for i in range(self.documents_number):
score_list.append(self.get_score(i, query))
return score_list
2 BM25算法
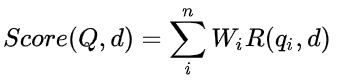

import numpy as np
from collections import Counter
class BM25_Model(object):
def __init__(self, documents_list, k1=2, k2=1, b=0.5):
self.documents_list = documents_list
self.documents_number = len(documents_list)
self.avg_documents_len = sum([len(document) for document in documents_list]) / self.documents_number
self.f = []
self.idf = {}
self.k1 = k1
self.k2 = k2
self.b = b
self.init()
def init(self):
df = {}
for document in self.documents_list:
temp = {}
for word in document:
temp[word] = temp.get(word, 0) + 1
self.f.append(temp)
for key in temp.keys():
df[key] = df.get(key, 0) + 1
for key, value in df.items():
self.idf[key] = np.log((self.documents_number - value + 0.5) / (value + 0.5))
def get_score(self, index, query):
score = 0.0
document_len = len(self.f[index])
qf = Counter(query)
for q in query:
if q not in self.f[index]:
continue
score += self.idf[q] * (self.f[index][q] * (self.k1 + 1) / (
self.f[index][q] + self.k1 * (1 - self.b + self.b * document_len / self.avg_documents_len))) * (
qf[q] * (self.k2 + 1) / (qf[q] + self.k2))
return score
def get_documents_score(self, query):
score_list = []
for i in range(self.documents_number):
score_list.append(self.get_score(i, query))
return score_list
作者:nathan_deep