数据挖掘:数据预处理相关概念
一般我们得到的数据会存在有缺失值、重复值等,在使用之前需要进行数据预处理。它是一系列对数据操作的统称。
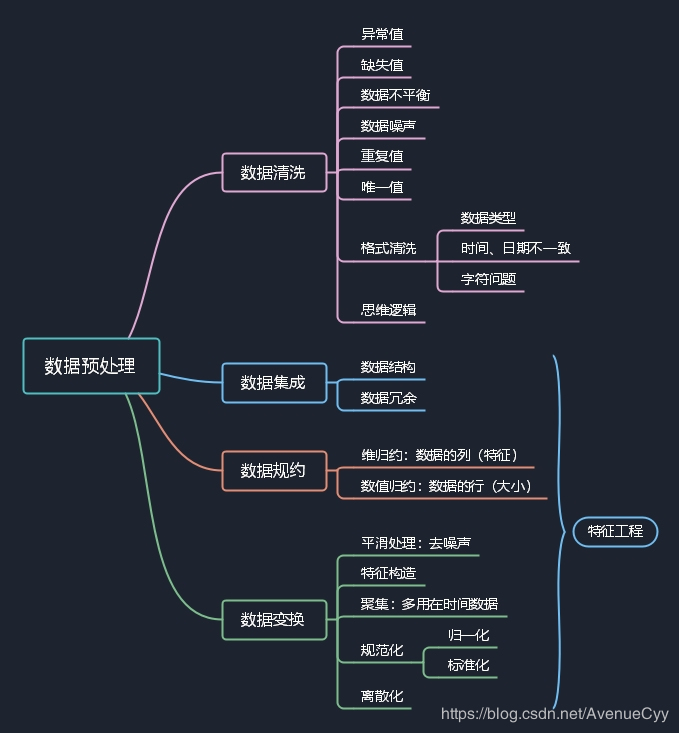
数据预处理没有标准的流程,通常针对不同的任务和数据集属性的不同而不同。数据预处理的常用流程为:
原始数据存在的几个问题:不一致;重复;含噪声;维度高等问题。
二、数据清洗一般数据清洗包括:
缺失值 异常值 数据噪声 数据不平衡 唯一值 重复值 格式清洗 思维逻辑前4个在之前的文章已经提到了,接下来介绍后四个处理方法。
缺失值处理
异常值处理
数据噪声处理
数据不平衡处理
如数据中id这个属性,如果每条数据都对应同一个id,那么该特征对数据的预测就没有任何意义,可删除该列数据。
但并不是所有数据的id都是无意义的。如果每个id都对应了很多的数据,则此时不应删除该id,而是对每个id中的数据进行统计分析。将一个id看做一组数据单独去分析,得到均值、中位数、标准差、峰度、偏度等描述该组分布的信息,整合为一个数据。这样每条数据才会对应一个id,进而再删除id。要根据具体的数据应用场景去判断,而不是一上来就删除数据。
2.2 重复值重复值是无意义的数据,增加了数据量,但却没有增加数据的信息量。一般是将重复值删除。pandas里用data.drop_duplicates()函数进行删除。
链接:pandas重复值处理
一般得到的数据杂乱无章,有的数据是数字、时间却是字符串表示,数据类型对不上。此时,应先对数据类型进行转换,否则无法进行正常运算操作。
在pandas里可用astype(数据类型),或者to_numeric(),进行转换。
链接:pandas数据类型转换
这种问题通常与输入端有关,在整合多来源数据时也有可能遇到,将其处理成一致的某种格式即可。
2.3.3 字符问题某些内容可能只包括一部分字符,比如身份证号是数字+字母,中国人姓名是汉字(赵C这种情况还是少数)。最典型的就是头、尾、中间的空格,也可能出现姓名中存在数字符号、身份证号中出现汉字等问题。这种情况下,需要以半自动校验半人工方式来找出可能存在的问题,并去除不需要的字符。
2.3.4 思维逻辑这个比较玄乎,先通过举例让大家感受下。比如预测电影票房。票房的数据是不能直接拿过来就用的,因为存在通货膨胀,需要对票房进行一定的换算,这样的票房才是能用的数据。也就是说,用的数据是需要符合正常逻辑性的。另外,数据单位的转换,跟业务的关联性也是需要考虑的。
说明:
总之,数据清洗方面的工作有很多……而且,如果数据处理不好,特征没有选好,那么模型再厉害,也无济于事。所以才会经常看到这样的话,在工作或者竞赛中,数据清洗,特征工程方面的工作占据了80%以上的时间。其余模型的使用,需要知道原理,进而调包搭建模型即可。
数据集成是指把数据从多个数据源整合在一起,提供一个观察这些数据的统一视图的过程。建立数据仓库的过程实际上就是数据集成。
数据集成中的两个主要问题是:
数据结构。如何对多个数据集进行匹配,当一个数据库的属性与另一个数据库的属性匹配时,必须注意数据的结构; 数据冗余。两个数据集有两个命名不同但实际数据相同的属性,那么其中一个属性就是冗余的。链接:数据集成
四、数据归约数据归约是指在尽可能保持数据原貌的前提下,最大限度地精简数据量。
数据挖掘时往往数据量非常大,在少量数据上进行挖掘分析需要很长的时间,数据归约技术可以用来得到数据集的归约表示,它小得多,但仍然接近于保持原数据的完整性,并结果与归约前结果相同或几乎相同。通常有维归约、数值归约。
维归约指通过减少属性的方式压缩数据量,通过移除不相关的属性,可以提高模型效率。
常见的维归约方法有:分类树、随机森林通过对分类效果的影响大小筛选属性;小波变换、主成分分析通过把原数据变换或投影到较小的空间来降低维数。
数值归约用较小的数据表示形式替换原始数据。代表方法为对数线性回归、聚类、抽样等。
链接:数据规约详细介绍
五、数据变换通过平滑聚集,数据概化,规范化等方式将数据转换成适用于数据挖掘的形式。比如说,对于线性回归,数据进行归一化或标准化,统一量纲后的效果要比之前要好。因为是用距离去度量的,而树模型则不用进行这种变换。
光滑:去掉噪声; 特征构造:由给定的属性构造出新属性并添加到数据集中。例如,通过“销售额”和“成本”构造出“利润”,只需要对相应属性数据进行简单变换即可 聚集:对数据进行汇总。比如通过日销售数据,计算月和年的销售数据; 规范化:把数据单按比例缩放,比如数据标准化处理; 离散化:将定量数据向定性数据转化。比如一系列连续数据,可用标签进行替换(0,1); 六、总结之前对数据清洗,数据预处理,特征工程等概念比较混淆。通过查找不同的资料,也发现有的定义不太一样,比如特征工程包括了数据预处理,数据清洗,而数据预处理有时又包括了数据清洗和特征工程的一部分。
通过本次探究,把数据预处理归为模型预测前的所有处理过程,包括了数据清洗和特征工程。
数据清洗专门对脏数据进行清洗,而不设涉及数据的变换和特征处理。特征工程则包括了剩下的所有处理方法。
说明:
数据预处理的方法有很多,在处理数据,或者数据竞赛时,不一定都会用上。需要对数据进行探索性分析,了解数据后,根据数据本身特征和预测目标而合理选择相应的方法。
不要拘泥于用所有方法都对数据用一遍,这样不仅自己很累,也得不到想要的效果。包括后面要介绍的各种机器学习的算法,模型使用等,也都是具体问题具体分析,没有哪种处理方式就一定是最好的。总结归总结,最重要的是要自己亲自去处理。而各种方法的使用条件,也是在不断对数据进行处理,建模的过程中摸索出来的。这是数据挖掘的难点,但也是它的迷人之处。
https://blog.csdn.net/yehui_qy/article/details/53791006
https://blog.csdn.net/holandstone/article/details/79034843
https://baike.baidu.com/item/%E6%95%B0%E6%8D%AE%E9%A2%84%E5%A4%84%E7%90%86/2711288?fr=aladdin
作者:AvenueCyy