用Jupyter notebook完成Iris数据集的 Fisher线性分类,并学习数据可视化技术
这里写自定义目录标题一、关于Fisher算法的主要思想与数学计算步骤已在上次博客中有讲到。二、用scikit-learn库中也有LDA的函数,下面给出测试代码三、完成Iris数据集的 Fisher线性分类,及实现可视化
一、关于Fisher算法的主要思想与数学计算步骤已在上次博客中有讲到。
若不会清楚,请访问次链接
二、用scikit-learn库中也有LDA的函数,下面给出测试代码from sklearn import datasets, cross_validation,discriminant_analysis
###############################################################################
#用莺尾花数据集
def load_data():
iris=datasets.load_iris()
return cross_validation.train_test_split(iris.data,iris.target,test_size=0.25,random_state=0,stratify=iris.target)
#返回为: 一个元组,依次为:训练样本集、测试样本集、训练样本的标记、测试样本的标记
###############################################################################
def test_LinearDiscriminantAnalysis(*data):
x_train,x_test,y_train,y_test=data
lda=discriminant_analysis.LinearDiscriminantAnalysis()
lda.fit(x_train,y_train)
print('Coefficients:%s, intercept %s'%(lda.coef_,lda.intercept_))#输出权重向量和b
print('Score: %.2f' % lda.score(x_test, y_test))#测试集
print('Score: %.2f' % lda.score(x_train, y_train))#训练集
###############################################################################
x_train,x_test,y_train,y_test=load_data()
test_LinearDiscriminantAnalysis(x_train,x_test,y_train,y_test)
运行结果:

对比结果发现:原本的鸢尾花的测试集的预测准确度为100%,但经过分类器训练后,变成了97%也就是我们所说的训练集。
三、完成Iris数据集的 Fisher线性分类,及实现可视化
Fisher的种映射关系还有一种作用就是作为降维技术,称为监督降维技术(因为是有训练数据的,所以称为监督)
from sklearn import datasets, cross_validation,discriminant_analysis
###############################################################################
#用莺尾花数据集
def load_data():
iris=datasets.load_iris()
return cross_validation.train_test_split(iris.data,iris.target,test_size=0.25,random_state=0,stratify=iris.target)
#返回为: 一个元组,依次为:训练样本集、测试样本集、训练样本的标记、测试样本的标记
###############################################################################
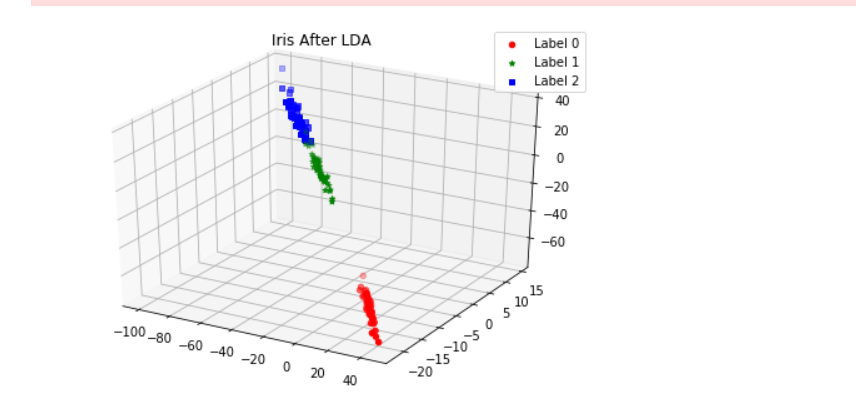
def plot_LDA(converted_X,y):
'''
绘制经过 LDA 转换后的数据
:param converted_X: 经过 LDA转换后的样本集
:param y: 样本集的标记
:return: None
'''
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig=plt.figure()
ax=Axes3D(fig)
colors='rgb'
markers='o*s'
for target,color,marker in zip([0,1,2],colors,markers):
pos=(y==target).ravel()
X=converted_X[pos,:]
ax.scatter(X[:,0], X[:,1], X[:,2],color=color,marker=marker,
label="Label %d"%target)
ax.legend(loc="best")
fig.suptitle("Iris After LDA")
plt.show()
###############################################################################
import numpy as np
x_train,x_test,y_train,y_test=load_data()
X=np.vstack((x_train,x_test))#沿着竖直方向将矩阵堆叠起来,把训练与测试的数据放一起来看
Y=np.vstack((y_train.reshape(y_train.size,1),y_test.reshape(y_test.size,1)))#沿着竖直方向将矩阵堆叠起来
lda = discriminant_analysis.LinearDiscriminantAnalysis()
lda.fit(X, Y)
converted_X=np.dot(X,np.transpose(lda.coef_))+lda.intercept_
plot_LDA(converted_X,Y)
运行结果:
 原创文章 47获赞 81访问量 6993
关注
私信
展开阅读全文
原创文章 47获赞 81访问量 6993
关注
私信
展开阅读全文
作者:w²大大