springboot+kafka中@KafkaListener动态指定多个topic问题
说明
总结一下大家问的最多的一个问题
终极方法
思路
实现
代码
总结
说明本项目为springboot+kafak的整合项目,故其用了springboot中对kafak的消费注解@KafkaListener
首先,application.properties中配置用逗号隔开的多个topic。
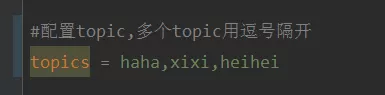
方法:利用Spring的SpEl表达式,将topics 配置为:@KafkaListener(topics = “#{’${topics}’.split(’,’)}”)
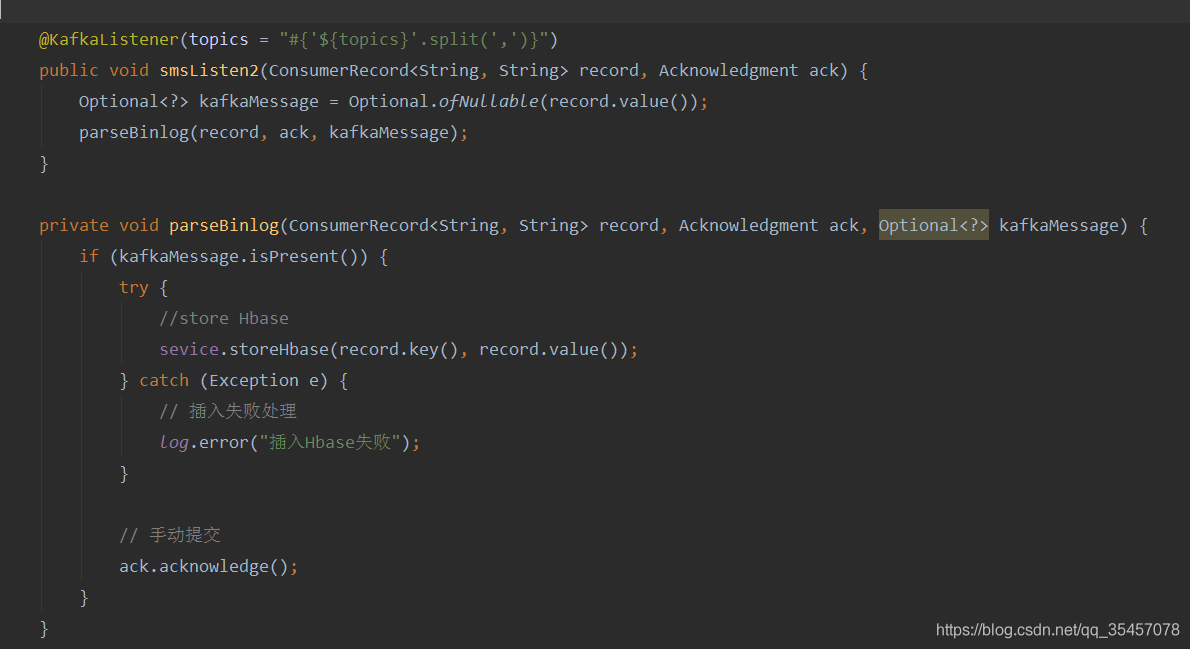
运行程序,console打印的效果如下:

因为只开了一条消费者线程,所以所有的topic和分区都分配给这条线程。
如果你想开多条消费者线程去消费这些topic,添加@KafkaListener注解的参数concurrency的值为自己想要的消费者个数即可(注意,消费者数要小于等于你开的所有topic的分区数总和)

运行程序,console打印的效果如下:

如何在程序运行的过程中,改变topic,消费者能够消费修改后的topic?
ans: 经过尝试,使用@KafkaListener注解实现不了此需求,在程序启动的时候,程序就会根据@KafkaListener的注解信息初始化好消费者去消费指定好的topic。如果在程序运行的过程中,修改topic,不会让此消费者修改消费者的配置再重新订阅topic的。
不过我们可以有个折中的办法,就是利用@KafkaListener的topicPattern参数来进行topic匹配。
具体如何操作的可以看下这篇文章:
https://www.jb51.net/article/271098.htm
终极方法 思路不使用@KafkaListener,使用kafka原生客户端依赖,手动初始化消费者,开启消费者线程。
在消费者线程中,每次循环都从配置、数据库或者其他配置源获取最新的topic信息,与之前的topic比较,如果发生变化,重新订阅topic或者初始化消费者。
实现加入kafka客户端依赖(本次测试服务端kafka版本:2.12-2.4.0)
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.3.0</version>
</dependency>
代码
@Service
@Slf4j
public class KafkaConsumers implements InitializingBean {
/**
* 消费者
*/
private static KafkaConsumer<String, String> consumer;
/**
* topic
*/
private List<String> topicList;
public static String getNewTopic() {
try {
return org.apache.commons.io.FileUtils.readLines(new File("D:/topic.txt"), "utf-8").get(0);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 初始化消费者(配置写死是为了快速测试,请大家使用配置文件)
*
* @param topicList
* @return
*/
public KafkaConsumer<String, String> getInitConsumer(List<String> topicList) {
//配置信息
Properties props = new Properties();
//kafka服务器地址
props.put("bootstrap.servers", "192.168.9.185:9092");
//必须指定消费者组
props.put("group.id", "haha");
//设置数据key和value的序列化处理类
props.put("key.deserializer", StringDeserializer.class);
props.put("value.deserializer", StringDeserializer.class);
//创建消息者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅topic的消息
consumer.subscribe(topicList);
return consumer;
}
/**
* 开启消费者线程
* 异常请自己根据需求自己处理
*/
@Override
public void afterPropertiesSet() {
// 初始化topic
topicList = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
if (org.apache.commons.collections.CollectionUtils.isNotEmpty(topicList)) {
consumer = getInitConsumer(topicList);
// 开启一个消费者线程
new Thread(() -> {
while (true) {
// 模拟从配置源中获取最新的topic(字符串,逗号隔开)
final List<String> newTopic = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
// 如果topic发生变化
if (!topicList.equals(newTopic)) {
log.info("topic 发生变化:newTopic:{},oldTopic:{}-------------------------", newTopic, topicList);
// method one:重新订阅topic:
topicList = newTopic;
consumer.subscribe(newTopic);
// method two:关闭原来的消费者,重新初始化一个消费者
//consumer.close();
//topicList = newTopic;
//consumer = getInitConsumer(newTopic);
continue;
}
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("key:" + record.key() + "" + ",value:" + record.value());
}
}
}).start();
}
}
}
说一下第72行代码:
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
上面这行代码表示:在100ms内等待Kafka的broker返回数据.超市参数指定poll在多久之后可以返回,不管有没有可用的数据都要返回。
在修改topic后,必须等到此次poll拉取的消息处理完,while(true)循环的时候检测topic发生变化,才能重新订阅topic.
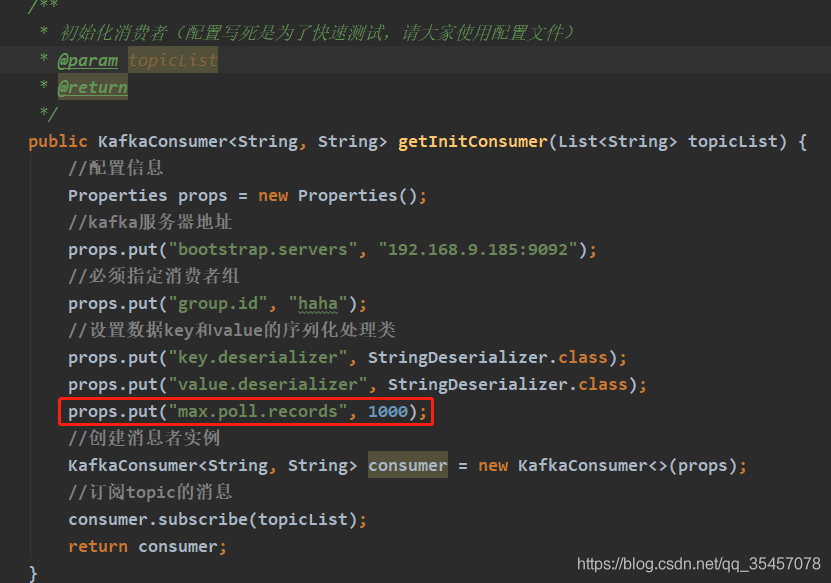
poll()方法一次拉取得消息数默认为:500,如下图,kafka客户端源码中设置的。

如果想自定义此配置,可在初始化消费者时加入
运行结果(测试的topic中都无数据)
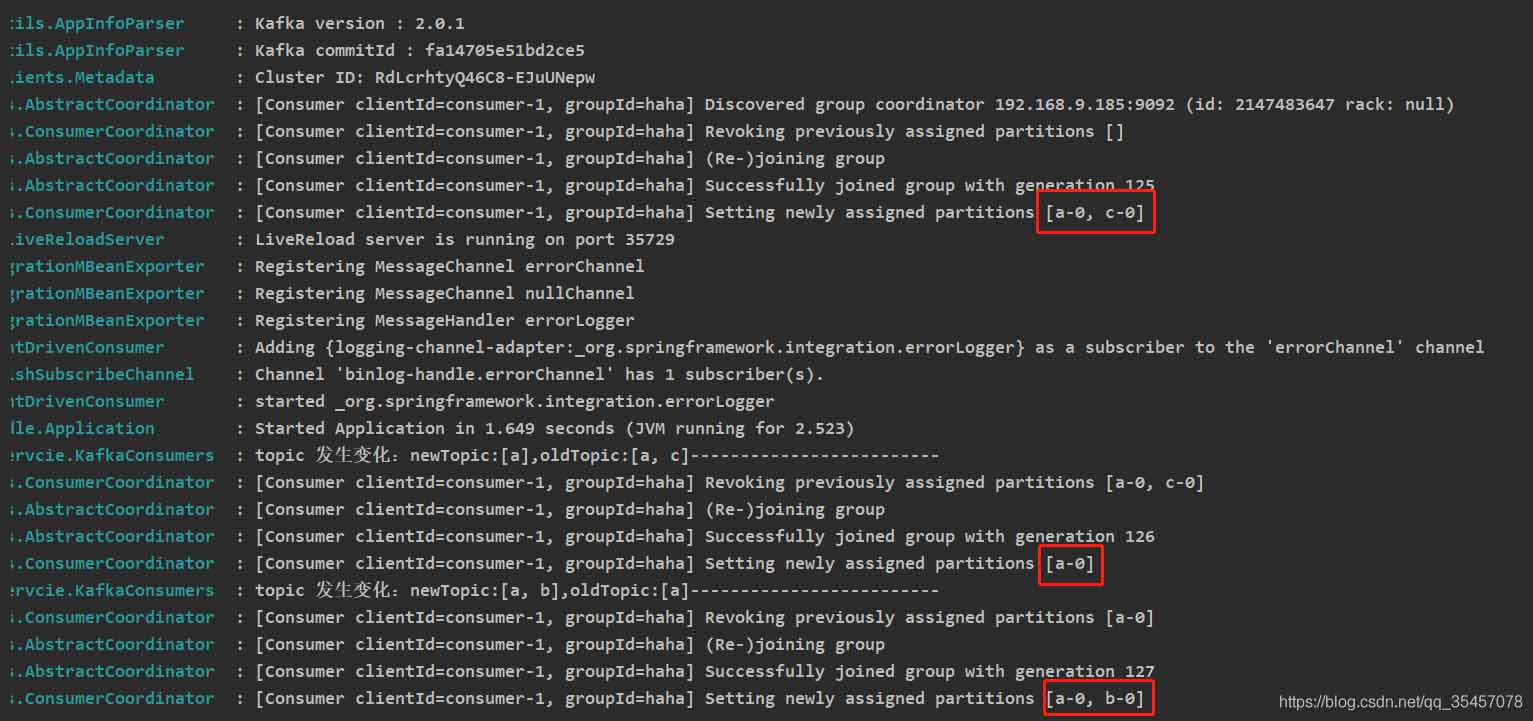
注意:KafkaConsumer是线程不安全的,不要用一个KafkaConsumer实例开启多个消费者,要开启多个消费者,需要new 多个KafkaConsumer实例。
总结以上为个人经验,希望能给大家一个参考,也希望大家多多支持软件开发网。