搜狗疫情数据爬取(R语言)
想必大家最近都很关心新冠状肺炎,疫情导致春节被延长,高速被封,大家伙基本都是远程办公。
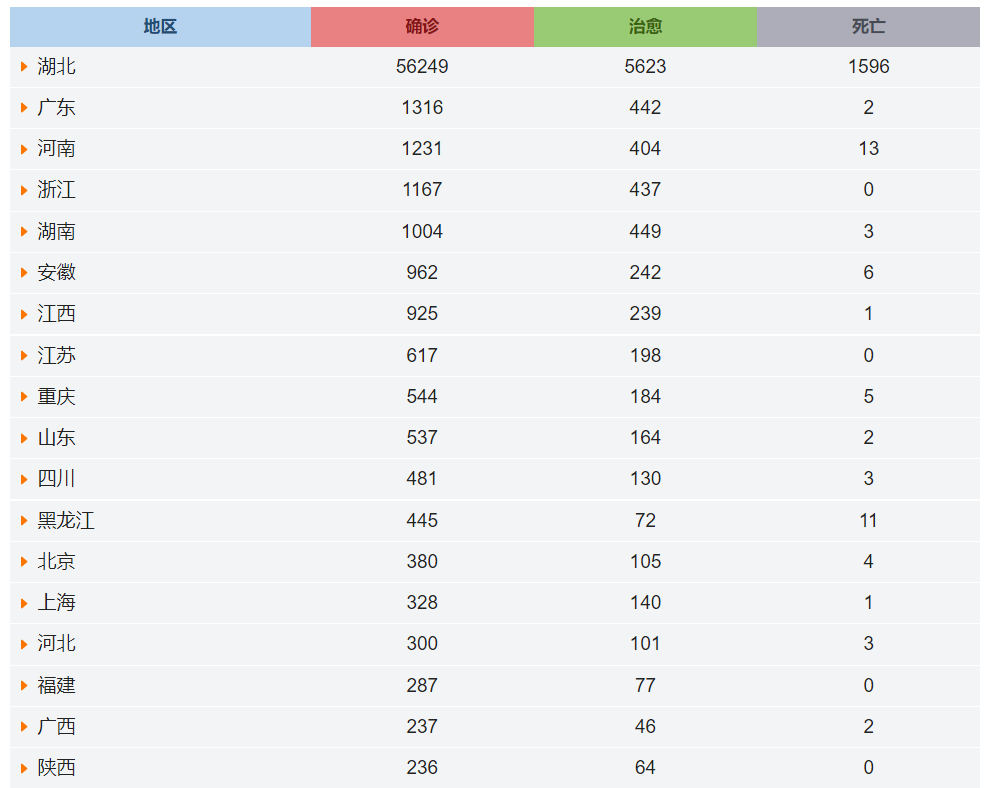
趁着周末,来写个爬虫,获取搜狗疫情提供的数据,爬取各个省份以及各个市区的确诊、治愈和死亡数据。
1581827981508.png
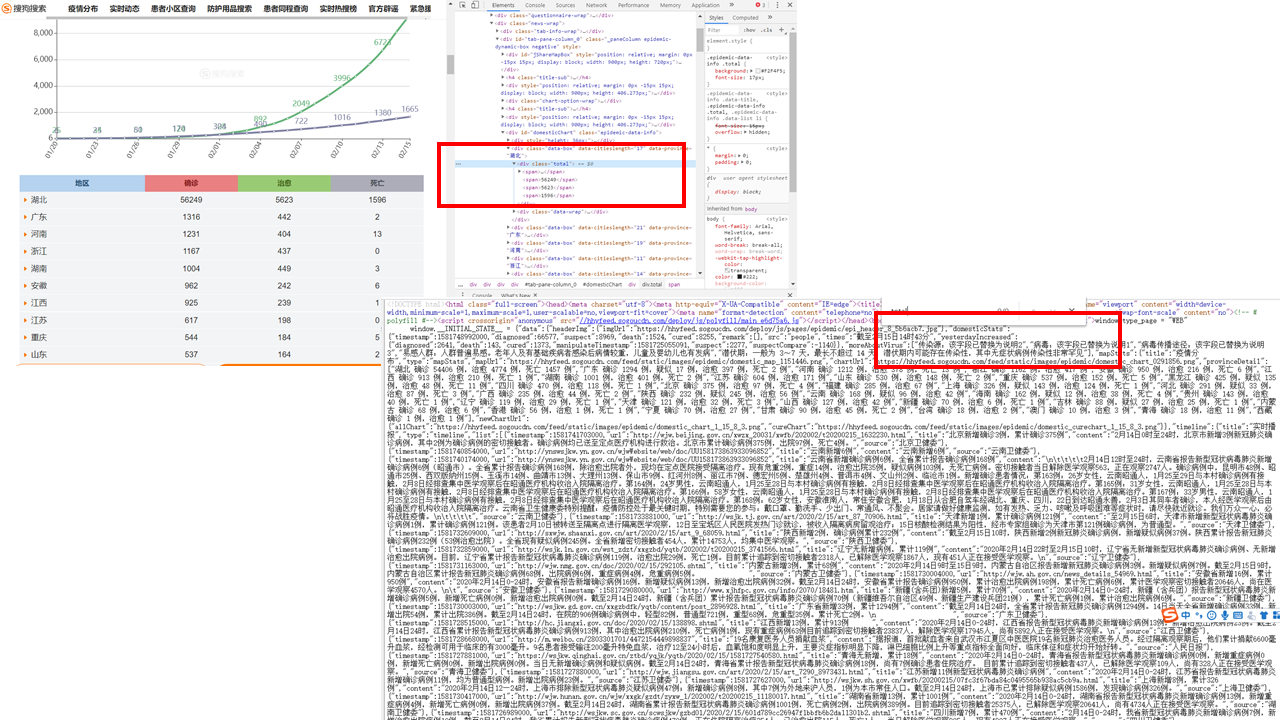
网页分析网页地址为:http://sa.sogou.com/new-weball/page/sgs/epidemic?type_page=WEB,在分析网页时,如果在这里使用浏览器的检查功能,根据标签来写xpath,是无法爬取到数据的。如下图,湖北的数据在div.total标签里面,但在源代码中无法搜索到。而且,read_html是获取网页源码,因此如果根据该标签获取数据,结果肯定为空。
1581829059936.png
如果仔细研究一下源码,会发现所有数据都在,所以xpath=/html/body/script[1]/text()。
library(rvest)
library(rjson)
url<-"http://sa.sogou.com/new-weball/page/sgs/epidemic?type_page=WEB"
page<-read_html(url)
html_dt%html_nodes(xpath="//html/body/script[1]/text()")%>%html_text(trim = TRUE)
数据抽取
如果对html_dt数据查看一下,数据很规整,都是json格式,数据如下(由于数据较多,中间已删除部分),其中包括各个省、市、其他国家的确诊疑似数据以及相关新闻报道。
> html_dt
[1] "window.type_page = \"WEB\"\n window.__INITIAL_STATE__ = {\"data\":{\"headerImg\":{\"imgUrl\":\"https://hhyfeed.sogoucdn.com/deploy/js/pages/epidemic/epi_header_8_5b6acb7.jpg\"},\"domesticStats\":{\"timestamp\":1581824835000,\"diagnosed\":68584,\"suspect\":8228,\"death\":1666,\"cured\":9546,\"remark\":[],\"src\":\"people\",\"times\":\"截至2月16日12时42分\",\"yesterdayIncreased\":{\"diagnosed\":2009,\"death\":142,\"cured\":1323,\"manipulateTimestamp\":1581814971840,\"suspect\":1918,\"suspectCompare\":-741}},\"moreAboutVirus\":[\"传染源:该字段已替换为说明2\",\"病毒:该字段已替换为说明1\",\"病毒传播途径:该字段已替换为说明3\",\"易感人群:人群普遍易感。老年人及有基础疾病者感染后病情较重,儿童及婴幼儿也有发病\",\"潜伏期:一般为 3~7 天,最长不超过 14 天,潜伏期内可能存在传染性,其中无症状病例传染性非常罕见\"],\"mapStats\":{\"title\":\"疫情分布\",\"type\":\"mapStats\",\"mapUrl\":\"https://hhyfeed.sogoucdn.com/feed/static/images/epidemic/domestic_map_1161231.png\",\"chartUrl\":\"https://hhyfeed.sogoucdn.com/feed/static/images/epidemic/domestic_chart_0291856.png\",\"provinceDetail\":[\"湖北 确诊 56249 例,治愈 5623 例,死亡 1596 例\",\"广东 确诊 1316 例,疑似 17 例,治愈 444 例,死亡 2 例\",\"河南 确诊 1231 例,治愈 421 例,死亡 13 例\"],\"newChartUrl\":
\"source\":\"上观新闻\",\"img\":\"[\\\"http://img01.sogoucdn.com/app/a/200883/ca798fc52ff9aded400dd38000590f3c\\\"]\",\"up_time\":\"2020-02-11 08:06:08\"},{\"url\":\"http://sa.sogou.com/sgsearch/sgs_tc_news.php?req=N8k_v32bO0luMYPaVIhIMgc10T75IF3Atfo-NQa_zOY=\",\"title\":\"辟谣 | 宁波驰援湖北医疗人员物资没收到被扣留?真相来了\",\"source\":\"湖北日报\",
\"area\":[{\"provinceName\":\"湖北\",\"provinceShortName\":\"湖北\",\"currentConfirmedCount\":49030,\"confirmedCount\":56249,\"suspectedCount\":0,\"curedCount\":5623,\"deadCount\":1596,\"comment\":\"\",\"locationId\":420000,\"cities\":[{\"cityName\":\"武汉\",\"confirmedCount\":39462,\"suspectedCount\":0,\"curedCount\":2915,\"deadCount\":1233},{\"cityName\":\"孝感\",\"confirmedCount\":3201,\"suspectedCount\":0,\"curedCount\":353,\"deadCount\":65},
[{\"id\":181447,\"createTime\":1581824835000,\"modifyTime\":1581824835000,\"tags\":\"\",\"countryType\":2,\"continents\":\"亚洲\",\"provinceId\":\"6\",\"provinceName\":\"日本\",\"provinceShortName\":\"\",\"cityName\":\"\",\"currentConfirmedCount\":395,\"confirmedCount\":408,\"suspectedCount\":0,\"curedCount\":2,\"deadCount\":1,\"comment\":\"\",\"sort\":0,\"operator\":\"wangjinyuan\",\"locationId\":951002}}"
对于json数据处理,这里推荐rjson包,处理起来十分方便。
#数据前面包含的这些字符不是josn格式,所以需要用正则表达式删除
json<-sub('window.type_page = \"WEB\"\n window.__INITIAL_STATE__ = ',"",html_dt)
#通过rjson包中的fromJSON,可以将数据转换为list格式
josn_date<-fromJSON(json)
#在对josn_date数据分析,省份与各个市区的数据在josn_date$data$area中
area<-josn_date$data$area
# 省 市 确诊 疑似 治愈 死亡
citytempdate<-c()
provincetempdate<-c()
for (i in area) {
provinceShortName<-i$provinceShortName
confirmedCount<-i$confirmedCount
curedCount<-i$curedCount
deadCount<-i$deadCount
#首先获取省份数据
provincetempdate<-c(c(provinceShortName,confirmedCount,curedCount,deadCount),provincetempdate)
for (j in i$cities) {
cityName<-j$cityName
confirmedCount=j$confirmedCount
curedCount=j$curedCount
deadCount=j$deadCount
#获取该省份下所有市区的数据
citytempdate<-c(c(provinceShortName,cityName,confirmedCount,curedCount,deadCount),citytempdate)
}
}
#各个地区确诊人数、治愈人数、死亡人数 dt_city
dt_city<-data.frame(matrix(citytempdate,ncol=5,byrow=TRUE))
colnames(dt_city)<-c("PROVINCESHORTNAME","CITYNAME","CONFIRMEDCOUNT","CUREDCOUNT","DEADCOUNT")
#dt_province,省份数据
dt_province<-data.frame(matrix(provincetempdate,ncol=4,byrow=TRUE))
colnames(dt_province)<-c("PROVINCESHORTNAME","CONFIRMEDCOUNT","CUREDCOUNT","DEADCOUNT")
现在就把省和市区的数据爬取到了,具体如下,
head(dt_province)
PROVINCESHORTNAME CONFIRMEDCOUNT CUREDCOUNT DEADCOUNT
1 西藏 1 1 0
2 澳门 10 3 0
3 青海 18 13 0
4 台湾 18 2 0
5 香港 56 1 1
6 宁夏 70 33 0
> head(dt_city)
PROVINCESHORTNAME CITYNAME CONFIRMEDCOUNT CUREDCOUNT DEADCOUNT
1 西藏 拉萨 1 1 0
2 青海 海北州 3 2 0
3 青海 西宁 15 11 0
4 宁夏 宁东管委会 1 1 0
5 宁夏 石嘴山 1 1 0
6 宁夏 中卫 3 3 0
数据存储
我们现在爬取的数据只有当天的数据,如果要做更多的分析,肯定是要把数据存储,当有一定时间长度时,才能有效的进行分析。这里有两个方法,一个是存储在文件中,另外一个是存储在数据库中。
#这里比较推荐readr包中的write_csv
write.csv(dt_city,"epidemic_city20200216.csv")
write.csv(dt_province,"epidemic_province20200216.csv")
现在我就把数据存储在MySQL数据库中,具体代码如下:
#数据保存至数据库
library(RMySQL)
library(RMariaDB)
#连接数据
con <- dbConnect(MariaDB(), host="127.0.0.1", dbname="epid", user="root", password="1234")
#在数据库中,我添加了日期字段,在后续分析时,可以根据该字段查询具体每天数据。
city<-data.frame(dt_city,DT=c(format(Sys.Date(),"%Y%m%d")))
province<-data.frame(dt_province,DT=c(format(Sys.Date(),"%Y%m%d")))
# 插入数据库
dbWriteTable(con,"city_dt",city,overwrite =FALSE,append=TRUE,row.names=FALSE)
dbWriteTable(con,"province_dt",province,overwrite =FALSE,append=TRUE,row.names=FALSE)
总结
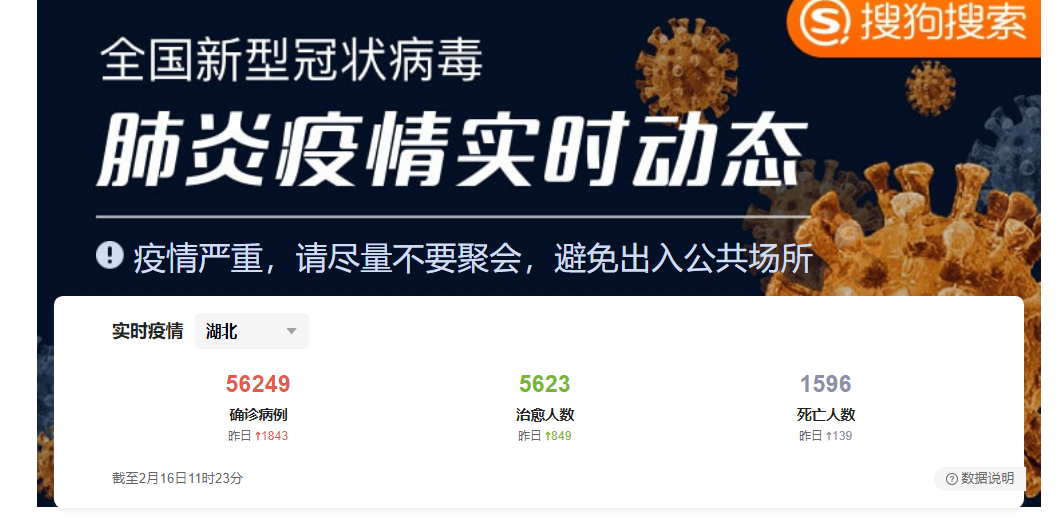
通过该网页,还可以爬取其他国家的确诊人数、治愈人数和死亡人数,以及下图所示的昨日数据,还可以获取官方辟谣、紧急援助的新闻名称和连接。感兴趣的小伙伴可去尝试一下。
本文所涉及的代码、数据库建表脚本以及数据,均已上传至GitHub,点击阅读原文即可获取。
1581839056576.png
转载请注明:
微信公众号:数据志
简书:数据志
博客园:https://www.cnblogs.com/wheng/
CSDN:https://blog.csdn.net/wzgl__wh
作者:王亨