(数据库原理及应用笔记)数据库管理系统
The component of DBMS core
( Query all or most records of a file(>15%)
( Query some special record
( Query some records(<15%)
( Scope query
( Update File organization
( Heap file
( Direct file
( Indexed file:index + heap file/cluster ->B+Tree
( Dynamic hashing
( Grid structure file
( Raw disk Index technique
( B+ Tree
( Clustering index(簇集索引)
( Inverted file
( Dynamic hashing
( Grid structure file and partitioned hash function
( Bitmap index(used in data warehouse)
( Others Access primitives
-> Algebra Optimization(Rewrite
-> Operation Optimization(存储结构、索引
-> Nest Loop,R as O,S as I
-> Nest Loop,R as I,S as O
-> Nest Loop,use possible index on R or S
-> Merge Scan
-> Hash join Algebra optimization
-> Exchange rule of ⋈/×: E1 × E2 ≡ E2 ×E1
-> Combination rule of ⋈/×: E1×(E2×E3)≡(E1×E2)×E3
-> Cluster rule of ∏: ∏A1…An(∏B1…Bm(E))≡∏A1…An(E),
legal when A1…An is the sub set of {B1…Bm}
-> Cluster rule of δ: δF1(δF2(E))≡δF1∧F2(E)
-> Exchange rule of ∏ and δ: δF(∏A1…An(E))≡∏A1…An (δF(E)) if F includes attributes B1…Bm which don’t belong to A1…An, then ∏A1…An (δF(E)) ≡ ∏A1…An δF(∏A1…An, B1…Bm(E))
-> If the attributes in F are all the attributes in E1, thenδF(E1×E2) ≡ δF(E1)×E2;
if F in the form of F1∧F2, and there are only E1’s attributes in F1, and there are only E2‟s attributes in F2, then δF(E1×E2) ≡δF1(E1)×δF2(E2);
if F in the form of F1∧F2, and there are only E1‟s
attributes in F1, while F2 includes the attributes both in E1 and E2, then δF(E1×E2) ≡δF2(δF1(E1)×E2);
-> δF(E1 ⋃ E2) ≡ δF(E1) ⋃ δF(E2)
-> δF(E1 - E2) ≡ δF(E1) - δF(E2)
-> Suppose A1…An is a set of attributes, in which B1…Bm are E1‟s attributes, and C1…Ck are E2‟s attributes, then∏A1…An(E1×E2)≡∏B1…Bm(E1)×∏C1…Ck(E2)
-> ∏A1…An(E1 ⋃ E2)≡∏A1…An(E1) ⋃ ∏A1…An(E2) Basic principles
-> Push down the unary operations as low as possible
-> Look for and combine the commo n sub-expression The operation optimization
-> Optimization of select operation
-> Optimization of project operation
-> Optimization of set operation
-> Optimization of join operation
-> Optimization of combined operations Recovery
-> Reducing the likelihood of failures
-> Recover from failures
-> Restore DB to aconsistent state after some failures
(Redundancy is necessary
(Should inspect all possible failures
-> Periodical dumping
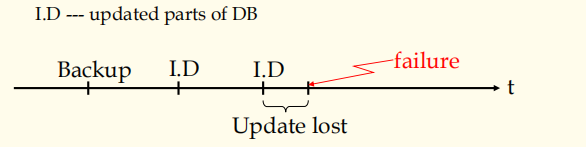
-> Backup + Log
 Transaction
Transaction
-> Atomic action
-> Consistency preservation(保持一致性)
-> Isolation
-> Durability Some structures to support recovery
-> Commit list
-> Active list
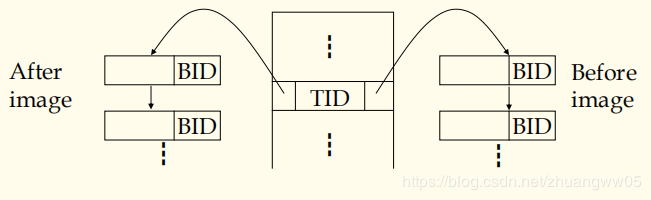
-> Log
 Commit rule and Log ahead rule
Commit rule and Log ahead rule
-> Commit rule: A.I must be written to nonvolatile strorage(非挥发存储器) before commit of the transaction
-> Log ahead rule: If A.I is written to DB before commit then B.I must first written to log
-> Recovery strategies Three kinds of update strategy
-> A.I-DB before commit

 -> A.I-D.B after commit
-> A.I-D.B after commit

 -> A.I-D.B concurrently with commit
-> A.I-D.B concurrently with commit

 -> 异地更新
Concurrency control
-> 异地更新
Concurrency control
 -> Serializable
Locking Protocol
X locks
-> Serializable
Locking Protocol
X locks
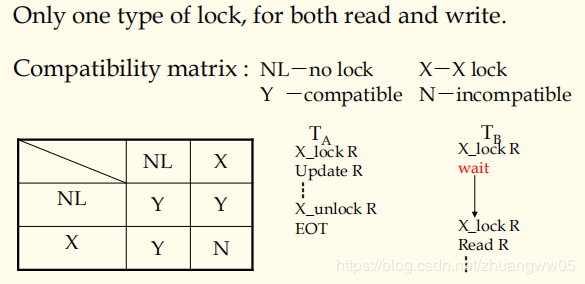
-> S lock — if read access is intended.
-> X lock — if update access is intended.
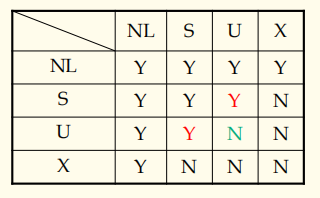
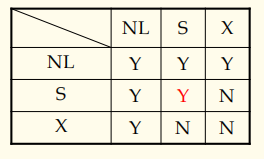 - (S,U,X) locks
- (S,U,X) locks
-> U lock — update lock.For an update access the transaction first acquires a U-lock and then promote it to X-lock.
-> Purpose — shorten the time of exclusion,so as to boost concurrency degree, and reduce deadlock.
 Deadlock & Livelock
Deadlock & Livelock
-> Deadlock — wait in cycle,no transaction can obtain all of resources needed to complete
-> Prevention(do not let it occur)
-> Solving(permit it occurs,but can solve it)

-> Timeout
-> Detect deadlock by wait-for graph G=
-> When to detect? —
whenever one transaction waits.
-> What to do when detected? —
①Pick a victim;
②Abort the victim and release its locks and resources;
③Grant a waiter;
④Restart the victim(automatically or manually)
-> Deadlock avoidance —
①Requestin all locks at initial time of transaction
②Requesting locks in a specified order of resource
③Abort once conflicted
④Transaction Retry
-> Every transaction is uniquely time stamped.If Ta requires a lock on a data object that is already locked by Tb,one of the following methods is uesd
①Wait-die
②Wound-wait
In above,both have only one direction wait,either older->younger or younger->older.It is impossible to occur wait in cycle,so the dead lock is avoided.
作者:zhuangww05
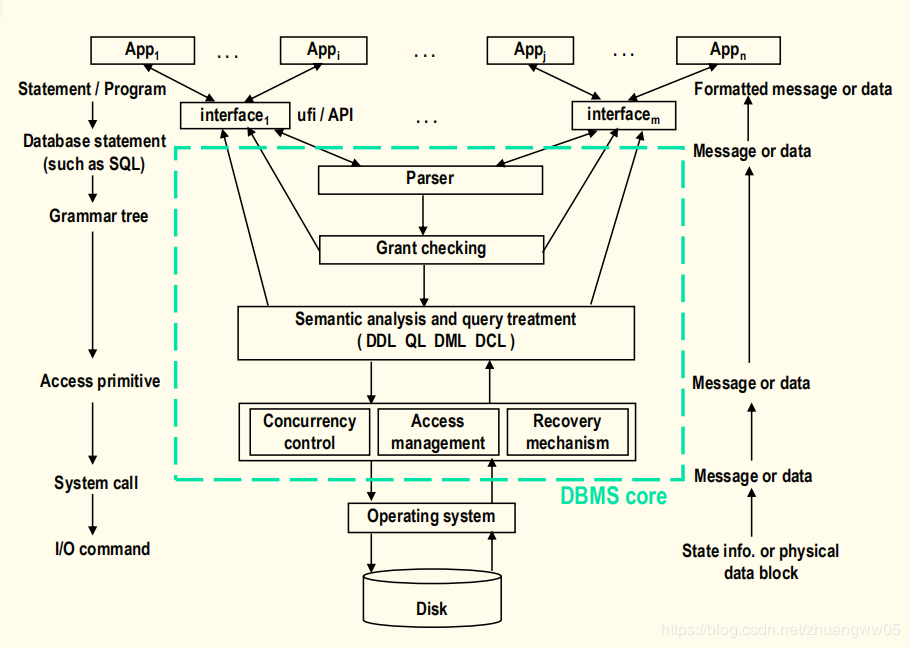 -> UFI (即席访问)
-> UFI (即席访问)
-> APIs (类库、嵌入式…)
-> Access management (访问原语)
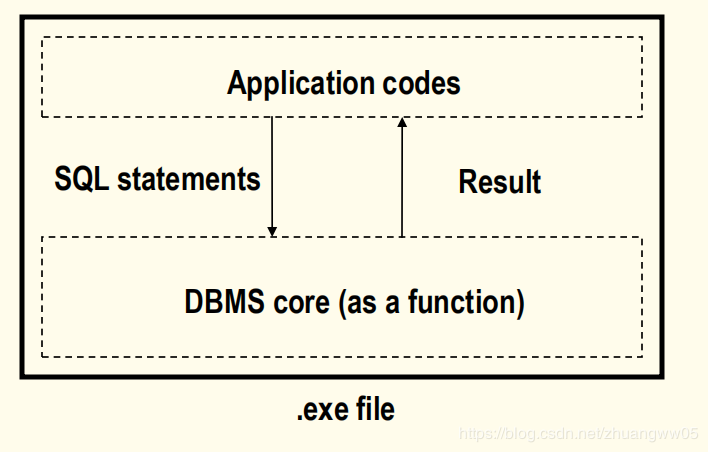
-> Single process structure
-> Multi processes structure
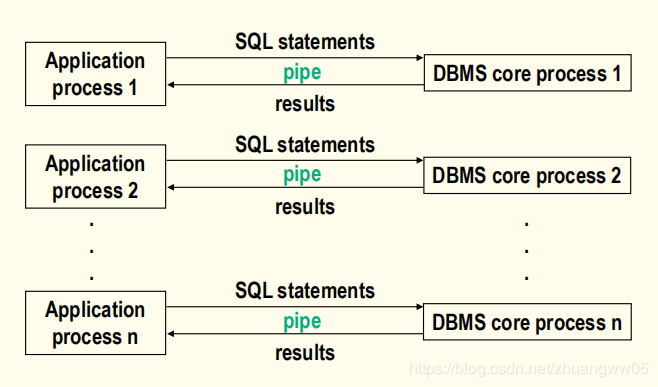
-> Multi threads structure
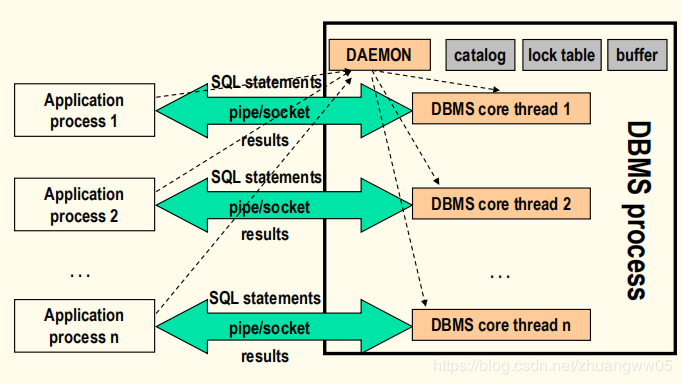
-> Communication protocols between processes/threads
( Query all or most records of a file(>15%)
( Query some special record
( Query some records(<15%)
( Scope query
( Update File organization
( Heap file
( Direct file
( Indexed file:index + heap file/cluster ->B+Tree
( Dynamic hashing
( Grid structure file
( Raw disk Index technique
( B+ Tree
( Clustering index(簇集索引)
( Inverted file
( Dynamic hashing
( Grid structure file and partitioned hash function
( Bitmap index(used in data warehouse)
( Others Access primitives
-> Algebra Optimization(Rewrite
-> Operation Optimization(存储结构、索引
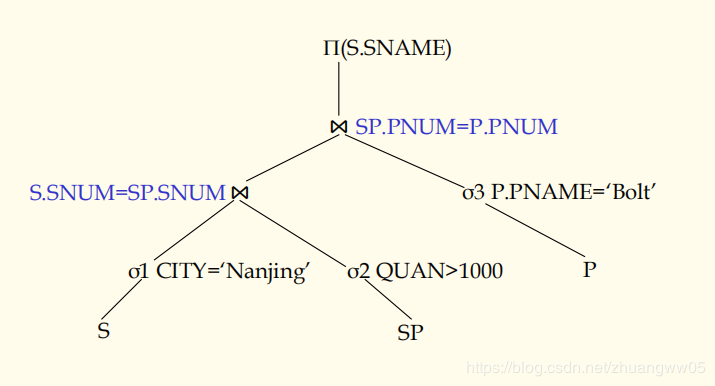
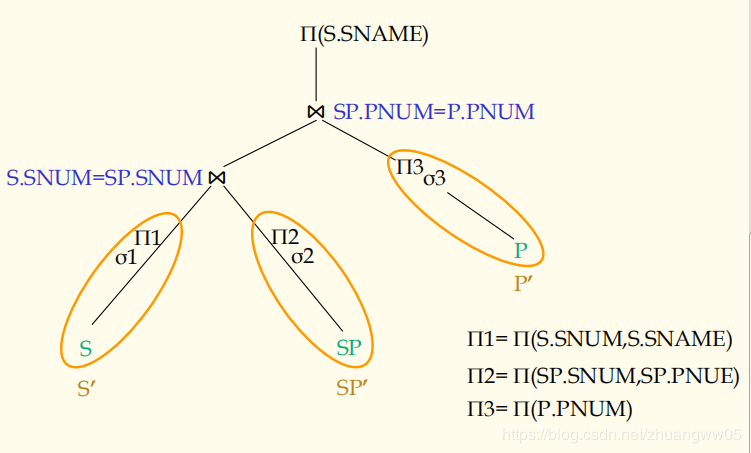
S(SNUM, SNAME, CITY)
SP(SNUM, PNUM, QUAN)
P(PNUM, PNAME, WEIGHT, SIZE)
SELECT SNAME
FROM S, SP, P
WHERE S.SNUM=SP.SNUM AND
SP.PNUM=P.PNUM AND
S.CITY=‘Nanjing’ AND
P.PNAME=‘Bolt’ AND
SP.QUAN>1000;
-> Nest Loop,R as O,S as I
-> Nest Loop,R as I,S as O
-> Nest Loop,use possible index on R or S
-> Merge Scan
-> Hash join Algebra optimization
-> Exchange rule of ⋈/×: E1 × E2 ≡ E2 ×E1
-> Combination rule of ⋈/×: E1×(E2×E3)≡(E1×E2)×E3
-> Cluster rule of ∏: ∏A1…An(∏B1…Bm(E))≡∏A1…An(E),
legal when A1…An is the sub set of {B1…Bm}
-> Cluster rule of δ: δF1(δF2(E))≡δF1∧F2(E)
-> Exchange rule of ∏ and δ: δF(∏A1…An(E))≡∏A1…An (δF(E)) if F includes attributes B1…Bm which don’t belong to A1…An, then ∏A1…An (δF(E)) ≡ ∏A1…An δF(∏A1…An, B1…Bm(E))
-> If the attributes in F are all the attributes in E1, thenδF(E1×E2) ≡ δF(E1)×E2;
if F in the form of F1∧F2, and there are only E1’s attributes in F1, and there are only E2‟s attributes in F2, then δF(E1×E2) ≡δF1(E1)×δF2(E2);
if F in the form of F1∧F2, and there are only E1‟s
attributes in F1, while F2 includes the attributes both in E1 and E2, then δF(E1×E2) ≡δF2(δF1(E1)×E2);
-> δF(E1 ⋃ E2) ≡ δF(E1) ⋃ δF(E2)
-> δF(E1 - E2) ≡ δF(E1) - δF(E2)
-> Suppose A1…An is a set of attributes, in which B1…Bm are E1‟s attributes, and C1…Ck are E2‟s attributes, then∏A1…An(E1×E2)≡∏B1…Bm(E1)×∏C1…Ck(E2)
-> ∏A1…An(E1 ⋃ E2)≡∏A1…An(E1) ⋃ ∏A1…An(E2) Basic principles
-> Push down the unary operations as low as possible
-> Look for and combine the commo n sub-expression The operation optimization
-> Optimization of select operation
-> Optimization of project operation
-> Optimization of set operation
-> Optimization of join operation
-> Optimization of combined operations Recovery
-> Reducing the likelihood of failures
-> Recover from failures
-> Restore DB to aconsistent state after some failures
(Redundancy is necessary
(Should inspect all possible failures
-> Periodical dumping
-> Backup + Log
Transaction-> Atomic action
-> Consistency preservation(保持一致性)
-> Isolation
-> Durability Some structures to support recovery
-> Commit list
-> Active list
-> Log
Commit rule and Log ahead rule-> Commit rule: A.I must be written to nonvolatile strorage(非挥发存储器) before commit of the transaction
-> Log ahead rule: If A.I is written to DB before commit then B.I must first written to log
-> Recovery strategies Three kinds of update strategy
-> A.I-DB before commit
-> A.I-D.B after commit-> A.I-D.B concurrently with commit-> 异地更新
Concurrency control-> Serializable
Locking Protocol
X locks

-> Conclusions
-> Well-formed + 2PL: serializable
-> Well-formed + 2PL + unlock update at EOT: serializable and recoverable.(without domino phenomena)
-> Well-formed + 2PL + holding all locks to EOT: strict two phase locking transaction
-> S lock — if read access is intended.
-> X lock — if update access is intended.
- (S,U,X) locks-> U lock — update lock.For an update access the transaction first acquires a U-lock and then promote it to X-lock.
-> Purpose — shorten the time of exclusion,so as to boost concurrency degree, and reduce deadlock.
Deadlock & Livelock-> Deadlock — wait in cycle,no transaction can obtain all of resources needed to complete
-> Prevention(do not let it occur)
-> Solving(permit it occurs,but can solve it)
-> Livelock — although other transaction release their resource in limited time,some transaction can not get the resources needed for a very long time.
-> Adjust schedule strategy,such as FIFO
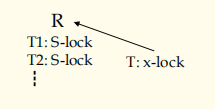
-> Timeout
-> Detect deadlock by wait-for graph G=
-> When to detect? —
whenever one transaction waits.
-> What to do when detected? —
①Pick a victim;
②Abort the victim and release its locks and resources;
③Grant a waiter;
④Restart the victim(automatically or manually)
-> Deadlock avoidance —
①Requestin all locks at initial time of transaction
②Requesting locks in a specified order of resource
③Abort once conflicted
④Transaction Retry
-> Every transaction is uniquely time stamped.If Ta requires a lock on a data object that is already locked by Tb,one of the following methods is uesd
①Wait-die
②Wound-wait
In above,both have only one direction wait,either older->younger or younger->older.It is impossible to occur wait in cycle,so the dead lock is avoided.
作者:zhuangww05
相关文章
Odessa
2020-03-06
Chynna
2021-04-13
Jacuqeline
2023-07-20
Grizelda
2023-07-20
Janna
2023-07-20
Ophelia
2023-07-21
Crystal
2023-07-21
Laila
2023-07-21
Aine
2023-07-21
Bliss
2023-07-21
Lillian
2023-07-21
Tertia
2023-07-21
Olive
2023-07-21
Valentina
2023-07-21
Angie
2023-07-21
Laila
2023-07-22
Nora
2023-07-24