机器学习(1)——获取数据及数据预处理
机器学习教计算机执行人和动物与生俱来的活动:从经验中学习。 机器学习算法使用计算方法直接从数据中“学习”信息,而不依赖 于预定方程模型。当可用于学习的样本数量增加时,这些算法可自 适应提高性能。
机器学习算法可从能够带来洞察力的数据中发现自然模式, 帮助您更好地制定决策和做出预测。医疗诊断、股票交易、 能量负荷预测及更多行业每天都在使用这些算法制定关键决策。 媒体网站依靠机器学习算法从数百万种选择中筛选出为您推荐 的歌曲或影片。零售商利用这些算法深入了解客户的购买行为。
因此,数据对机器学习是必不可少的,有了数据,才有了学习的基础,训练的开始。
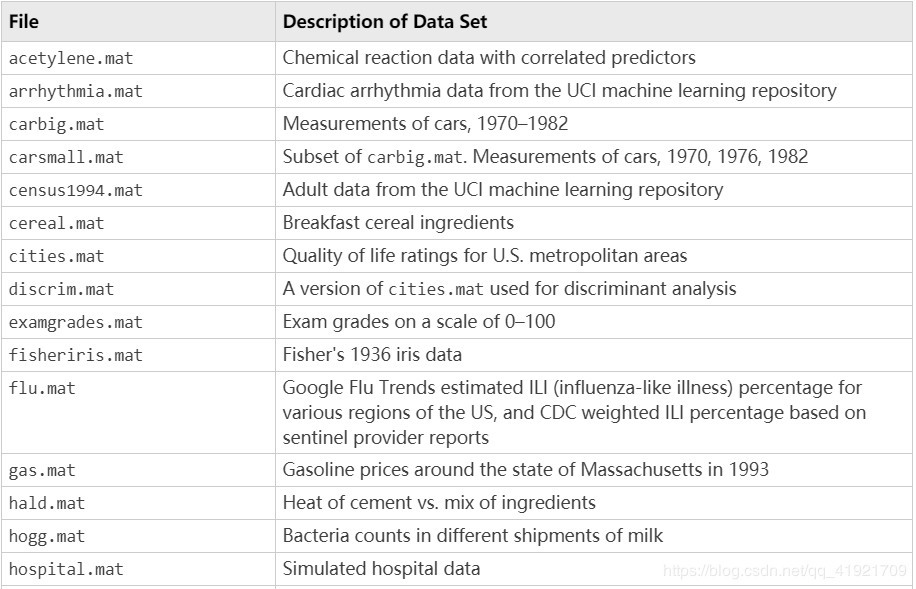
这里选择matlab自带的数据 fisheriris.mat,鸢尾花数据集。下面给出matlab自带的所有
数据集
load fisheriris % 读取数据
meas(:,4) % 显示meas的第四列
fisheriris.mat 有两个数据集,一个是 meas,一个是 species 。
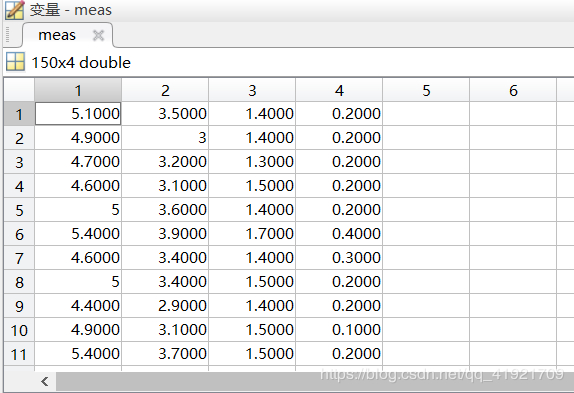
meas 是鸢尾花的一些特征,数据大小为150×4150\times4150×4,每一行对应相应的观测结果,4列对应的属性分别是萼片长度,萼片宽度,花瓣长度,花瓣宽度。
species 是鸢尾花的种类,setosa是山鸢尾,versicolor是多色鸢尾,virginica是弗吉尼亚鸢尾
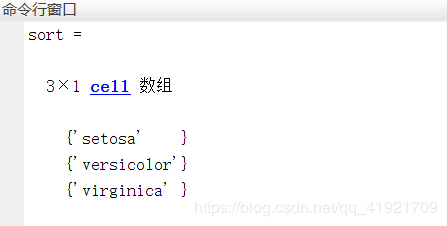
[speciesnum,sort]=grp2idx(species)
利用gpoltmatrix函数,即画散点图矩阵,来查看数据meas四个特征两两之间的相互关系。
load fisheriris % 读取数据
[speciesnum,sort]=grp2idx(species);%查看数据species分类
[H,W,BigW]=gplotmatrix(meas,[],speciesnum,['r' 'g' 'b']);%画散点图矩阵,四列数据两两之间
legend(W(13+3),{'setosa是山鸢尾','versicolor是多色鸢尾','virginica是弗吉尼亚鸢尾'},'Location','northeast')
title('数据特征散点图矩阵')
%横坐标
xlabel(W(4),{'萼片长度'},'Fontweight','Bold','Fontsize',10);
xlabel(W(8+1),{'萼片宽度'},'Fontweight','Bold','Fontsize',10);
xlabel(W(12+2),{'花瓣长度'},'Fontweight','Bold','Fontsize',10);
xlabel(W(16+3),{'花瓣宽度'},'Fontweight','Bold','Fontsize',10);
%纵坐标
ylabel(W(1),{'萼片长度'},'Fontweight','Bold','Fontsize',10);
ylabel(W(2),{'萼片宽度'},'Fontweight','Bold','Fontsize',10);
ylabel(W(3),{'花瓣长度'},'Fontweight','Bold','Fontsize',10);
ylabel(W(4),{'花瓣宽度'},'Fontweight','Bold','Fontsize',10);
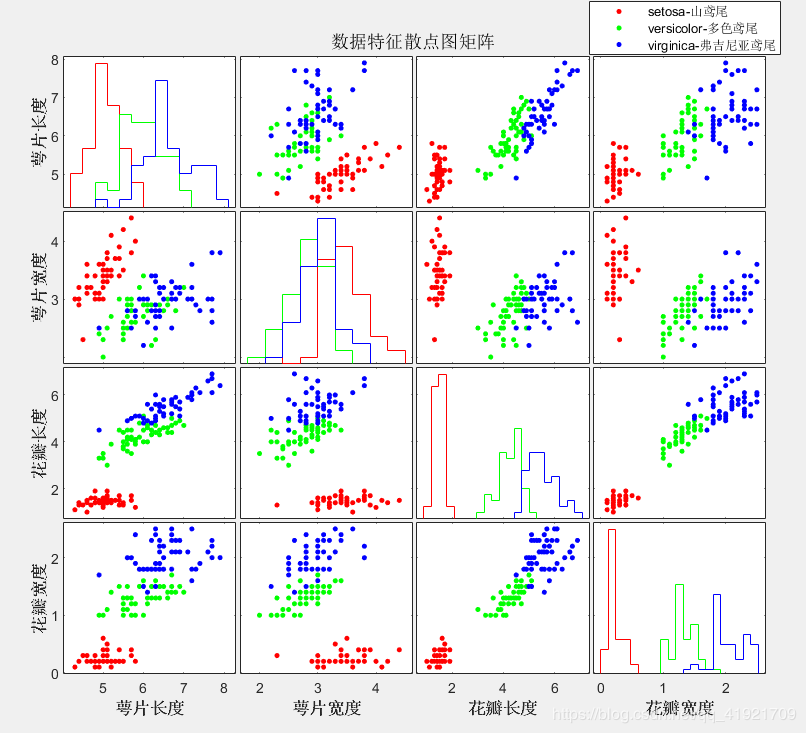
从散点矩阵图上看,若要用单个属性来区分这三种花瓣,花瓣长度和花瓣宽度效果看起
来不错,有很好的区分度。
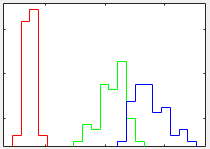
从全局观测看,要想更好的区分,花瓣宽度和花瓣长度这两组属性的组合似乎更好
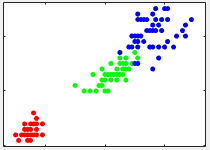
可见,通过对原始数据的预处理,我们已经发现了分类的依据:分类时,我们首先可以从花瓣宽度或花瓣长度单方面作为输入通过合适的算法建立模型进行分类;为了更好的达到效果我们可以以花瓣宽度和花瓣长度联合作为输入通过合适的算法建立模型进行更好的分类。
到此为止,数据预处理,寻找相关性已介绍完成,如有问题,或需要探讨,请留言或联系本人。QQ:2214564003QQ:2214564003QQ:2214564003
欢迎关注本人微信公众号:

作者:快快爬的王小泽