Spark环境搭建——on yarn集群模式
本篇博客,Alice为大家带来关于如何搭建Spark的on yarn集群模式的教程。
 文章目录准备工作cluster模式client模式[了解]两种模式的区别
官方文档:
http://spark.apache.org/docs/latest/running-on-yarn.html
准备工作
安装启动Hadoop(需要使用HDFS和YARN,已经ok)
安装单机版Spark(已经ok)
注意:不需要集群,因为把Spark程序提交给YARN运行本质上是把字节码给YARN集群上的JVM运行,但是得有一个东西帮我去把任务提交上个YARN,所以需要一个单机版的Spark,里面的有spark-shell命令,spark-submit命令
修改配置:
在spark-env.sh ,添加HADOOP_CONF_DIR配置,指明了hadoop的配置文件的位置
文章目录准备工作cluster模式client模式[了解]两种模式的区别
官方文档:
http://spark.apache.org/docs/latest/running-on-yarn.html
准备工作
安装启动Hadoop(需要使用HDFS和YARN,已经ok)
安装单机版Spark(已经ok)
注意:不需要集群,因为把Spark程序提交给YARN运行本质上是把字节码给YARN集群上的JVM运行,但是得有一个东西帮我去把任务提交上个YARN,所以需要一个单机版的Spark,里面的有spark-shell命令,spark-submit命令
修改配置:
在spark-env.sh ,添加HADOOP_CONF_DIR配置,指明了hadoop的配置文件的位置
 注意:
之前我们使用的spark-shell是一个简单的用来测试的交互式窗口,下面的演示命令使用的是
注意:
之前我们使用的spark-shell是一个简单的用来测试的交互式窗口,下面的演示命令使用的是 查看界面
查看界面
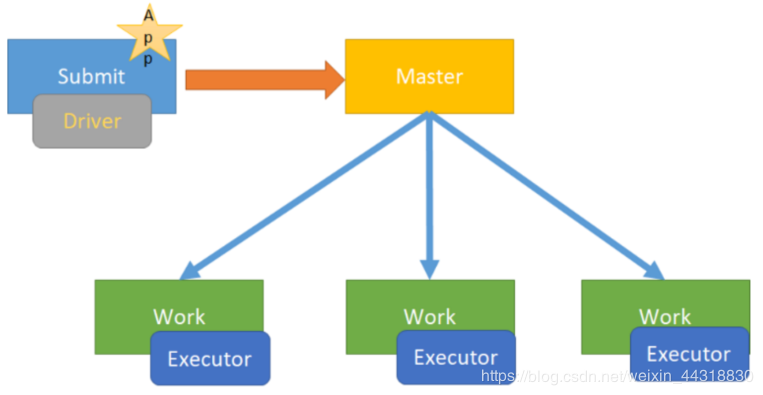
 client模式[了解]
说明
学习测试时使用,开发不用,了解即可
Spark On YARN的Client模式 指的是Driver程序运行在提交任务的客户端
图解
client模式[了解]
说明
学习测试时使用,开发不用,了解即可
Spark On YARN的Client模式 指的是Driver程序运行在提交任务的客户端
图解
 运行示例程序
运行示例程序
 作者:Alice菌
作者:Alice菌
文章目录准备工作cluster模式client模式[了解]两种模式的区别
官方文档:
http://spark.apache.org/docs/latest/running-on-yarn.html
准备工作
安装启动Hadoop(需要使用HDFS和YARN,已经ok)
安装单机版Spark(已经ok)
注意:不需要集群,因为把Spark程序提交给YARN运行本质上是把字节码给YARN集群上的JVM运行,但是得有一个东西帮我去把任务提交上个YARN,所以需要一个单机版的Spark,里面的有spark-shell命令,spark-submit命令
修改配置:
在spark-env.sh ,添加HADOOP_CONF_DIR配置,指明了hadoop的配置文件的位置
vim /export/servers/spark/conf/spark-env.sh
加入下面的声明,把路径改为自己hadoop对应的路径
export HADOOP_CONF_DIR=/export/servers/hadoop/etc/hadoop
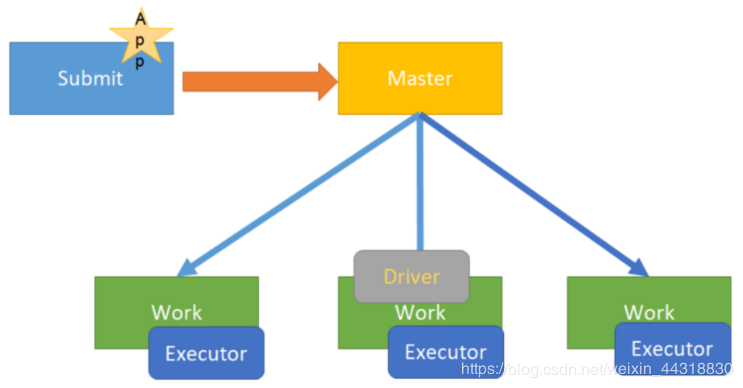
cluster模式
说明
在企业生产环境中大部分都是cluster部署模式运行Spark应用
Spark On YARN的Cluster模式 指的是Driver程序运行在YARN集群上
补充Driver是什么:
The process running the main() function of the application and creating the SparkContext
运行应用程序的main()函数并创建SparkContext的进程
图解
注意:
之前我们使用的spark-shell是一个简单的用来测试的交互式窗口,下面的演示命令使用的是spark-submit用来提交打成jar包的任务
/export/servers/spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue default \
/export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \
10
具体的参数含义,见下图说明。
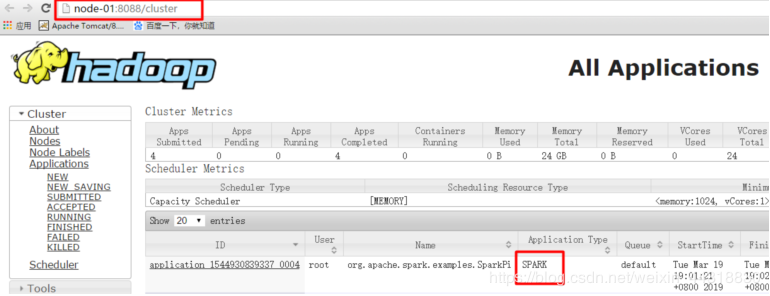
查看界面
http://node01:8088/cluster
client模式[了解]
说明
学习测试时使用,开发不用,了解即可
Spark On YARN的Client模式 指的是Driver程序运行在提交任务的客户端
图解
运行示例程序
/export/servers/spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue default \
/export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \
10
具体参数对应的含义请参照cluster模式。
两种模式的区别
Cluster和Client模式最最本质的区别是:Driver程序运行在哪里!
其中,就直接的区别就是:
运行在YARN集群中就是Cluster模式,
运行在客户端就是Client模式
当然,还有由本质区别延伸出来的区别:
cluster模式:生产环境中使用该模式
1.Driver程序在YARN集群中
2.应用的运行结果不能在客户端显示
3.该模式下Driver运行ApplicattionMaster这个进程中,
如果出现问题,yarn会重启ApplicattionMaster(Driver)
client模式:
1.Driver运行在Client上的SparkSubmit进程中
2.应用程序运行结果会在客户端显示
本次的分享就到这里,受益的小伙伴或对大数据技术感兴趣的朋友记得点赞关注Alice哟(^U^)ノ~YO
作者:Alice菌