Splinter+pyautogui爬取淘宝小米10评论
1、splinter 是类似 selenium 的 一个web自动化测试的工具,
在这程序里用来驱动浏览器打开淘宝网、搜索mi10、登录
淘宝、进入小米官方旗舰店、获取小米10评论、翻页等功能。
2、pyautogui 可以驱动键盘和鼠标,这里用来处理滑块验证。
3、如果你觉得这篇博客对你有帮助,请点个赞或者评论“666”,
若感谢作者,可以打赏。谢谢。
4、先看下这个程序爬取的结果吧: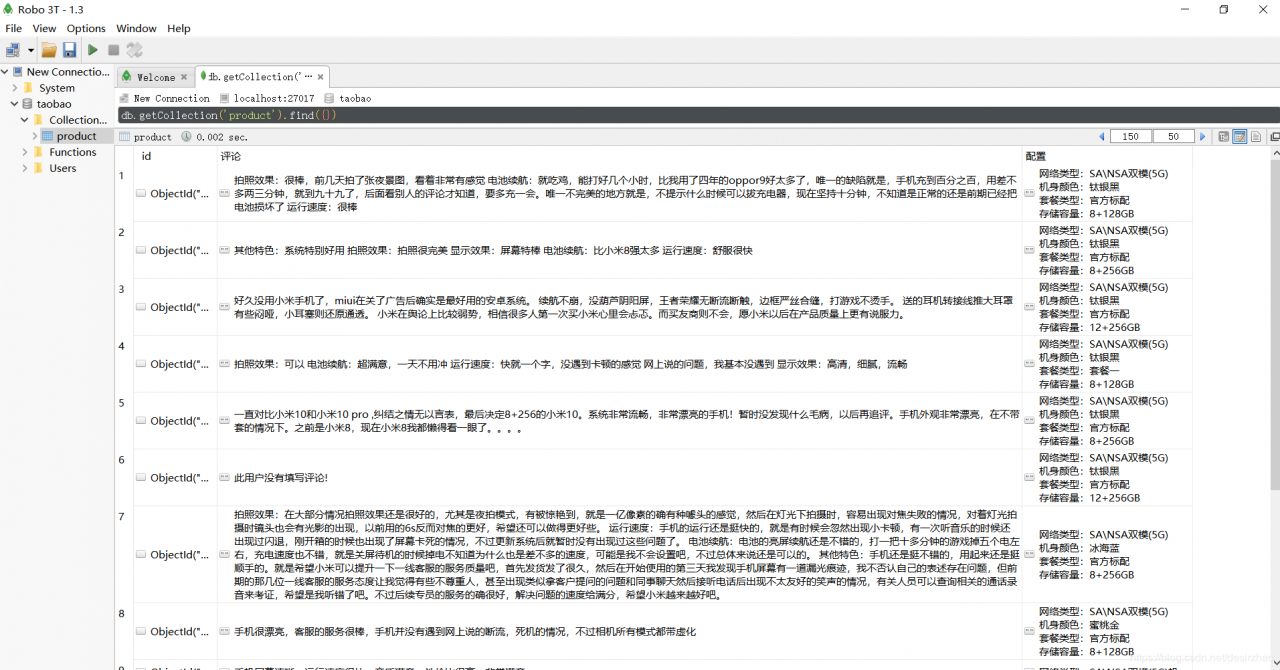
1.1先引入splinter
from splinter.browser import Browser
1.2设置 url ,还有 本地的user- agent。我用firefox浏览器,已装浏览器驱动
url = "https://www.taobao.com"
browser = Browser("firefox",user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0")
1.3开始访问淘宝网
browser.visit(url)
1.4弹出淘宝网。在搜索框中填入 mi10。用find_by_id()方法捕获搜索框,搜索框的 id 是 q ,这里写法与 selenium不同(#q)。fill(‘mi10’)填写 ‘mi10’。然后点击搜索 。
browser.find_by_id('q').first.fill('mi10')
browser.find_by_css('.btn-search').click()
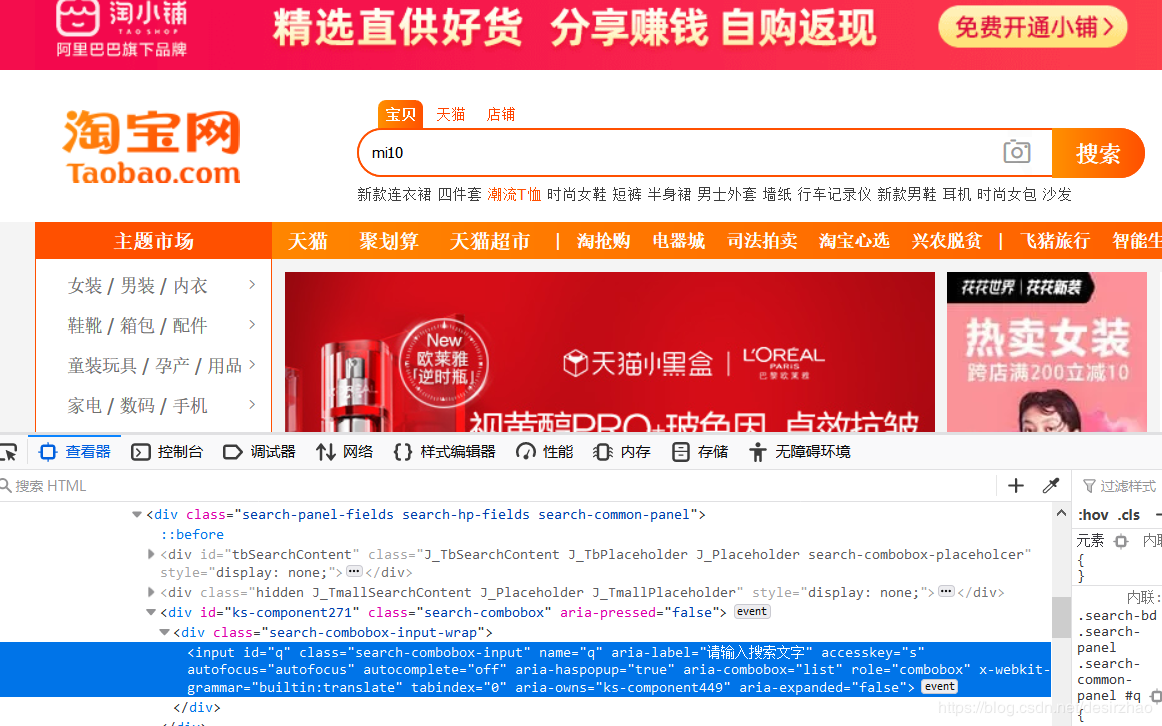
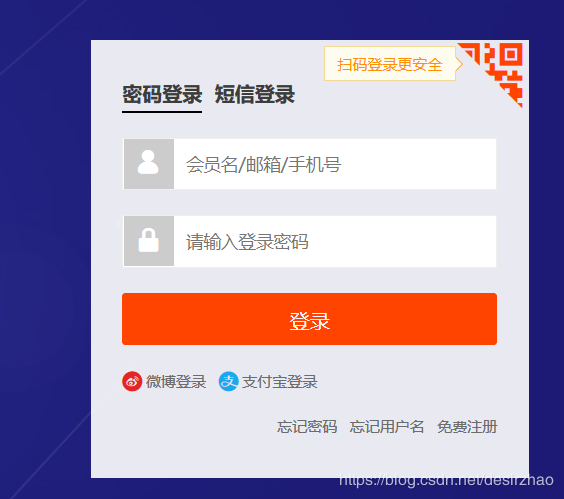
1.5上一步导致弹出登录页面,在登录页面输入账号、密码,点击登录
loginID是你的账号,password是密码。
browser.find_by_id('fm-login-id').first.fill('loginID')
browser.find_by_id('fm-login-password').first.fill('password')
browser.find_by_css('.fm-button').click()
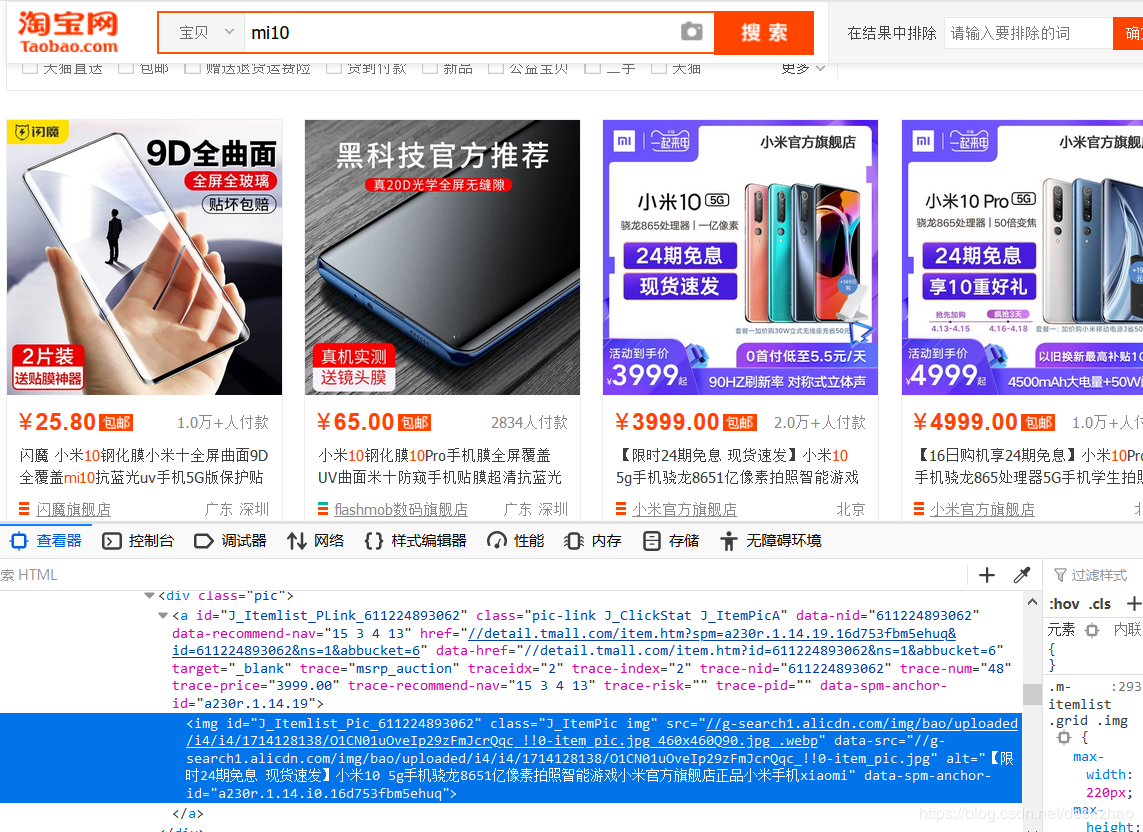
1.6 这里点击、进入小米官方旗舰店。上一步会弹出小米官方旗舰店小米10的售卖窗口。
#点击小米官方旗舰店
browser.find_by_css('#J_Itemlist_Pic_611224893062').click()
#上一步会弹出小米官方旗舰店小米10的售卖窗口,如果弹出的是标签页,则不用
#指定到弹出的窗口,后面操作
window = browser.windows[1]
window.is_current = True
1.7以上部分的代码如下:
from splinter.browser import Browser
#获取评论前的操作
def ready_option(url):
#开始访问
browser.visit(url)
#输入mi10,点击搜索。
browser.find_by_id('q').first.fill('mi10')
browser.find_by_css('.btn-search').click()
#输入账号、密码,点击登录
browser.find_by_id('fm-login-id').first.fill('loginID')
browser.find_by_id('fm-login-password').first.fill('password')
browser.find_by_css('.fm-button').click()
#点击小米官方旗舰店
browser.find_by_css('#J_Itemlist_Pic_611224893062').click()
#上一步会弹出小米官方旗舰店小米10的售卖窗口
#指定到弹出的窗口
window = browser.windows[1]
window.is_current = True
2、点击评价及滑块验证
2.1点击累计评价后面的数字
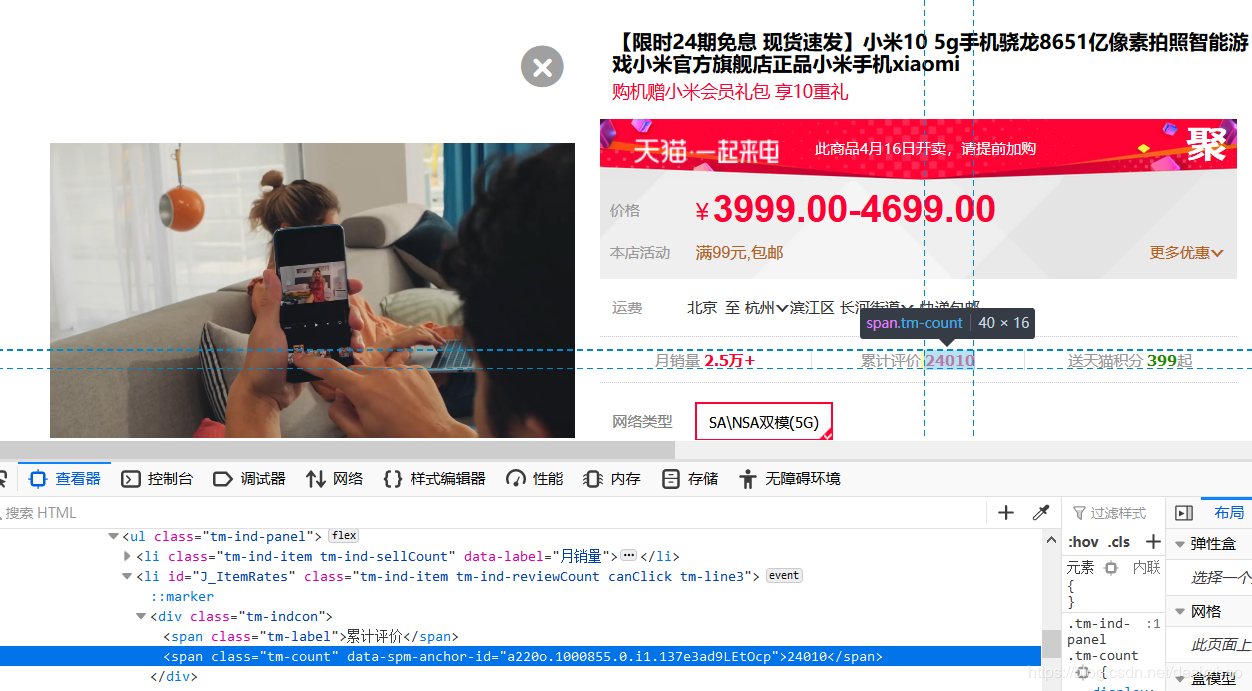
browser.find_by_css('#J_ItemRates > div:nth-child(1) > span:nth-child(2)').click()
2.2这一步可能会弹出 滑块验证,所以用pyautogui 驱动鼠标滑动完成验证。
滑块验证的小窗口位置是固定的,但有时候滑块验证右边 也有滑块需要下拉。所以用pyautogui 驱动鼠标 按路径1、2拖放。
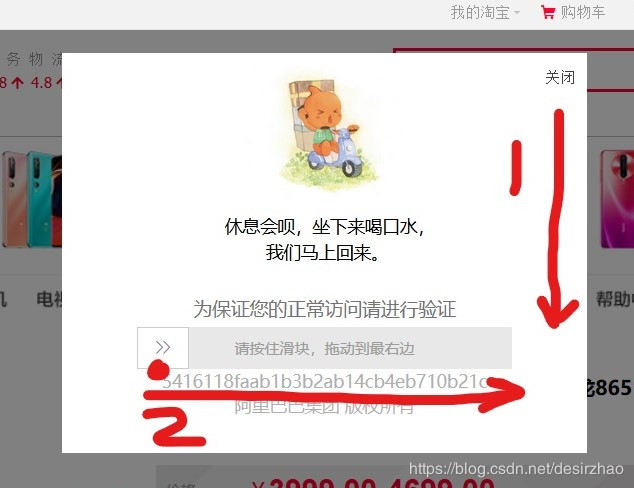
2.3滑块验证的代码如下。先移到位置1起点(moveTo,duration是持续时间或速度),再拖放到1终点(drag),再按路径2拖放,拖放不要太快。
#滑块验证处理
def dispose_slider():
time.sleep(0.2)
pyautogui.moveTo(x=1080, y=503, duration=0.25)
pyautogui.dragTo(x=1080, y=560, duration=0.5)
time.sleep(0.2)
pyautogui.moveTo(x=660, y=677, duration=0.25)
pyautogui.dragTo(x=1300, y=677, duration=0.8)
#休息0.25秒,表示对淘宝的尊敬
time.sleep(0.25)
2.4 所以点击评价的代码如下。
需要引入相关库。
import pyautogui
import time
from splinter.exceptions import ElementDoesNotExist
#点击评价
def click_comment():
#不管有没有滑块验证,先划两下
dispose_slider()
dispose_slider()
time.sleep(0.2)
# 点击评价
try:
browser.find_by_css('#J_ItemRates > div:nth-child(1) > span:nth-child(2)').click()
#防止刷新过快,捕获不到 评价 元素
except ElementDoesNotExist:
#有时候滑块验证在拖放滑块后,还需要刷新,按F5
pyautogui.hotkey('f5')
browser.find_by_css('#J_ItemRates > div:nth-child(1) > span:nth-child(2)').click()
3、获取用户评论及配置,然后保存
3.1获取评论。1页20个评论都是在tr标签下,有20个tr标签。所以先获取这20个tr标签。
# 获取的评论comment是一个列表(List)
comment = browser.find_by_css('.rate-grid').find_by_tag('tr')
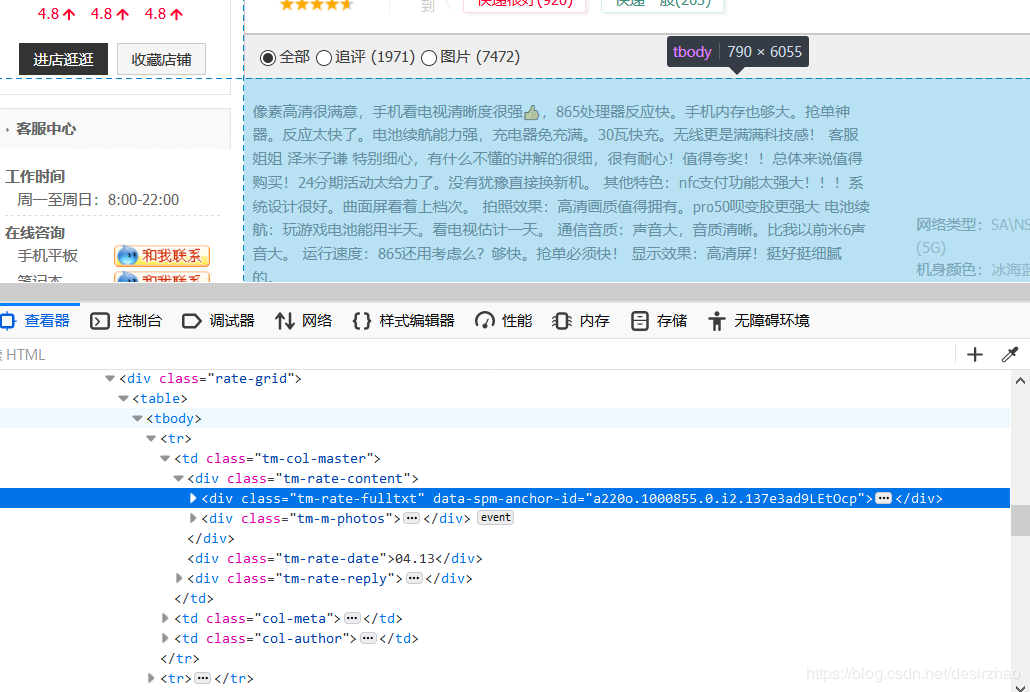
然后遍历获取每个评论及手机配置:
from selenium.common import exceptions as ex
#获取当前页面的评论
def get_comment():
try:
# 获取的comment是一个列表(List)
comment = browser.find_by_css('.rate-grid').find_by_tag('tr')
#遍历,获取每个评论及手机配置
for item in comment:
'''
#直接print
print('评论:' + i.find_by_css('.rate-grid .tm-rate-content').text)
print('配置:'+ i.find_by_css('.rate-sku').text + '\n')
'''
#以字典的形式保存到mongoDB
#评论用父标签.tm-rate-content,如果当前标签 tm-rate-fulltxt会捕获到别的字符
result = {'评论': item.find_by_css('.tm-rate-content').text,
'配置': item.find_by_css('.rate-sku').text}
#存到mongoDB
save_to_mongo(result)
#可能出现滑块验证,导致捕获不到相关元素,从而出错
except ElementDoesNotExist or ex.StaleElementReferenceException :
dispose_slider()
3.2保存到mongoDB
#以字典的形式保存到mongoDB
def save_to_mongo(result):
client = pymongo.MongoClient('localhost')
# 指定数据库
db = client['taobao']
try:
if db['product'].insert_one(result):
print('存储到MONGODB成功')
except Exception:
print('存储到MONGODB失败',result)
4、翻页
4.1分析。下一页的CSS选择器:第1页是.rate-paginator > a:nth-child(6),
第2页、第5页分别是.rate-paginator > a:nth-child(7),.rate-paginator > a:nth-child(10)。第6页及后面的页:.rate-paginator > a:nth-child(11)
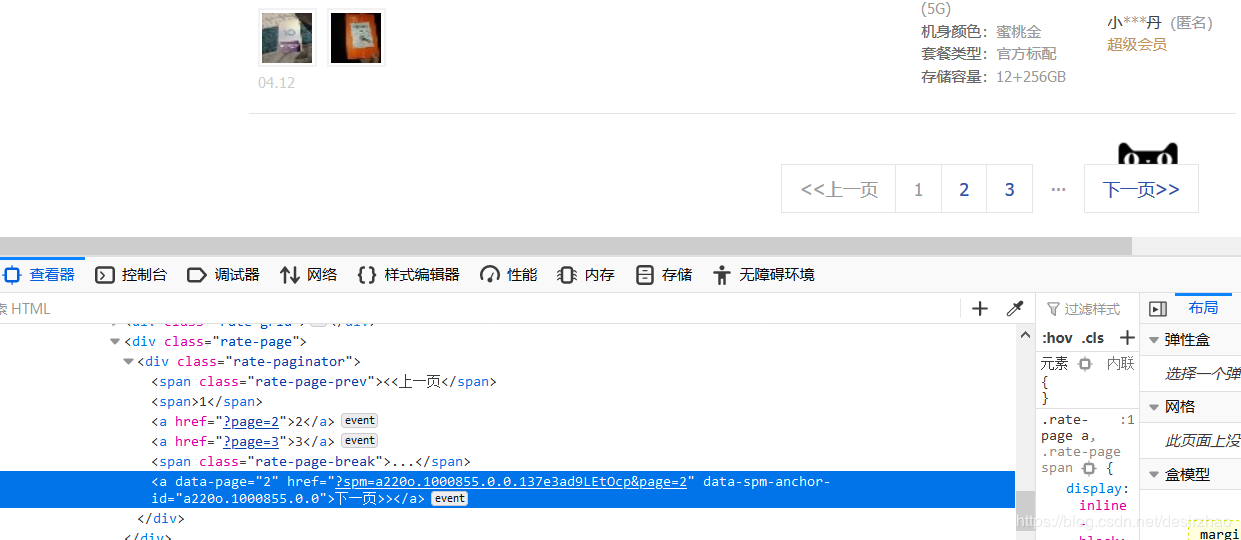
4.2翻页代码如下:
x是页数,初值是6
#翻页,点击下一页
def next_page(x,i):
try:
# 第一页的CSS child(6),第二页的CSS child(7),第六页及以后的CSS 都是child(11),第六页的x是11
if x a:nth-child({})'.format(x)).click()
else :
browser.find_by_css('.rate-paginator > a:nth-child(11)').click()
# 可能出现滑块验证
except ElementDoesNotExist:
#只刷新和点击一次
if i<2:
dispose_slider()
pyautogui.hotkey('f5')
time.sleep(0.25)
click_comment()
time.sleep(0.25)
5、main()函数
def main():
ready_option(url)
time.sleep(0.5)
#点击评论
click_comment()
#爬取n页评论
for i in range(1,10):
print("第{}页".format(i))
get_comment()
x = i+5
time.sleep(0.2)
next_page(x,i)
# 休息0.4秒,表示对淘宝的尊敬
time.sleep(0.4)
#最后退出浏览器
#browser.quit()
三、完整代码及运行视频链接
1、完整代码
1.1 运行的代码约80行。
from splinter.browser import Browser
import pymongo
import pyautogui
import time
from splinter.exceptions import ElementDoesNotExist
from selenium.common import exceptions as ex
url = "https://www.taobao.com"
browser = Browser("firefox",user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0")
#获取评论前的操作
def ready_option(url):
#开始访问
browser.visit(url)
#输入mi10,点击搜索。
browser.find_by_id('q').first.fill('mi10')
browser.find_by_css('.btn-search').click()
#输入账号、密码,点击登录
browser.find_by_id('fm-login-id').first.fill('loginID')
browser.find_by_id('fm-login-password').first.fill('password')
browser.find_by_css('.fm-button').click()
#点击小米官方旗舰店
browser.find_by_css('#J_Itemlist_Pic_611224893062').click()
#上一步会弹出小米官方旗舰店小米10的售卖窗口
#指定到弹出的窗口
window = browser.windows[1]
window.is_current = True
#点击评价
def click_comment():
#不管有没有滑块验证,先划两下
dispose_slider()
dispose_slider()
time.sleep(0.2)
# 点击评价
try:
browser.find_by_css('#J_ItemRates > div:nth-child(1) > span:nth-child(2)').click()
#防止刷新过快,捕获不到 评价 元素
except ElementDoesNotExist:
#有时候滑块验证在拖放滑块后,还需要刷新(按F5)
pyautogui.hotkey('f5')
browser.find_by_css('#J_ItemRates > div:nth-child(1) > span:nth-child(2)').click()
#获取当前页面的评论
def get_comment():
try:
# 获取的comment是一个列表(List)
comment = browser.find_by_css('.rate-grid').find_by_tag('tr')
#遍历,获取每个评论及手机配置
for item in comment:
'''
#直接print
print('评论:' + i.find_by_css('.rate-grid .tm-rate-content').text)
print('配置:'+ i.find_by_css('.rate-sku').text + '\n')
'''
#以字典的形式保存到mongoDB
#评论用父标签.tm-rate-content,如果当前标签 tm-rate-fulltxt会捕获到别的字符
result = {'评论': item.find_by_css('.tm-rate-content').text,
'配置': item.find_by_css('.rate-sku').text}
# 存到mongoDB
save_to_mongo(result)
#可能出现滑块验证
except ElementDoesNotExist or ex.StaleElementReferenceException :
dispose_slider()
#翻页,点击下一页
def next_page(x,i):
try:
# 第一页的CSS child(6),第二页的CSS child(7),第六页及以后的CSS 都是child(11),第六页的x是11
if x a:nth-child({})'.format(x)).click()
else :
browser.find_by_css('.rate-paginator > a:nth-child(11)').click()
# 可能出现滑块验证
except ElementDoesNotExist:
#只刷新和点击一次
if i<2:
dispose_slider()
pyautogui.hotkey('f5')
time.sleep(0.25)
click_comment()
time.sleep(0.25)
#以字典的形式保存到mongoDB
def save_to_mongo(result):
client = pymongo.MongoClient('localhost')
# 指定数据库
db = client['taobao']
try:
if db['product'].insert_one(result):
print('存储到MONGODB成功')
except Exception:
print('存储到MONGODB失败',result)
#滑块验证处理
def dispose_slider():
time.sleep(0.2)
pyautogui.moveTo(x=1080, y=503, duration=0.25)
pyautogui.dragTo(x=1080, y=560, duration=0.5)
time.sleep(0.2)
pyautogui.moveTo(x=660, y=677, duration=0.25)
pyautogui.dragTo(x=1300, y=677, duration=0.8)
#休息0.25秒,表示对淘宝的尊敬
time.sleep(0.25)
def main():
ready_option(url)
time.sleep(0.5)
click_comment()
#爬取n页评论
for i in range(1,10):
print("第{}页".format(i))
get_comment()
x = i+5
time.sleep(0.2)
next_page(x,i)
# 休息0.4秒,表示对淘宝的尊敬
time.sleep(0.4)
#最后退出浏览器
#browser.quit()
if __name__ == '__main__':
main()
2、程序运行视频链接
链接:https://pan.baidu.com/s/1Zx-ZY-7jyWwAIPu6eENKzg
提取码:7gf9
作者:太虚鲲我们走