Spark RDD详解
Spark与Apache Hadoop有何关系?
Spark是与Hadoop数据兼容的快速通用处理引擎。它可以通过YARN或Spark的Standalone在Hadoop集群中运行,并且可以处理HDFS、Hbase、Cassandra、Hive和任何Hadoop InputFormat中的数据。它旨在执行批处理(类似于MapReduce)和提供新的工作特性,例如流计算,SparkSQL交互式查询和Machine Learning机器学习等。
我的数据需要容纳在内存中才能使用Spark吗?
不会。Spark的operators会在不适合内存的情况下将数据溢出到磁盘上,从而使其可以在任何大小的数据上正常运行。同样,由RDD(弹性分布式数据集合)的存储级别决定,如果内存不足,则缓存的数据集要么溢出到磁盘上,要么在需要时及时重新计算。
http://spark.apache.org/fag.html
Spark RDD详解
总体上看Spark,每个Spark应用程序都包含一个Driver,该Driver程序运行用户的main方法并在集群上执行各种并行操作。Spark提供的主要抽象概念,是弹性分布式数据集(RDD resilient distributed dataset),它是跨集群 分布式的元素的集合,可以并行操作。
RDD可以通过从Hadoop文件系统(或任何其他Hadoop支持的文件系统)中的文件或驱动程序中现有的Scala集合开始并进行转换来创建RDD,然后调用RDD算子实现对RDD的转换运算。用户还可以要求Spark将RDD持久存储在内存中,从而使其可以在并行操作中高效地重复使用。最后,RDD会自动从节点故障中恢复。
开发环境 导入Maven依赖
org.apache.spark
spark-core_2.11
2.4.5
org.apache.hadoop
hadoop-client
2.9.2
Scala编译插件
net.alchim31.maven
scala-maven-plugin
4.0.1
scala-compile-first
process-resources
add-source
compile
打包fat jar插件
org.apache.maven.plugins
maven-shade-plugin
2.4.3
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
JDK编译版本插件(可选)
org.apache.maven.plugins
maven-compiler-plugin
3.2
1.8
1.8
UTF-8
compile
compile
Driver编写
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
// Driver
def main(args: Array[String]): Unit = {
//创建sc
val conf = new SparkConf()
.setMaster("spark://10.15.0.34:7077")
.setAppName("WordCount")
val sparkContext = new SparkContext(conf)
//创建RDD - 细化
val linesRdd:RDD[String] = sparkContext.textFile("hdfs:///demo/word")
//RDD-RDD 转换 lazy 并行的 - 细化
var resultRDD:RDD[(String,Int)]=linesRdd.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.reduceByKey((v1,v2)=>v1+v2)
//RDD -> Unit或者本地集合Array|List 动作转换 触发job执行
val resultArray:Array[(String,Int)] = resultRDD.collect()
//Scala本地集合运算和Spark脱离关系
resultArray.foreach(t=>println(t._1+"->"+t._2))
//关闭sc
sparkContext.stop()
}
}
使用maven package进行打包,将fatjar上传到CentOS
使用spark-submit提交任务
[root@train spark-2.4.5]# ./bin/spark-submit
--master spark://train:7077
--deploy-mode client
--class com.baizhi.sparkwordcount.WordCount
--total-executor-cores 6 /root/spark-WordCount-1.0-SNAPSHOT.jar
Spark提供了本地测试的方法
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
// Driver
def main(args: Array[String]): Unit = {
//创建sc
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
val sparkContext = new SparkContext(conf)
//创建RDD - 细化
val linesRdd:RDD[String] = sparkContext.textFile("hdfs://10.15.0.34:9000/demo/word")
//RDD-RDD 转换 lazy 并行的 - 细化
var resultRDD:RDD[(String,Int)]=linesRdd.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.reduceByKey((v1,v2)=>v1+v2)
//RDD -> Unit或者本地集合Array|List 动作转换 触发job执行
val resultArray:Array[(String,Int)] = resultRDD.collect()
//Scala本地集合运算和Spark脱离关系
resultArray.foreach(t=>println(t._1+"->"+t._2))
//关闭sc
sparkContext.stop()
}
}
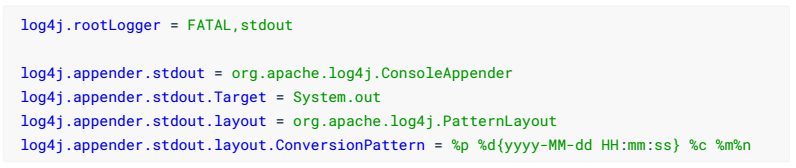
需要resource导入log4j.poperties

Spark围绕弹性分布式数据集(RDD)的概念展开,RDD是一个具有容错特性且可并行操作的元素集合。创建RDD的方法有两种:1.可以在Driver并行化现有的Scala集合(在本身Scala中操作) 2.引用外部存储系统(例如共享文件系统,HDFS、HBase或提供Hadoop InputFormat的任何数据源)中的数据集(也就是利用spark RDD读取外部数据)。
通过在Driver程序中的现有集合(Scala Seq)上调用SparkContext的parallelize或者makeRDD方法来创建并行集合。复制集合的元素以形成可以并行操作的分布式数据集。例如,一下是创建包含数字1到5的并行化集合的方法:
scala> val data = Array(1,2,3,4,5)
data: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val disData = sc.parallelize(data)
disData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at :26
并行集合的可以指定一个分区参数,用于指定计算的并行度。Spark集群为每个分区运行一个任务。当用户不指定分区的时候,sc会根据系统分配到的资源自动做分区。例如:
[root@train spark-2.4.5]# ./bin/spark-shell --master spark://train:7077 --total-executor-cores 6
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://train:4040
Spark context available as 'sc' (master = spark://train:7077, app id = app-20200218002327-0003).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information.
系统会自动在并行化集合的时候,指定分区数为6.用户也可以手动指定分区数。
scala> val disData = sc.parallelize(data,10)
disData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at :26
scala> disData.getNumPartitions
res0: Int = 10
External Datasets(外部数据集)
Spark可以从Hadoop支持的任何存储源创建分布式数据集,包括您的本地文件系统,HDFS、HBase、Amazon S3、RDBMS等。
本地文件系统scala> sc.textFile("file:///root/data/word").collect
res1: Array[String] = Array("this is demo ", haha haha, hello hello yes, good good study, day day up)
读HDFStextFile
会将文件转换为RDD[String]集合对象,每一行文件表示RDD集合中的一个元素
scala> sc.textFile("hdfs:///demo/word").collect
res3: Array[String] = Array("this is demo ", haha haha, hello hello yes, good good study, day day up)
该参数也可以指定分区数,但是需要分区数>=文件系统数据库的个数,所以一般在不知道的情况下,用户可以省略不给。
wholeTextFiles
会将文件转换为RDD[(String,String)]集合对象,RDD中每一个元组元素表示一个文件。其中_1表示文件名,_2表示文件内容
scala> sc.wholeTextFiles("hdfs:///demo/word").collect
res4: Array[(String, String)] =
Array((hdfs://train:9000/demo/word,"this is demo
haha haha
hello hello yes
good good study
day day up
"))
scala> sc.wholeTextFiles("hdfs:///demo/word").map(t=>t._2).flatMap(context=>context.split("\n")).collect
res5: Array[String] = Array("this is demo ", haha haha, hello hello yes, good good study, day day up)
newAPI HadoopRDD
MySQL
mysql
mysql-connector-java
5.1.38
object APIMySQL {
//Driver
def main(args: Array[String]): Unit = {
//创建sc
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("APIMySQL")
val sc = new SparkContext(conf)
val hadoopConfig = new Configuration()
DBConfiguration.configureDB(hadoopConfig, //配置数据库的链接参数
"com.mysql.jdbc.Driver",
"jdbc:mysql://localhost:3306/files",
"root",
"123"
)
//设置查询相关属性
hadoopConfig.set(DBConfiguration.INPUT_QUERY,"select id,name,password from user")
hadoopConfig.set(DBConfiguration.INPUT_COUNT_QUERY,"select count(id) from user")
hadoopConfig.set(DBConfiguration.INPUT_CLASS_PROPERTY,"com.baizhi.newapihadoopadd.UserDBWritable")
//通过Hadoop提供的InputFormat读取外部数据源
val jdbcRDD:RDD[(LongWritable,UserDBWritable)] = sc.newAPIHadoopRDD(
hadoopConfig, //hadoop配置信息
classOf[DBInputFormat[UserDBWritable]], //输入格式类
classOf[LongWritable],//Mapper读入的Key类型
classOf[UserDBWritable] //Mapper读入的Value类型
)
jdbcRDD.map(t=>(t._2.id,t._2.name,t._2.password))
.collect() //动作算子 远程数据 拿到 Driver端 一般用于小批量数据测试
.foreach(t=>println(t))
/*jdbcRDD.foreach(t=>println(t)) //动作算子 远端执行 ok 不会出现序列化问题*/
//jdbcRDD.collect().foreach(t=>println(t)) 因为UserDBWritable、LongWritable都没法序列化 error
//关闭sc
sc.stop()
}
}
class UserDBWritable extends DBWritable{
var id:Int = _
var name:String = _
var password:String = _
//主要用于DBOutputFormat, 因为使用的是读取,该方法可以忽略
override def write(preparedStatement: PreparedStatement): Unit = ???
//在使用DBInputFormat,需要将读取的结果集封装给成员属性
override def readFields(resultSet: ResultSet): Unit = {
id = resultSet.getInt("id")
name = resultSet.getString("name")
password = resultSet.getString("password")
}
}
Hbase
org.apache.hadoop
hadoop-auth
2.9.2
org.apache.hbase
hbase-client
1.2.4
org.apache.hbase
hbase-server
1.2.4
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HConstants
import org.apache.hadoop.hbase.client.{Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.protobuf.ProtobufUtil
import org.apache.hadoop.hbase.util.{Base64, Bytes}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object APIHbase {
//Driver
def main(args: Array[String]): Unit = {
//创建sc
val conf = new SparkConf().setMaster("local[*]")
.setAppName("APIHbase")
val sc = new SparkContext(conf)
val hadoopConf = new Configuration()
//hbase链接参数
hadoopConf.set(HConstants.ZOOKEEPER_QUORUM,"train")
hadoopConf.set(TableInputFormat.INPUT_TABLE,"baizhi:t_user")
//构建查询项
val scan = new Scan()
val pro = ProtobufUtil.toScan(scan)
hadoopConf.set(TableInputFormat.SCAN,Base64.encodeBytes(pro.toByteArray))
val hbaseRDD:RDD[(ImmutableBytesWritable,Result)] = sc.newAPIHadoopRDD(
hadoopConf,//hadoop配置
classOf[TableInputFormat],//输入格式
classOf[ImmutableBytesWritable],//Mapper key类型
classOf[Result] //Mapper Value类型
)
hbaseRDD.map(t=>{
val rowKey = Bytes.toString(t._1.get())
val result = t._2
val name = Bytes.toString(result.getValue("cf1".getBytes(),"name".getBytes()))
(rowKey,name)
}).foreach(t=>println(t))
//关闭sc
sc.stop()
}
}
作者:丿沐染烟忱丶