Spark的Yarn模式
Spark基础理论: https://blog.csdn.net/weixin_45102492/article/details/104318250
Spark安装及Local模式:https://blog.csdn.net/weixin_45102492/article/details/104318738
Spark的Standalone模式: https://blog.csdn.net/weixin_45102492/article/details/104319485
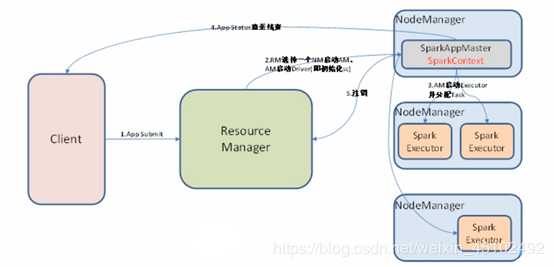
Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster(集群模式,工作中常用)两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适应于交互、调试,希望立即看到app的输出
yarn-cluster:Driver程序运行在由RM(ResourceManager)启动的AP(APPMaster)适用于生产环境。
修改yarn-site.xml文件
添加以下内容
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
修改spark-env.sh文件
添加下面配置
YARN_CONF_DIR=/opt/module/Hadoop/hadoop-2.7.7/etc/hadoop
执行官方PI案例
[root@node01 spark-3.0.0-preview2-bin-hadoop2.7]# bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0-preview2.jar \
100
执行spark-shell
[root@node01 spark-3.0.0-preview2-bin-hadoop2.7]# bin/spark-shell --master yarn
20/02/14 11:27:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
20/02/14 11:27:28 WARN util.Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
20/02/14 11:27:30 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Spark context Web UI available at http://node01:4041
Spark context available as 'sc' (master = yarn, app id = application_1581648909274_0003).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-preview2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
日志查看
Spark做计算Yarn做资源调度,中间的日志看不到,可以做以下修改,修改配置文件spark-defaulys.conf
添加以下内容
#把spark的运行日志传到hadoop中 用web访问8088端口方便查看日志
spark.yarn.historyServer.address=node01:18080
spark.history.ui.port=18080
重启spark历史服务
[root@node01 spark-3.0.0-preview2-bin-hadoop2.7]# sbin/stop-history-server.sh
[root@node01 spark-3.0.0-preview2-bin-hadoop2.7]# sbin/start-history-server.sh
Yarn运行模式图解
IDEA打包程序到集群
在idea的pom文件中添加
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
WordCount
jar-with-dependencies
make-assembly
package
single
然后利用maven的package打包
在打包前要注意输入路径要修改为file:///opt/module/Spark/spark-3.0.0-preview2-bin-hadoop2.7/input否则会在yarn下找路径
把WordCount-jar-with-dependencies.jar上传到集群(我在spark下创建了一个job来存放jar包)
提交任务
bin/spark-submit /
--class com.zut.bigdata.spark.WordCount /
./job/WordCount-jar-with-dependencies.jar
作者:hykDatabases