Spark RDD编程
RDD概述
RDD既弹性分布式数据集,是Spark主要的编程抽象
RDD作为数据结构,本质上是一个只读的分区(partition)记录集合
一个RDD可以包含多个分区,每个分区就是一个dataset片段
RDD编程接口
Spark中提供了通用接口来抽象RDD,具体包括以下四个方面:
分区信息,是数据集的最小分片
依赖关系,指向欺负RDD
函数,基于父RDD的计算方法
划分策略和数据位置的元数据

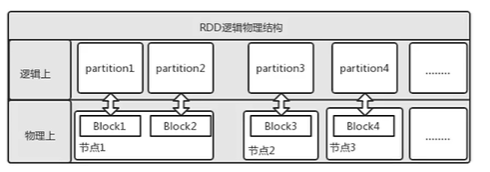
RDD分区
分区目的:减少网络传输的代价以提高系统的性能
利用Partitions方法可获取RDD划分的分区数
RDD分区分布在集群的节点中,分区数量一定程序就决定了任务的并行的数量
从HDFS文件创建RDD,分区数默认为文件的Block数
RDD首选位置
Spark会尽可能地把计算分配到靠近数据的位置
RDD的分区计算
Spark中RDD的计算以分区为单位,mapPartition等操作可以进行分区计算
RDD的分区函数
Spark中默认提供两种划分器:哈希分区划分器和范围分区划分器。且Partitioner只存在于(K,V)类型的RDD中
RDD Lineage
Spark通过Lineage来记录不同RDD之间演变的关系
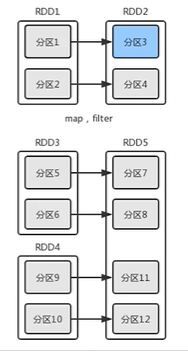
RDD依赖关系:窄依赖
Map、filter、union操作属于窄依赖
窄依赖表现为每个父RDD的分区最多都只会被一个子RDD所用
若分区3的数据丢失,只需要重新计算分区1的数据,丢失数据后恢复快
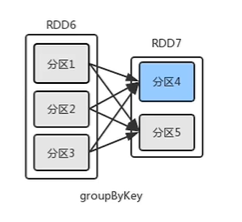
RDD依赖关系:宽依赖
groupByKey()操作属于宽依赖
宽依赖表现为多个子RDD的分区依赖于一个父RDD的分区
若分区4的数据丢失,需要重新计算分区1、2、3的数据,与窄依赖相比,丢失数据后恢复慢
创建RDD
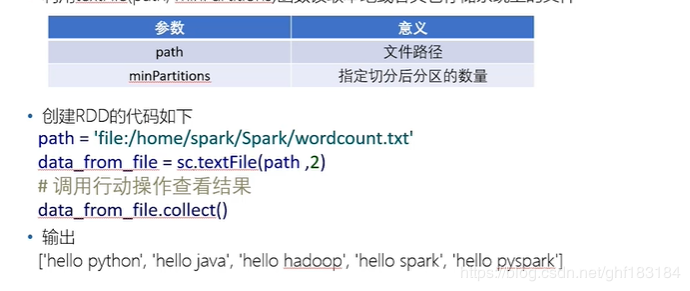
方式一:读取外部数据集
利用textFile(path,minPartitions)函数读取本地或者其他存储系统上的文件
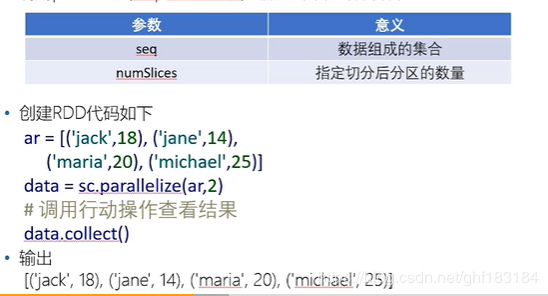
方式二:并行化集合
利用parallelize(seq,numSlices)函数对集合进行并行化
RDD操作
RDD支持两种操作:
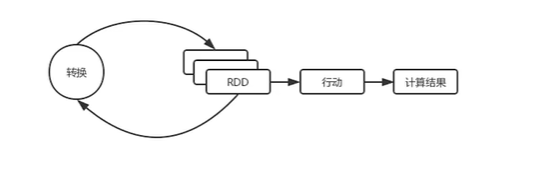
转换操作:转化操作接受RDD返回新的RDD。转化操作是惰性操作,遇到行动操作才会执行
行动操作:行动操作接受RDD返回计算结果
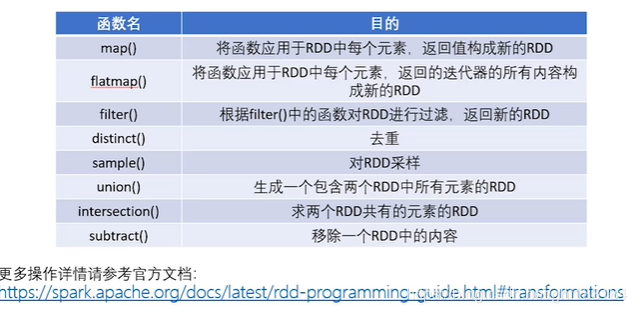
常见的RDD转化操作:
RDD操作练习


Pair RDD
Pair RDD概述:
Pair RDD既键值对RDD,通常用来进行聚合计算
Pair RDD可使用所有标准RDD上的可用的转换和行动操作
使用map函数创建Pair RDD
line = sc.parallelize([“hello world”,”very good”])
Map = line.map(lambda s:(s.split(“”)[0],s))
查看Pair RDD的key和value值
Print(map.keys().collect())
Print(map.values().collect())
运行结果
[‘hello’,’very’]
[‘hello world’,’very good’]
常见的Pair RDD转化操作
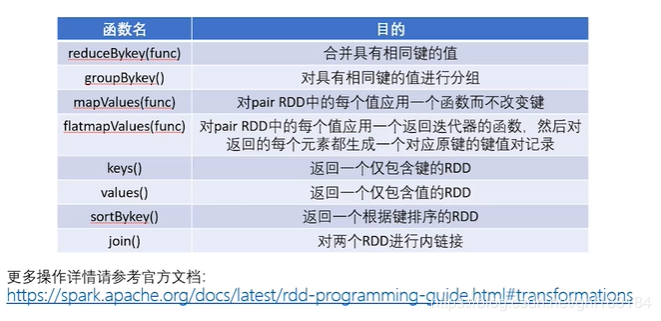
常见的pair RDD行动操作:

Pair RDD操作练习

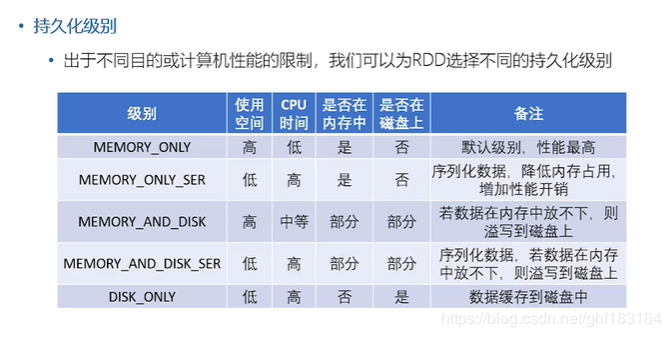
RDD持久化

作者:挽歌亽朽年