(教妹学数据库系统)(九)查询执行
hello大家好,好久不见!今天我们的《教妹学数据库系统》来学习数据库系统中的查询执行:排序、选择、去重、聚集和集合差操作。教妹学数据库,没见过这么酷炫的标题吧?“语不惊人死不休”,没错,标题就是这么酷炫。
我的妹妹小埋18岁,校园中女神一般的存在,成绩优异体育万能,个性温柔正直善良。然而,只有我知道,众人眼中光芒万丈的小埋,在过去是一个披着仓鼠斗篷,满地打滚,除了吃就是睡和玩的超级宅女。而这一切的转变,是从那一天晚上开始的。
从此之后,小埋经常让我帮她辅导功课。今天她想了解数据库系统中的查询执行。本篇教程通过我与小埋的对话的方式来谈一谈排序、选择、去重、聚集和集合差操作。
排序操作
将关系R划分的归并段数为: ⌈\lceil⌈B(R))M\frac{B(R))}{M}MB(R))⌉\rceil⌉
过程:
for R的每M块 do
将这M块读入缓冲池中M页
对这M页中的元组按排序键(sortkey)进行排序,形成归并段(run)
将该归并段写入文件
多路归并
将 ⌈\lceil⌈B(R))M\frac{B(R))}{M}MB(R))⌉\rceil⌉ 个归并段中的元组进行归并
过程:
将每个归并段的第1块读入缓冲池的1页
repeat
找出所有输入缓冲页中最小的排序键值v
将所有排序键值等于v的元组写入输出缓冲区
任意输入缓冲页中的元组若归并完毕,则读入其归并段的下一页
until 所有归并段都已归并完毕
算法分析
分析算法时不考虑结果输出操作
输出结果时产生的I/O不计入算法的I/O代价。输出结果可能直接作为后续操作的输入,无需写入文件
输出缓冲区不计入可用内存页数。如果输出结果直接作为后续操作的输入,那么输出缓冲区将计入后续操作的可用内存页数
I/O代价: 3B( R )
在创建归并段时,R的每块读1次,合计B( R )次I/O 将每个归并段写入文件,合计B( R )次I/O。在归并阶段,每个归并段扫描1次,合计B( R )次I/O可用内存页数要求: B( R) ≤ M2M^2M2
每个归并段不超过M页 最多M个归并段 多趟多路外存归并排序若B( R )>M2M^2M2,则需要执行多趟多路外存归并排序
I/O代价是(2m−1)B( R ),其中m算法执行的趟数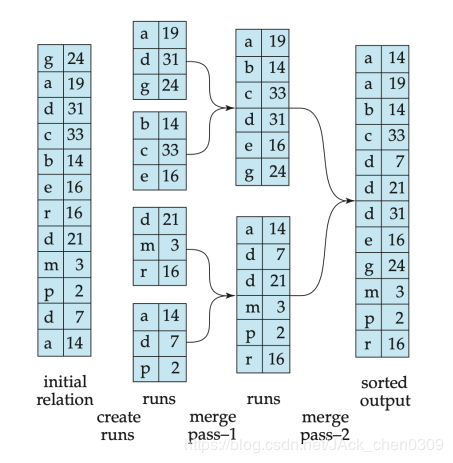
多路归并排序的优化:当某缓冲页中所有元组都已归并完毕,DBMS需读入其归并段的下一块此时,归并进程被挂起(suspend),直至I/O完成。
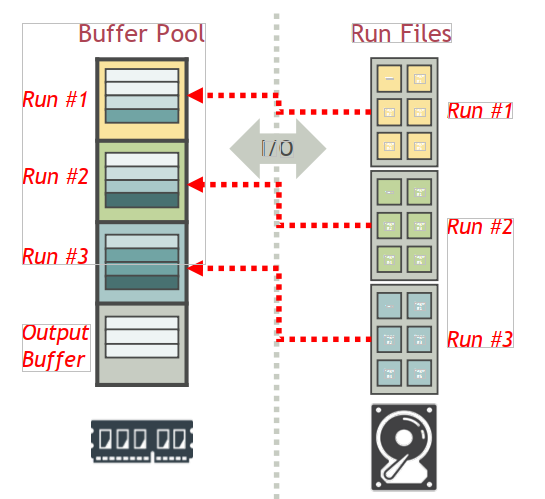
为每个归并段分配多个内存页作为输入缓冲区,并组成环形(circular)
在当前缓冲页中所有元组都已归并完毕时,DBMS直接开始归并下一缓冲页中的元组
与此同时,DBMS将归并段文件的下一块读入空闲的缓冲页
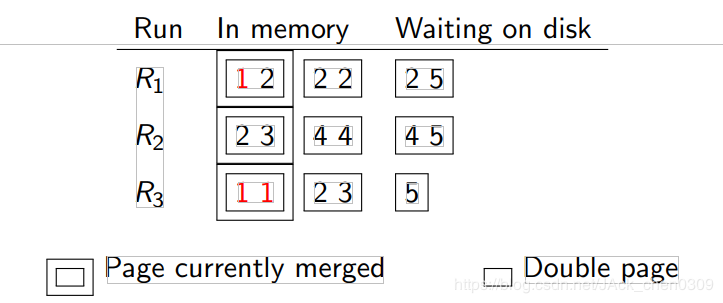

块数 (外存),即是页数(缓冲池)
B( R )/V(R,K)指每个不同值的平均块数
for R的每一块P do
将P读入缓冲池
for P中每条元组t do
if t满足选择条件
then 将t写入输出缓冲区
I/O代价: B( R )(R采用聚簇存储)
R的元组连续存储于文件中 R的每块只读1次I/O代价: T( R )(R不采用聚簇存储)
R的元组不连续存储于文件中 最坏情况下,R的元组均在不同页上可用内存页数要求:M≥1
至少需要1页作为缓冲区,用于读R的每一块 基于哈希的选择算法(Hash-basedSelection) 算法根据hash(v)确定结果元组所在的桶
在桶页面中搜索键值等于v的元组,并将元组写入输出缓冲区
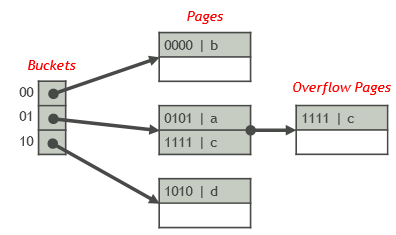
使用该算法的前提条件
选择条件的形式是K=v或l≤K≤u 关系R上建有属性K的索引在索引上搜索满足选择条件的元组,并将元组写入输出缓冲区
算法分析 I/O代价≈B( R )/V(R,K)(如果索引是聚簇索引) 结果元组连续存储于文件中 属性K有V(R,K)个不同的值 结果元组约占B( R )/V(R,K)个页(很不准确的估计) I/O代价≈T( R )/V(R,K)(如果索引是非聚簇索引) 约有T( R )/V(R,K)个结果元组(很不准确的估计) 结果元组不一定连续存储于文件中 最坏情况下,所有结果元组均在不同页上 可用内存页数要求: M ≥ 1 至少需要1页作为缓冲区,用于读B+树的节点 去重操作 不带去重的投影算法
算法
for R的每一块P do
将P读入缓冲池
for P中每条元组t do
if未见过 tthen
将t写入输出缓冲区
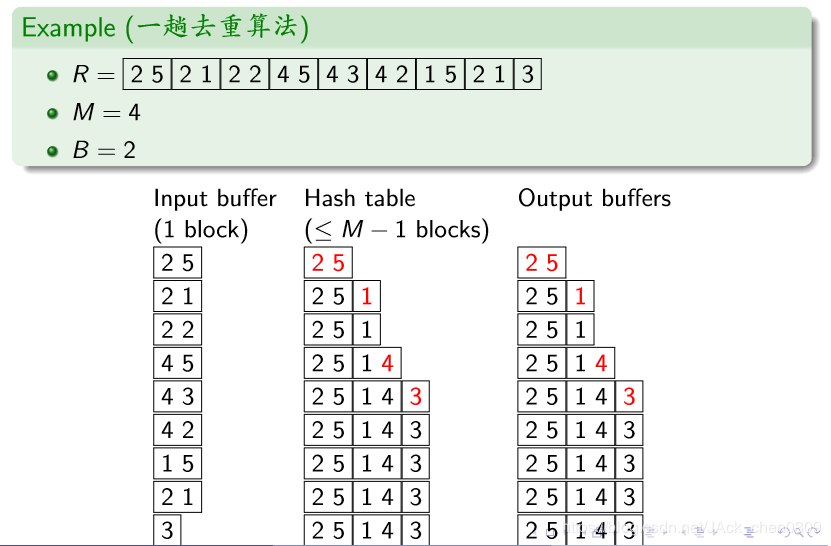
该算法在数据访问模式上与基于扫描的选择算法相同
I/O代价:B( R )(R采用聚簇存储) R的元组连续存储于文件中 R的每块只读1次 I/O代价:T( R )(R不采用聚簇存储) R的元组不连续存储于文件中 最坏情况下,R的元组均在不同页上 可用内存页数要求:B(δ( R ))≤M−1R中互不相同的元组δ( R )必须能在M−1页中存得下 基于排序的去重算法(Sort-basedDuplicateElimination)
基于排序的去重算法与多路归并排序(multiwaymergesort)算法本质上一样,两点区别如下:
在创建归并段(run)时,按整个元组进行排序
在归并阶段,相同元组只输出1个,其他全部丢弃
算法分析 I/O代价:3B( R ) 在创建归并段时,R的每块读1次,合计B( R )次I/O 将每个归并段写入文件,合计B( R )次I/O 在归并阶段,每个归并段扫描1次,合计B( R )次I/O 可用内存页数要求: B( R )≤M^2每个归并段不超过M页
最多M个归并段 基于哈希的去重算法(Hash-basedDuplicateElimination)

逐桶去重的原因:可能重复的元素一定在一个桶中,哈希的过程已经分开了
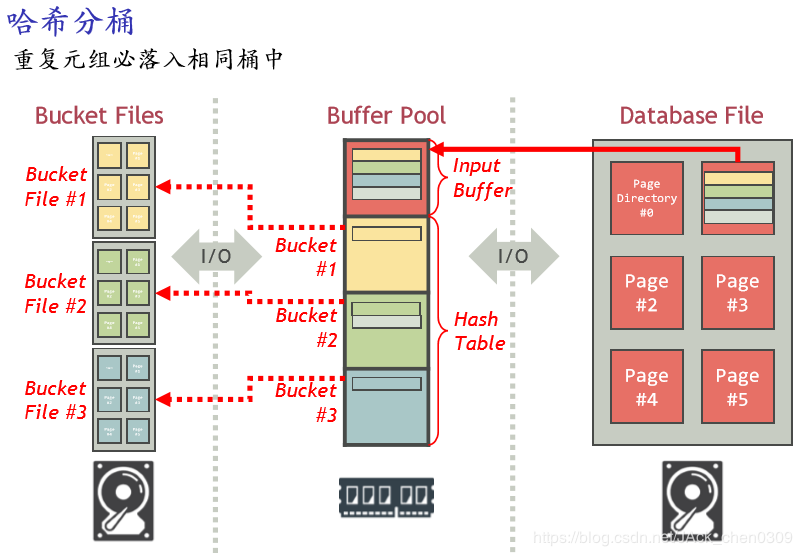
每个桶Ri的去重结果放在一起就得到了R的去重结果
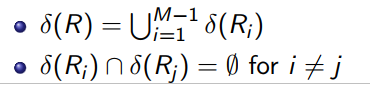

在哈希分桶时,R的每块读1次,合计B( R )次I/O
将每个桶写入文件
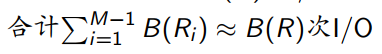
在每个桶Ri上执行一趟去重算法的I/O代价是B(Ri)
共M−1个桶
每个桶不超过M−1块,因此在每个桶上执行一趟去重算法时,可用内存页数满足要求
聚集操作聚集操作和去重操作的执行在本质上一样
方法1:一趟聚集算法(One-passAggregation)
方法2:基于排序的聚集算法(Sort-basedAggregation)
方法3:基于哈希的聚集算法(Hash-basedAggregation)
集合差操作 一趟集合差算法(One-PassSetDifference)

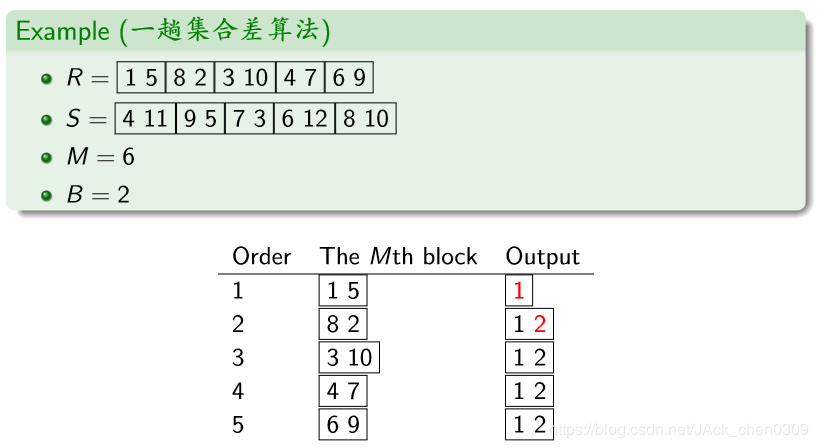
在构建(build)阶段,S的每块只读1次,合计B(S)次I/O
在探测(probe)阶段,R的每块只读1次,合计B( R )次I/O
咱们玩归玩,闹归闹,别拿学习开玩笑。
本篇介绍了查询执行的五大 “法宝” 操作:排序、选择、去重、聚集和集合差操作。学习时要注重抓住各大操作的原理和本质,比如聚集操作和去重操作的本质上是一样的,学会了去重操作便可触类旁通,知道聚集操作如何执行。每个操作有多种算法,根据算法分析的结果可以明显看出不同算法的优缺点和适应场景。
作者:天才程序YUAN