python-pyecharts 数据可视化学习 (数据来源:丁香园)
目录
一、数据准备
二、疫情地图
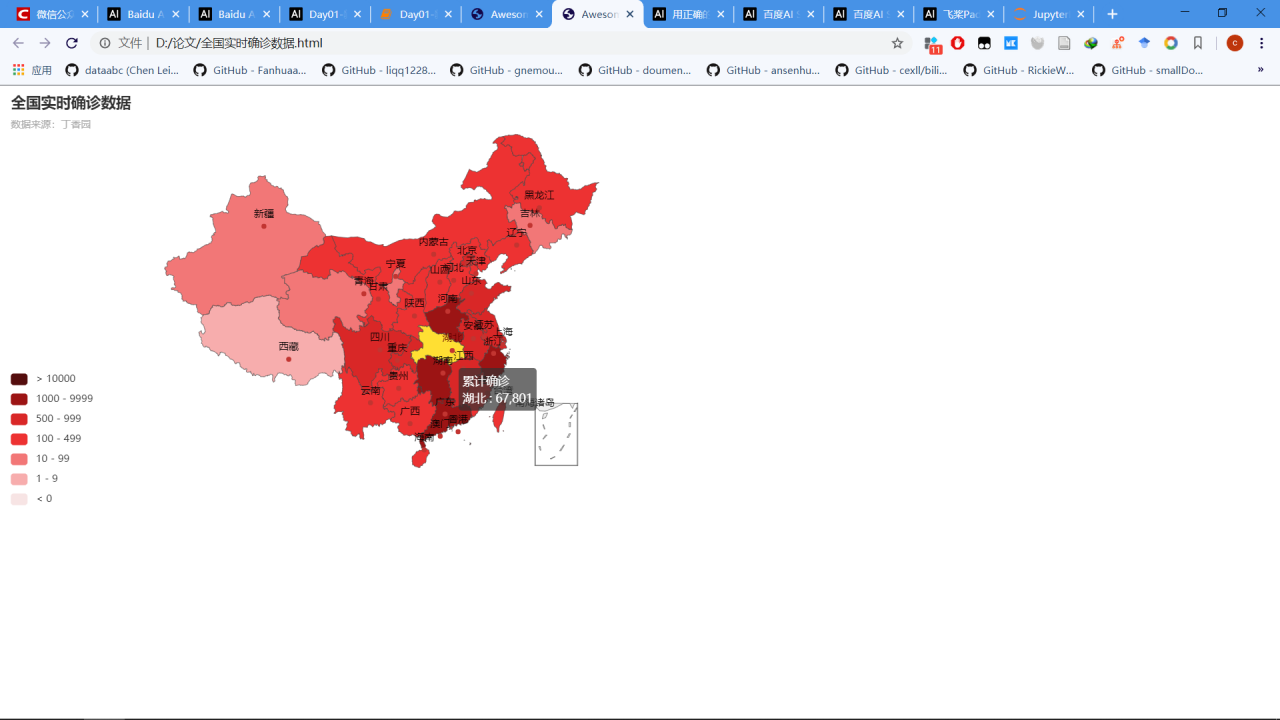
2.1全国疫情地图
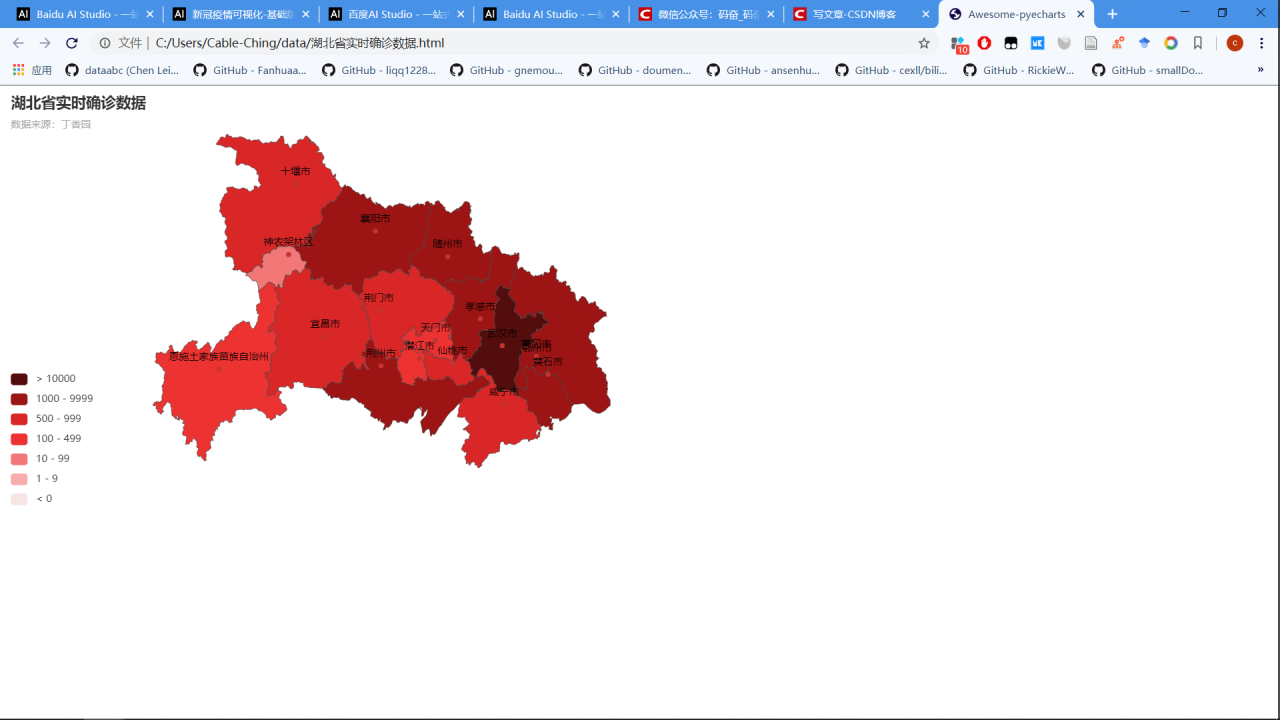
2.2湖北省疫情地图
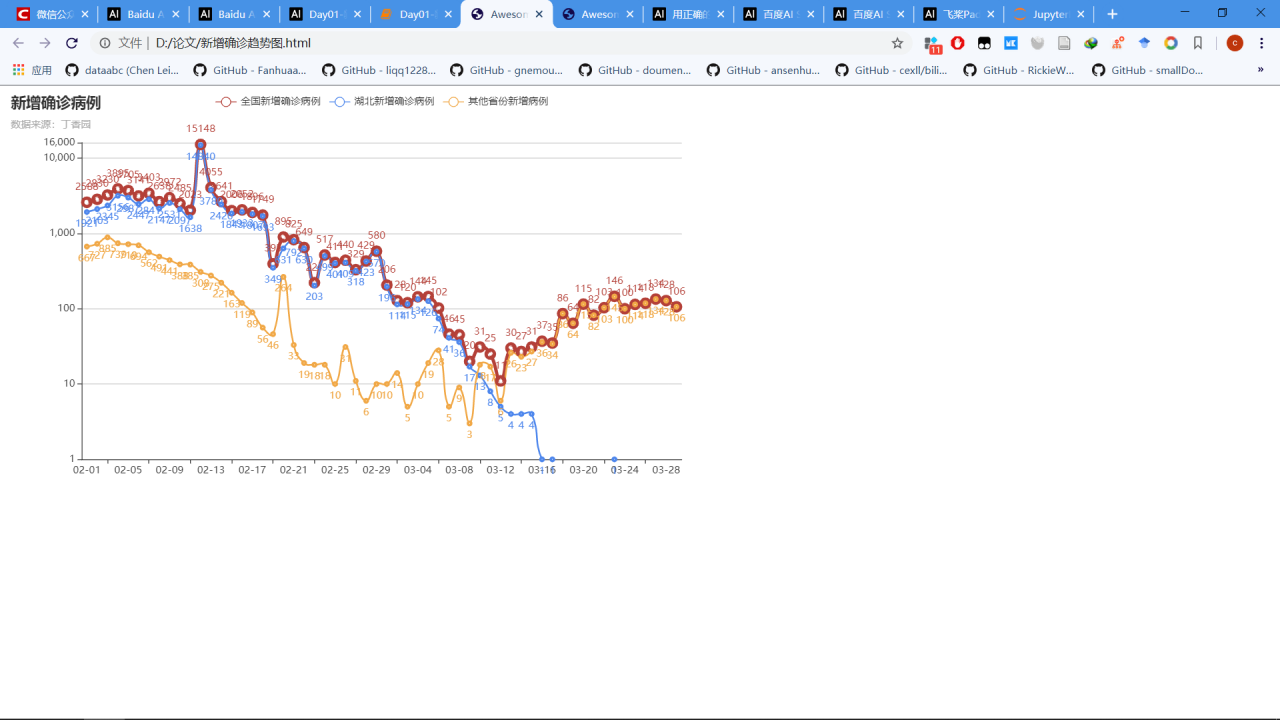
三、疫情增长趋势图
效果图
文件:pycharts_city.txt
爬取丁香园的数据保存
import json
import re
import requests
import datetime
today = datetime.date.today().strftime('%Y%m%d') #20200315
def crawl_dxy_data():
"""
爬取丁香园实时统计数据,保存到data目录下,以当前日期作为文件名,存JSON文件
"""
response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia') #request.get()用于请求目标网站
print(response.status_code) # 打印状态码
try:
url_text = response.content.decode() #更推荐使用response.content.deocde()的方式获取响应的html页面
#print(url_text)
url_content = re.search(r'window.getAreaStat = (.*?)}]}catch', #re.search():扫描字符串以查找正则表达式模式产生匹配项的第一个位置 ,然后返回相应的match对象。
url_text, re.S) #在字符串a中,包含换行符\n,在这种情况下:如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始;
#而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
texts = url_content.group() #获取匹配正则表达式的整体结果
content = texts.replace('window.getAreaStat = ', '').replace('}catch', '') #去除多余的字符
json_data = json.loads(content)
with open('data/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
except:
print('' % response.status_code)
def crawl_statistics_data():
"""
获取各个省份历史统计数据,保存到data目录下,存JSON文件
"""
with open('data/'+ today + '.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
statistics_data = {}
for province in json_array:
response = requests.get(province['statisticsData'])
try:
statistics_data[province['provinceShortName']] = json.loads(response.content.decode())['data']
except:
print(' for url: [%s]' % (response.status_code, province['statisticsData']))
with open("data/statistics_data.json", "w", encoding='UTF-8') as f:
json.dump(statistics_data, f, ensure_ascii=False)
if __name__ == '__main__':
crawl_dxy_data()
crawl_statistics_data()
二、疫情地图
2.1全国疫情地图
自行修改文件保存位置
import json
import datetime
from pyecharts.charts import Map
from pyecharts import options as opts
# 读原始数据文件
today = datetime.date.today().strftime('%Y%m%d') #20200315
datafile = 'data/'+ today + '.json'
with open(datafile, 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
# 分析全国实时确诊数据:'confirmedCount'字段
china_data = []
for province in json_array:
china_data.append((province['provinceShortName'], province['confirmedCount']))
china_data = sorted(china_data, key=lambda x: x[1], reverse=True) #reverse=True,表示降序,反之升序
print(china_data)
# 全国疫情地图
# 自定义的每一段的范围,以及每一段的特别的样式。
pieces = [
{'min': 10000, 'color': '#540d0d'},
{'max': 9999, 'min': 1000, 'color': '#9c1414'},
{'max': 999, 'min': 500, 'color': '#d92727'},
{'max': 499, 'min': 100, 'color': '#ed3232'},
{'max': 99, 'min': 10, 'color': '#f27777'},
{'max': 9, 'min': 1, 'color': '#f7adad'},
{'max': 0, 'color': '#f7e4e4'},
]
labels = [data[0] for data in china_data]
counts = [data[1] for data in china_data]
m = Map()
m.add("累计确诊", [list(z) for z in zip(labels, counts)], 'china')
#系列配置项,可配置图元样式、文字样式、标签样式、点线样式等
m.set_series_opts(label_opts=opts.LabelOpts(font_size=12),
is_show=False)
#全局配置项,可配置标题、动画、坐标轴、图例等
m.set_global_opts(title_opts=opts.TitleOpts(title='全国实时确诊数据',
subtitle='数据来源:丁香园'),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(pieces=pieces,
is_piecewise=True, #是否为分段型
is_show=True)) #是否显示视觉映射配置
#render()会生成本地 HTML 文件,默认会在当前目录生成 render.html 文件,也可以传入路径参数,如 m.render("mycharts.html")
m.render(path='/home/aistudio/data/全国实时确诊数据.html')
2.2湖北省疫情地图
import json
import datetime
from pyecharts.charts import Map
from pyecharts import options as opts
# 读原始数据文件
today = datetime.date.today().strftime('%Y%m%d') #20200315
datafile = 'data/'+ today + '.json'
with open(datafile, 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
# 分析湖北省实时确诊数据
# 读入规范化的城市名称,用于规范化丁香园数据中的城市简称
with open('/home/aistudio/data/data24815/pycharts_city.txt', 'r', encoding='UTF-8') as f:
defined_cities = [line.strip() for line in f.readlines()]
def format_city_name(name, defined_cities):
for defined_city in defined_cities:
if len((set(defined_city) & set(name))) == len(name):
name = defined_city
if name.endswith('市') or name.endswith('区') or name.endswith('县') or name.endswith('自治州'):
return name
return name + '市'
return None
province_name = '湖北'
for province in json_array:
if province['provinceName'] == province_name or province['provinceShortName'] == province_name:
json_array_province = province['cities']
hubei_data = [(format_city_name(city['cityName'], defined_cities), city['confirmedCount']) for city in
json_array_province]
hubei_data = sorted(hubei_data, key=lambda x: x[1], reverse=True)
print(hubei_data)
labels = [data[0] for data in hubei_data]
counts = [data[1] for data in hubei_data]
pieces = [
{'min': 10000, 'color': '#540d0d'},
{'max': 9999, 'min': 1000, 'color': '#9c1414'},
{'max': 999, 'min': 500, 'color': '#d92727'},
{'max': 499, 'min': 100, 'color': '#ed3232'},
{'max': 99, 'min': 10, 'color': '#f27777'},
{'max': 9, 'min': 1, 'color': '#f7adad'},
{'max': 0, 'color': '#f7e4e4'},
]
m = Map()
m.add("累计确诊", [list(z) for z in zip(labels, counts)], '湖北')
m.set_series_opts(label_opts=opts.LabelOpts(font_size=12),
is_show=False)
m.set_global_opts(title_opts=opts.TitleOpts(title='湖北省实时确诊数据',
subtitle='数据来源:丁香园'),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(pieces=pieces,
is_piecewise=True,
is_show=True))
m.render(path='/home/aistudio/data/湖北省实时确诊数据.html')
三、疫情增长趋势图
import numpy as np
import json
from pyecharts.charts import Line
from pyecharts import options as opts
# 读原始数据文件
datafile = 'data/statistics_data.json'
with open(datafile, 'r', encoding='UTF-8') as file:
json_dict = json.loads(file.read())
# 获取日期列表
dateId = [str(da['dateId'])[4:6] + '-' + str(da['dateId'])[6:8] for da in json_dict['湖北'] if
da['dateId'] >= 20200201]
# 分析各省份2月1日至今的新增确诊数据:'confirmedIncr'
statistics__data = {}
for province in json_dict:
statistics__data[province] = []
for da in json_dict[province]:
if da['dateId'] >= 20200201:
statistics__data[province].append(da['confirmedIncr'])
#若当天该省数据没有更新,则默认为0
if(len(statistics__data[province])!=len(dateId)):
statistics__data[province].append(0)
# 全国新增趋势
all_statis = np.array([0] * len(dateId))
for province in statistics__data:
all_statis = all_statis + np.array(statistics__data[province])
all_statis = all_statis.tolist()
# 湖北新增趋势
hubei_statis = statistics__data['湖北']
# 湖北以外的新增趋势
other_statis = [all_statis[i] - hubei_statis[i] for i in range(len(dateId))]
line = Line()
line.add_xaxis(dateId)
line.add_yaxis("全国新增确诊病例", #图例
all_statis, #数据
is_smooth=True, #是否平滑曲线
linestyle_opts=opts.LineStyleOpts(width=4, color='#B44038'),#线样式配置项
itemstyle_opts=opts.ItemStyleOpts(color='#B44038', #图元样式配置项
border_color="#B44038", #颜色
border_width=10)) #图元的大小
line.add_yaxis("湖北新增确诊病例", hubei_statis, is_smooth=True,
linestyle_opts=opts.LineStyleOpts(width=2, color='#4E87ED'),
label_opts=opts.LabelOpts(position='bottom'), #标签在折线的底部
itemstyle_opts=opts.ItemStyleOpts(color='#4E87ED',
border_color="#4E87ED",
border_width=3))
line.add_yaxis("其他省份新增病例", other_statis, is_smooth=True,
linestyle_opts=opts.LineStyleOpts(width=2, color='#F1A846'),
label_opts=opts.LabelOpts(position='bottom'), #标签在折线的底部
itemstyle_opts=opts.ItemStyleOpts(color='#F1A846',
border_color="#F1A846",
border_width=3))
line.set_global_opts(title_opts=opts.TitleOpts(title="新增确诊病例", subtitle='数据来源:丁香园'),
yaxis_opts=opts.AxisOpts(max_=16000, min_=1, type_="log", #坐标轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),#分割线配置项
axisline_opts=opts.AxisLineOpts(is_show=True)))#坐标轴刻度线配置项
line.render(path='/home/aistudio/data/新增确诊趋势图.html')
作者:码奋