数据挖掘实战--二手车交易价格预测(二)数据探索性分析(EDA)
包的安装:
采用Anaconda 3进行代码的编译,Anaconda 3里基础的数据分析包都已经准备好,我们需要安装的就是sklearn,lightgbm和xgboost包。
Anaconda可以支持我们采取多种方式安装所需要的包。可以采用pip,conda和从PYPI下载相关包等方式。这里采用的是pip方式。
pip install scikit-learn
pip install lightgbm
pip install xgboost
因为之前一直在进行Arcpy的开发工作,因此我电脑里装配的是Anaconda 2 32位,这在安装lightgbm和xgboost的过程中遇到了错误。因此又安装了Anaconda 3 64位版本。同队的韩哥也遇到了报错的问题,似乎是因为pip的版本不够新,需要升级后再安装。
数据加载与查看首先我们需要将已有的数据读进内存里,
import pandas as pd
import numpy as np
import warnings
#为了防止没有维护的包弹警告,可以在这里过滤掉警告
warnings.filterwarnings('ignore')
#在Jupyter里,可能会对过多的列进行隐藏, 如果想要查看全部的列,可以设置max_columns
pd.set_option('display.max_columns', None)
train_df = pd.read_csv('D:/DataMining/Train Data/used_car_train_20200313.csv', sep=' ')
print(train_df.shape)
train_df.describe()
train_df.head()
下一步来求一下空值数量,看看各个变量空值缺失的状况,如果缺失多,可以考虑在构建特证的时候剔除。
train_df.isnull().sum().sort_values(ascending=False).head()
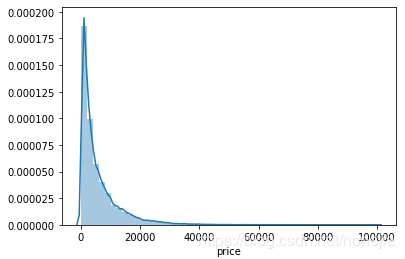
接下来看一下价格的分布
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure()
sns.distplot(train_df['price'])
plt.figure()
train_df['price'].plot.box()
plt.show()
再将测试集读进来,看一下测试集的状态。
import gc
test_df = pd.read_csv('datalab/231784/used_car_testA_20200313.csv', sep=' ')
print(test_df.shape)
df = pd.concat([train_df, test_df], axis=0, ignore_index=True)
del train_df, test_df
gc.collect()
df.head()

我们接下来可以看一下非匿名的几个可能会比较相关的数据的分布。
plt.figure()
plt.figure(figsize=(16, 6))
i = 1
for f in date_cols:
for col in ['year', 'month', 'day', 'dayofweek']:
plt.subplot(2, 4, i)
i += 1
v = df[f + '_' + col].value_counts()
fig = sns.barplot(x=v.index, y=v.values)
for item in fig.get_xticklabels():
item.set_rotation(90)
plt.title(f + '_' + col)
plt.tight_layout()
plt.show()
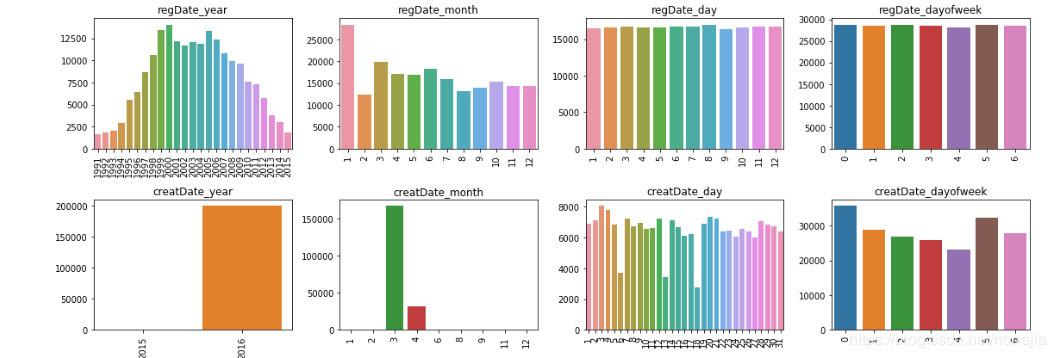
移除只有单个因素的特征
cate_cols.remove('seller')
cate_cols.remove('offerType')
date_cols = ['regDate_year', 'regDate_month', 'regDate_day', 'regDate_dayofweek', 'creatDate_month', 'creatDate_day', 'creatDate_dayofweek']
下一步想要查看一下各个特征和price的相关性,以及特征和特征之间的关系。这个图表可以帮助我们理解哪些特征可以被选入特征向量的的构建,还有降维时要去除哪些特征。
corr1 = abs(df[~df['price'].isnull()][['price'] + date_cols + num_cols].corr())
plt.figure(figsize=(10, 10))
sns.heatmap(corr1, linewidths=0.1, cmap=sns.cm.rocket_r)
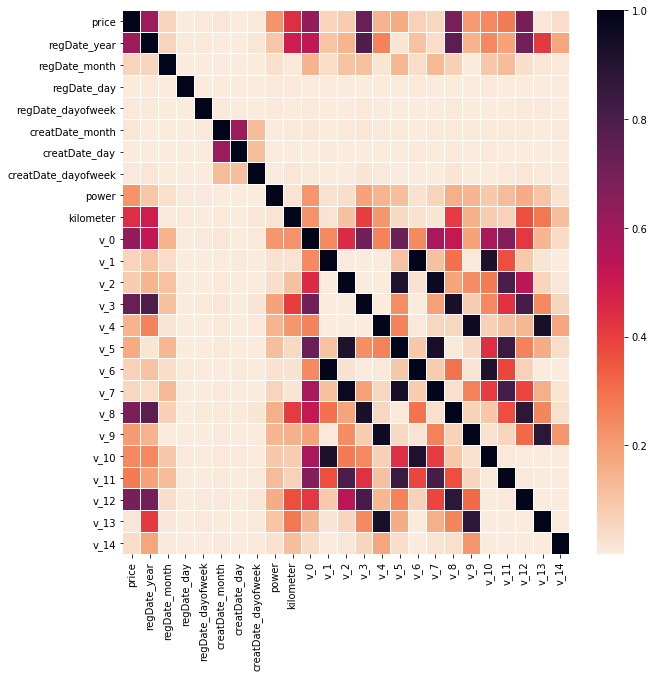
跟price相关性高的是regDate_year、kilometer;匿名特征中的v_0、v_3、v_8、v_12与price相关性很高。有些特征跟特征之间的相关性也很高,比如v_1跟v_6、v_2跟v_7、v_3跟v_8、v_4跟v_9等,这些特征之间可能存在冗余现象,训练的时候可以依据效果尝试去掉一部分。
test_df = pd.read_csv('D:/DataMining/Test Data/used_car_testA_20200313.csv', sep=' ')
#将price变换为正态分布
train_df['price'] = np.log1p(train_df['price'])
# 删除部分异常值
train_df.drop(train_df[train_df['price'] 600 else x)
test_df['power'] = test_df['power'].map(lambda x: 600 if x>600 else x)
# 整合训练集测试集以便后续特征工程
all_features = pd.concat([train_df, test_df], sort=False).reset_index(drop=True)
填充缺失值
将存在空值的部分填充为均值
def fill_missing(df):
df['fuelType'] = df['fuelType'].fillna(train_df['fuelType'].mean())
df['gearbox'] = df['gearbox'].fillna(train_df['gearbox'].mean())
df['bodyType'] = df['bodyType'].fillna(train_df['bodyType'].mean())
df['model'] = df['model'].fillna(train_df['model'].mean())
return df
all_features = fill_missing(all_features)
数据类型转换
对一些分类特征存储成数值需要进行转化为字符型数值
def data_astype(df):
# string
df['SaleID'] = df['SaleID'].astype(int).astype(str)
df['name'] = df['name'].astype(int).astype(str)
df['model'] = df['model'].astype(str)
df['brand'] = df['brand'].astype(str)
df['bodyType'] = df['bodyType'].astype(str)
df['fuelType'] = df['fuelType'].astype(str)
df['gearbox'] = df['gearbox'].astype(str)
df['notRepairedDamage'] = df['notRepairedDamage'].astype(str)
df['regionCode'] = df['regionCode'].astype(int).astype(str)
df['seller'] = df['seller'].astype(int).astype(str)
df['offerType'] = df['offerType'].astype(int).astype(str)
return df
all_features = data_astype(all_features)
提取年份和月份
# 提取年份
all_features['regYear'] = all_features['regDate'].map(lambda x:int(str(x)[:4]))
all_features['createYear'] = all_features['creatDate'].map(lambda x:int(str(x)[:4]))
# 提取月份
all_features['regMonth'] = all_features['regDate'].map(lambda x:int(str(x)[4:6]))
all_features['createMonth'] = all_features['creatDate'].map(lambda x:int(str(x)[4:6]))
# 计算上线日期与注册日期想差月份数
all_features['months'] = (all_features['createYear']-all_features['regYear'])*12+(all_features['createMonth']-all_features['regMonth'])
all_features['years'] = all_features['months'] / 12
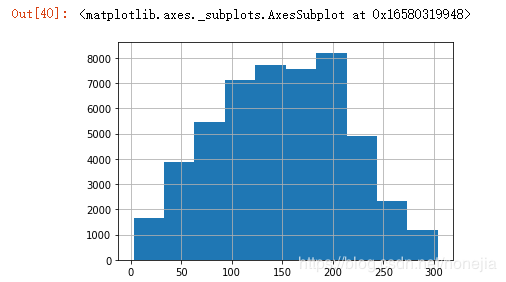
# 查看月份数统计值
all_features['months'].describe()
# 月份数分布
all_features['months'].hist()

删除一些不要的特征。
all_features = all_features.drop(['SaleID', 'name', 'regDate', 'model', 'seller',
'offerType', 'creatDate', 'regYear', 'regionCode',
'createYear', 'regMonth', 'createMonth', 'months'], axis=1)
查看剩余的特征类型
all_features.dtypes

创建相关性组合,为之后的删除相关性高的变量做准备
corr = all_features.corr()
#创建相关性系数组合
feature_group = list(itertools.combinations(corr.columns, 2))
这部分探索性分析告一段落。后续的处理和训练会再进行一个文档记录。
作者:CannonJia