Spark(Streaming)写入数据到hdfs__saveAsHadoopFile以及自定义MultipleOutputFormat
目录
一、理论依据
1、说明
2、saveAsHadoopFile算子
(1)形式
(2)解析说明
(3)MultipleOutputFormat
二、代码实例
1、SparkSaveAsHadoopFiles
2、自定义RDDMultipleTextOutputFormat
三、打包运行
1、运行
2、结果展示
四、在sparkStreaming中如何使用saveAsHadoopFile
1、代码
2、说明
一、理论依据 1、说明在spark实际项目应用中,总会牵涉到数据的存储问题。如果选择将spark分析好的数据存储到hdfs上,则必定会用到saveAsHadoopFile方法和自定义MultipleOutputFormat类;
2、saveAsHadoopFile算子 (1)形式
def saveAsHadoopFile(
path: String,
keyClass: Class[_],
valueClass: Class[_],
outputFormatClass: Class[_ <: OutputFormat[_, _]],
conf: JobConf = new JobConf(self.context.hadoopConfiguration),
codec: Option[Class[_ <: CompressionCodec]] = None): Unit
(2)解析说明
这个算子里需要传入的参数依次是:文件路径、key类型、value类型、outputFormat方式。
saveAsHadoopFile算子属于org.apache.spark.rdd.PairRDDFunctions类,需要接收的参数是PairRDD,所以我们在使用前需要将原来的rdd做一下map操作,变成(key, value) 形式。
我们暂且定(K,V)类型为classOf[String]、classOf[String],再之后传入hdfs保存目录、类型,剩下的就是关键的需要传入OutputFormat。
path(hdfs保存路径可以已存在也可以不存在,事先不存在则会自己随着程序运行时创建)
(3)MultipleOutputFormat
自定义MultipleOutputFormat并且重写 override def generateFileNameForKeyValue(key: Any, value: Any, name: String):String方法可以按照自己设计的目录级别和文件名进行数据存储;
参数里的name就是原始的 part-00000,part-00001……
二、代码实例
1、SparkSaveAsHadoopFiles
package main.scala.com.cn.spark
import com.cn.spark.RDDMultipleTextOutputFormat
import org.apache.spark.{SparkConf, SparkContext}
object SparkSaveAsHadoopFiles {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("saveAsHadoopFiles").setMaster("local[2]")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(List("0,00000,Aa,2019-02-11 03:20:06",
"1,11111,Bb,2019-03-12 04:25:22",
"2,22222,Cc,2019-04-14 05:26:33",
"3,33333,Dd,2019-05-15 06:29:44"
))
//saveAsHadoopFile需要的是pairRDD,因此,我们使用map将数据转换一下,数据内容作为key,空串“”作为value
val rdd1 = rdd.map(s=>(s,""))
rdd1.repartition(2)
.saveAsHadoopFile("/hyj/myhadoop/", classOf[String],
classOf[String],classOf[RDDMultipleTextOutputFormat])
}
}
2、自定义RDDMultipleTextOutputFormat
package com.cn.spark
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat
class RDDMultipleTextOutputFormat extends MultipleTextOutputFormat[Any,Any]{
private val HOURFORMAT = new SimpleDateFormat("HH-mm-ss")
private val start_time = System.currentTimeMillis()
private val curDay=new Date(start_time)
private val fileName=HOURFORMAT.format(curDay)
//name:part-00000,part-00001
override def generateFileNameForKeyValue(key: Any, value: Any, name: String):String ={
//"1,11111,Bb,2019-03-12 04:25:22"
val line=key.toString
//提取2019-03-12 04:25:22
val time=line.split(",")(3)
val date=time.substring(0,time.indexOf(" "))//2019-03-02
val hour=time.substring(time.indexOf(" ")+1,time.indexOf(":"))//04
val resultDir=date+"/"+hour+"/"+fileName+"_"+name.substring(name.length-2)
resultDir
}
}
三、打包运行
1、运行
[root@master bin]# ./spark-submit --master local[*] --class main.scala.com.cn.spark.SparkSaveAsHadoopFiles /home/test/sparkSysLearn_jar/sparkSysLearn.jar
注意:--class 后面的参数,根据SparkSaveAsHadoopFiles类上面的 package main.scala.com.cn.spark定。
2、结果展示
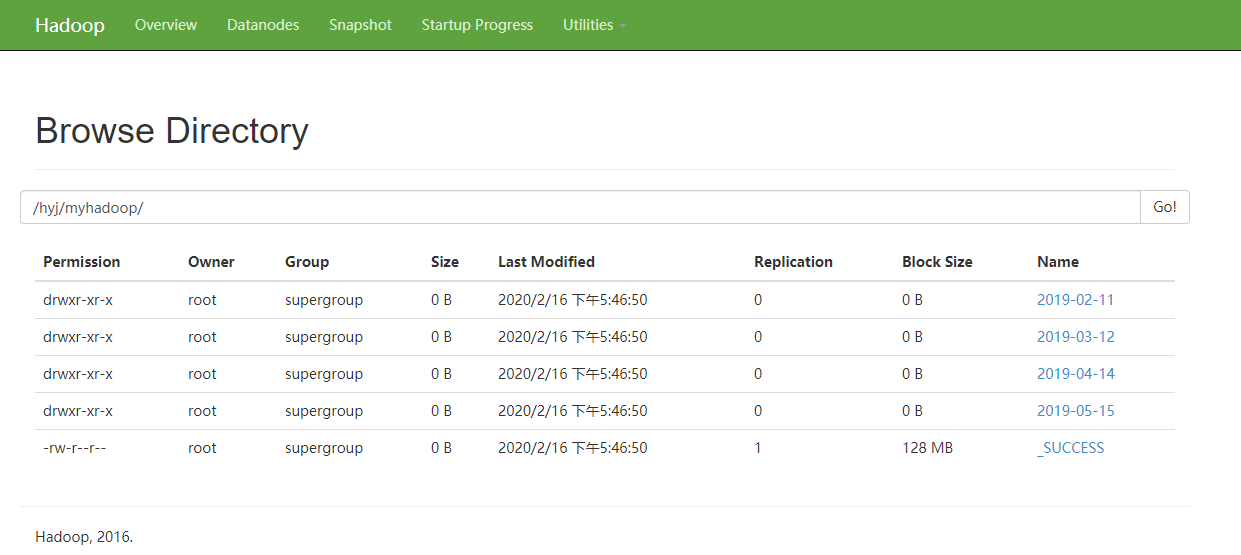



四、在sparkStreaming中如何使用saveAsHadoopFile
1、代码
//...部分内容
saveDstream.foreachRDD(rdd => {
val start_time = System.currentTimeMillis()
if (rdd.isEmpty) {
logInfo(" No Data in this batchInterval --------")
} else {
//这里,因为saveAsHadoopFile需要接受pairRDD,所以用map转换一下
val a: RDD[(String, String)] =rdd.map(x=>(x,""))
a.saveAsHadoopFile(hdfsPath+"/", classOf[String], classOf[String],classOf[RDDMultipleTextOutputFormat])
}
})//foreachRDD
//...
2、说明
在实时流中使用,最终也是将DStream先转化为一个个RDD,再调用saveAsHadoopFile函数存储,思想和上面一样;
作者:时不我待,一日千里