数据库系统概念读书笔记-关系数据库
关系数据库由表的集合构成,每个表有唯一的名字。表中的一行代表了一组值之间的一种联系,因此表就是这种联系的集合。在数学术语中,元组(tuple)是一组值得序列(或列表)。n个值之间得一种联系可以在数学上用关于这些值的一个n元组(n-tuple)表示,换而言之,n元组就是一个有n个值得元组,它对应于表中的一行。
在关系模型术语中,关系(relation)用来指代表,而元组用来指代行,属性指代表中的列。
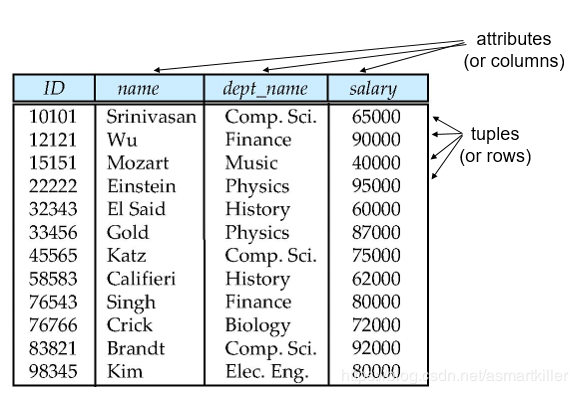
对于关系的每个属性,都存在一个允许取值的集合,称为该属性的域(domain),例如整数型、字符型、日期\时间型。空null值是所有域的成员,表示值未知或不存在。

关系的概念对应于程序设计语言中变量的概念,而关系模型则对应于程序设计语言中类型定义的概念。尽管关系模型和实例区别非常重要,但是我们常常使用同一个名字。比如instructor既指代模式也指代实例。
假设属性为: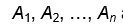
关系模型就是: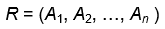
以instructor为例: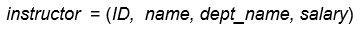
通常,给定域集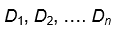
关系r是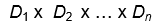 的子集。因此关系是n元组
的子集。因此关系是n元组![]() 的集合,且
的集合,且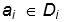

一个元组的属性值必须是能够唯一区分元组的。超码(superkey)是一个或多个属性的集合,这些属性的组合可以使我们在一个关系中唯一地标识一个元组。例如instructor关系的ID属性足以将不同教师元组分开,因此ID是一个超码。

设R表示关系r模式中的属性集合,R的一个子集K是r的一个超码。则限制了关系r中任意两个不同元组不会在K的所有属性上取值完全相等。超码中可能包含无关紧要的属性。例如ID和name的组合是关系instructor的一个超码,那么包含ID的任意超集也是超码。如果任意真子集都不能称为超码,则这样的最小超码称为候选码(candidate key)。

使用主码(primary key)来代表被数据库设计者选中的、主要用来在一个关系中区分不同元组的候选码。

一个关系模式(如r1)可能在它的属性中包括另一个关系模式(如r2)的主码。这个属性在r1上称作参照r2的外码(foreign key)。关系r1称为外码依赖的参照关系(referencing relation),r2叫做外码的被参照关系(referenced relation)。
一个含有主码和外码依赖的数据库模式可以用模式图来表示。每个关系用一个矩形表示,关系的名字显示在矩形上方,矩形内列出各属性。主码属性用下划线标注。外码依赖用从参照关系的外码属性到被参照关系的主码属性之间的箭头来表示。
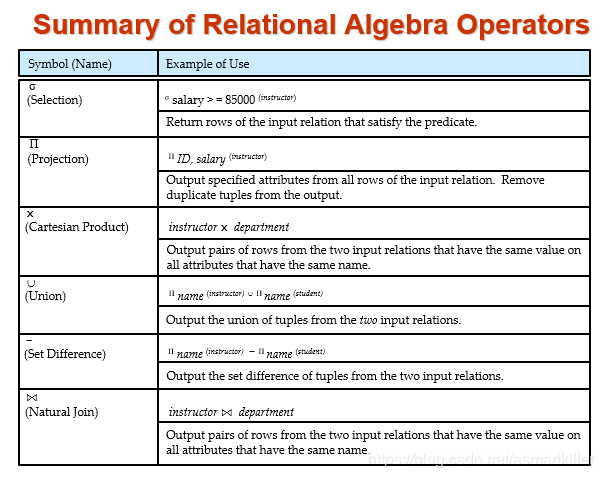
关系查询语言查询语言可以分为过程化和非过程化。过程化语言,用户指导系统对数据库执行一系列操作以计算出所需结果。非过程化语言,用户只需描述所需信息,而不用给出获取该信息的具体过程。关系代数是过程化的,而元组关系演算和域关系演算是非过程化的。

所有过程化关系查询语言都提供了一组运算,这些运算要么施加在单个关系上,要么施加于一对关系上,且运算结果总是单个的关系。
作者:肥叔菌