[小白系列]Python基本数据结构从入门到不放弃,这边看过来
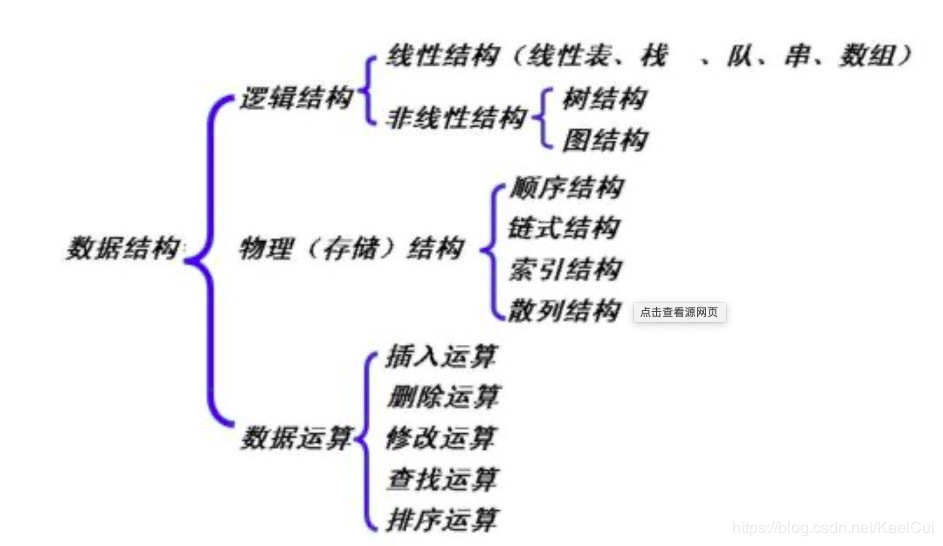 1.列表(list)
列表是最常用的Python数据类型
数据项不需要具有相同的类型
1.1创建列表
1.列表(list)
列表是最常用的Python数据类型
数据项不需要具有相同的类型
1.1创建列表
列表最明显的标志就是数据项之间以英文逗号(,)隔开,整个列表用中括号[]包围。
['小明', 22, '中国']
ls_1 = list() #创建一个空列表
ls_2 = [] #创建一个列表
ls_3 = [1, 3, 12.3, 'apple', 0.001] #创建非空列表
需要为列表声明变量类型吗?
#查看数据类型
type(ls_1)
list
ls_3
[1, 3, 12.3, 'apple', 0.001]
列表中居然可以混合不同类型数据????!!!!!
从左至右为:0, 1, 2,…
从右至左为:-1, -2, -3,…
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Bkrti5VI-1586437860541)(attachment:list_index.jpg)]
1.3访问列表值 list[index]print (ls_3)
print (ls_3[0]) #打印列表ls_3 的第一项
print (ls_3[-2]) #打印列表ls_3 的倒数第二项
[1, 3, 12.3, 'apple', 0.001]
1
apple
切记:中括号,否则会。。。。。
print(ls_3(0))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
----> 1 print(ls_3(0))
TypeError: 'list' object is not callable
1.4 切片 list[first_index : last_index+1]
print (ls_3)
print (ls_3[:]) #打印列表ls_3 的所有项
print (ls_3[1:3]) #打印列表ls_3 的第2 项到第3 项
print (ls_3[2:]) #打印列表ls_3 第三项及之后所有项
[1, 3, 12.3, 'apple', 0.001]
[1, 3, 12.3, 'apple', 0.001]
[3, 12.3]
[12.3, 'apple', 0.001]
注意: 切片结果依然是一个列表
1.5 python列表脚本操作符[1, 2,]+[2, 3] #列表组合
[1, 2, 2, 3]
[1]*3 #列表元素重复
[1, 1, 1]
# *运算符可以用于字符创,计算结果就是字符创重复指定次数的结果
'*'*50
'**************************************************'
print(ls_3)
print("apple" in ls_3 ) #判断数据是否在列表中
print('999 ' in ls_3)
[1, 3, 12.3, 'apple', 0.001]
True
False
1.6 列表函数 fun(list)
len(ls_3) #返回列表长度
5
max([1, 5, 65, 5]) #返回列表最大值
65
min([1, -1, 89]) #返回列表最小值
-1
1.7 列表方法
ls_3
[1, 3, 12.3, 'apple', 0.001]
ls_3.append("apple") #在列表结尾添加新元素
print(ls_3)
[1, 3, 12.3, 'apple', 0.001, 'apple']
ls_3.count("apple") #统计列表ls_3 中元素“apple” 的数目
2
ls_3.extend([1, 2, 3]) #在列表ls_3 结尾添加另一个列表[1, 2, 3]的元素
print (ls_3)
[1, 3, 12.3, 'apple', 0.001, 'apple', 1, 2, 3]
ls_3.index("apple") #从列表ls_3 中找出"apple" 第一个匹配项的索引位置
3
print(ls_3)
ls_3.insert(2,"apple") #在索引为2 的位置插入元素 “apple”
print(ls_3)
[1, 3, 12.3, 'apple', 0.001, 'apple', 1, 2, 3]
[1, 3, 'apple', 12.3, 'apple', 0.001, 'apple', 1, 2, 3]
print(ls_3)
a=ls_3.pop(-1) #移除列表ls_3 中索引为-1 (即最后一个)元素, 并将该元素赋值给变量 a
print(a)
print(ls_3)
[1, 3, 'apple', 12.3, 'apple', 0.001, 'apple', 1, 2, 3]
3
[1, 3, 'apple', 12.3, 'apple', 0.001, 'apple', 1, 2]
print(ls_3)
b=ls_3.remove("apple") #移除列表ls_3 中的第一个“apple” ,并将该元素赋值给变量 b
print(b)
print(ls_3)
[1, 3, 'apple', 12.3, 'apple', 0.001, 'apple', 1, 2]
None
[1, 3, 12.3, 'apple', 0.001, 'apple', 1, 2]
print(b) 运行结果为None, 这是因为***remove方法没有返回值***
pop 与 remove 对比
pop 移除的是***索引位置对应的元素***,即需要提供元素位置,同时***返回该元素值***
remove 移除的是列表中***第一个匹配的元素***,即需提供要移除的元素值,并且***没有返回值***
print(ls_3)
ls_3.reverse() #反向列表ls_3
print(ls_3)
[1, 3, 12.3, 'apple', 0.001, 'apple', 1, 2]
[2, 1, 'apple', 0.001, 'apple', 12.3, 3, 1]
print(ls_3)
ls_3.sort() #对列表ls_3 进行从小到大排序
print(ls_3)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in
----> 1 print(ls_3)
2 ls_3.sort() #对列表ls_3 进行从小到大排序
3 print(ls_3)
4 ls_3.sort(reverse = True)
NameError: name 'ls_3' is not defined
sort 方法仅能用在***全数值型***列表中
ls_4 = [2, 1, 4.5, 55, 0.001]
print(ls_4)
ls_4.sort() #对列表ls_4 进行从小到大排序
print(ls_4)
# 采用这个方法可以实现降序排列
ls_4.sort(reverse = True)
print(ls_4)
[2, 1, 4.5, 55, 0.001]
[0.001, 1, 2, 4.5, 55]
[55, 4.5, 2, 1, 0.001]
ls_4 = [2, 1, 4.5, 55, 0.001]
print(ls_4)
ls_4.sort()#对列表ls_4 进行从小到大排序
ls_4.reverse()
print(ls_4)
[2, 1, 4.5, 55, 0.001]
[55, 4.5, 2, 1, 0.001]
2. 元组(tuple)
元组的元素***不能修改***
2.1 创建元组元组中元素使用英文逗号(,)隔开,整个元组用小括号()包围。
tup_0 = tuple() #创建空元组
tup_1 = () #创建空元组
tup_2 = (1, ) #创建只包含一个元素的元组,注意要有逗号
tup_3 = (1, 3, "apple", 66) #创建多元素元组
与列表类似,元组索引从 0 开始,也可以使用 -1, -2…
2.2 获取元组值print(tup_3)
print(tup_3[0])
print(tup_3[-2])
print(tup_3[1:3])
(1, 3, 'apple', 66)
1
apple
(3, 'apple')
2.3 元组操作
元组值不能改变,但可以对元组进行拼接形成新元组,或者删除整个元组
print(tup_2)
print(tup_3)
tup_4 = tup_2 + tup_3
print(tup_4)
(1,)
(1, 3, 'apple', 66)
(1, 1, 3, 'apple', 66)
print(tup_4)
del(tup_4)
print(tup_4)
(1, 1, 3, 'apple', 66)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in
1 print(tup_4)
2 del(tup_4)
----> 3 print(tup_4)
NameError: name 'tup_4' is not defined
2.4 元组脚本操作符
同样包括: +, *, in
与列表类似,不再做赘述
2.5 元组函数同样包括: len(), max(), min()
与列表类似,不再做赘述
3. 字典(dictionary)字典元素可变,可存储任意类型对象
3.1 创建字典字典中的元素为 key:value 对,每对 key:value 用英文逗号隔开,整个字典用大括号{}包围
dict_0 = dict() #创建空字典
dict_1 = {} #创建空字典
dict_2 = {"name": "张三", "age": 19, 66: "六十六"} #创建字典
3.2 获取字典值
dict_2
{'name': '张三', 'age': 19, 66: '六十六'}
print(dict_2["name"])
张三
list(dict_2)
['name', 'age', 66]
3.3 修改字典
print(dict_2)
dict_2["age"]=30 #将键 age 的值更新为30
print(dict_2)
dict_2["hobby"] = "eat" #给字典dict_2 中增加 "hobby":"eat" 键-值对
print(dict_2)
del dict_2["hobby"] #删除字典dict_t 中键为"hobby" 的键-值对
print(dict_2)
{'name': '张三', 'age': 19, 66: '六十六'}
{'name': '张三', 'age': 30, 66: '六十六'}
{'name': '张三', 'age': 30, 66: '六十六', 'hobby': 'eat'}
{'name': '张三', 'age': 30, 66: '六十六'}
3.4 字典内置函数
print(len(dict_2)) #len() 键-值对数目
print(list(dict_2)) #list(dic) 以列表形式输出所有键
print(str(dict_2)) #str(dic) 输出字典可打印的字符串表示
3
['name', 'age', 66]
{'name': '张三', 'age': 30, 66: '六十六'}
3.5 字典方法
运行 help(dict)查看详情
help(dict)
Help on class dict in module builtins:
class dict(object)
| dict() -> new empty dictionary
| dict(mapping) -> new dictionary initialized from a mapping object's
| (key, value) pairs
| dict(iterable) -> new dictionary initialized as if via:
| d = {}
| for k, v in iterable:
| d[k] = v
| dict(**kwargs) -> new dictionary initialized with the name=value pairs
| in the keyword argument list. For example: dict(one=1, two=2)
|
| Methods defined here:
|
| __contains__(self, key, /)
| True if the dictionary has the specified key, else False.
|
| __delitem__(self, key, /)
| Delete self[key].
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(...)
| x.__getitem__(y) x[y]
|
| __gt__(self, value, /)
| Return self>value.
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self size of D in memory, in bytes
|
| clear(...)
| D.clear() -> None. Remove all items from D.
|
| copy(...)
| D.copy() -> a shallow copy of D
|
| get(self, key, default=None, /)
| Return the value for key if key is in the dictionary, else default.
|
| items(...)
| D.items() -> a set-like object providing a view on D's items
|
| keys(...)
| D.keys() -> a set-like object providing a view on D's keys
|
| pop(...)
| D.pop(k[,d]) -> v, remove specified key and return the corresponding value.
| If key is not found, d is returned if given, otherwise KeyError is raised
|
| popitem(...)
| D.popitem() -> (k, v), remove and return some (key, value) pair as a
| 2-tuple; but raise KeyError if D is empty.
|
| setdefault(self, key, default=None, /)
| Insert key with a value of default if key is not in the dictionary.
|
| Return the value for key if key is in the dictionary, else default.
|
| update(...)
| D.update([E, ]**F) -> None. Update D from dict/iterable E and F.
| If E is present and has a .keys() method, then does: for k in E: D[k] = E[k]
| If E is present and lacks a .keys() method, then does: for k, v in E: D[k] = v
| In either case, this is followed by: for k in F: D[k] = F[k]
|
| values(...)
| D.values() -> an object providing a view on D's values
|
| ----------------------------------------------------------------------
| Class methods defined here:
|
| fromkeys(iterable, value=None, /) from builtins.type
| Create a new dictionary with keys from iterable and values set to value.
|
| ----------------------------------------------------------------------
| Static methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __hash__ = None
dict_2.items()
dict_items([('name', '张三'), ('age', 30), (66, '六十六')])
dict_2.keys()
dict_2.values()
4. 集合(set)
集合(set)是一个无序的不重复元素序列
4.1 创建集合可以使用set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典,对于非空集合可以采用{}来实现
s_1 = { 'orange', 'pear', 'orange', 'banana'}
print(s_1) # 这里演示的是去重功能
{'pear', 'banana', 'orange'}
'orange' in s_1 # 快速判断元素是否在集合内
True
a = set('abracadabra')
b = set('alacazam')
print(a,'\n',b)
a - b # 集合a中包含而集合b中不包含的元素
{'a', 'c', 'r', 'd', 'b'}
{'a', 'c', 'm', 'l', 'z'}
{'b', 'd', 'r'}
print(a,'\n',b)
a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b'}
{'a', 'c', 'm', 'l', 'z'}
{'a', 'b', 'c', 'd', 'l', 'm', 'r', 'z'}
print(a,'\n',b)
a & b # 集合a和b中都包含了的元素
{'a', 'c', 'r', 'd', 'b'}
{'a', 'c', 'm', 'l', 'z'}
{'a', 'c'}
print(a,'\n',b)
a ^ b # 位运算符,或者称为异或
{'a', 'c', 'r', 'd', 'b'}
{'a', 'c', 'm', 'l', 'z'}
{'b', 'd', 'l', 'm', 'r', 'z'}
4.2 集合的基本操作
print(s_1)
{'orange', 'pear', 'banana'}
s_1.add('apple') #添加一个元素
s_1
{'apple', 'banana', 'orange', 'pear'}
s_1.update([1,2,3]) #添加多个元素
s_1
{1, 2, 3, 'apple', 'banana', 'orange', 'pear'}
print(s_1)
s_1.update([1,2],['dfsf','sdfa'])
s_1
{1, 2, 3, 'pear', 'banana', 'orange', 'apple'}
{1, 2, 3, 'apple', 'banana', 'dfsf', 'orange', 'pear', 'sdfa'}
注意对比
去重 4.3 移除元素#s.remove(x)
print(s_1)
s_1.remove('apple')
print(s_1)
{1, 2, 3, 'pear', 'sdfa', 'banana', 'orange', 'apple', 'dfsf'}
{1, 2, 3, 'pear', 'sdfa', 'banana', 'orange', 'dfsf'}
#s.discard( x )
print(s_1)
s_1.discard('pear')
print(s_1)
{1, 2, 3, 'pear', 'sdfa', 'banana', 'orange', 'dfsf'}
{1, 2, 3, 'sdfa', 'banana', 'orange', 'dfsf'}
注意:区别 来了
'apple' in s_1
False
s_1.remove('apple')
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
in
----> 1 s_1.remove('apple')
KeyError: 'apple'
s_1.discard('apple')
当删除的元素不存在时
remove会报错 discard不会报错#s.pop()随机删除元素
print(s_1)
s_pop = s_1.pop()
print(s_pop)
print(s_1)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in
1 #s.pop()随机删除元素
----> 2 print(s_1)
3 s_pop = s_1.pop()
4 print(s_pop)
5 print(s_1)
NameError: name 's_1' is not defined
真的随机吗?
print(s_1)
{2, 3, 'sdfa', 'banana', 'orange', 'dfsf'}
for i in range(5):
print(s_1)
s_pop = s_1.pop()
print(s_pop)
print(s_1)
s_1.add(s_pop)
print(s_1)
print('*********')
{2, 3, 'sdfa', 'banana', 'orange', 'dfsf'}
2
{3, 'sdfa', 'banana', 'orange', 'dfsf'}
{3, 2, 'sdfa', 'banana', 'orange', 'dfsf'}
*********
{3, 2, 'sdfa', 'banana', 'orange', 'dfsf'}
3
{2, 'sdfa', 'banana', 'orange', 'dfsf'}
{3, 2, 'sdfa', 'banana', 'orange', 'dfsf'}
*********
{3, 2, 'sdfa', 'banana', 'orange', 'dfsf'}
2
{3, 'sdfa', 'banana', 'orange', 'dfsf'}
{3, 2, 'sdfa', 'banana', 'orange', 'dfsf'}
*********
{3, 2, 'sdfa', 'banana', 'orange', 'dfsf'}
sdfa
{3, 2, 'banana', 'orange', 'dfsf'}
{3, 2, 'sdfa', 'banana', 'orange', 'dfsf'}
*********
{3, 2, 'sdfa', 'banana', 'orange', 'dfsf'}
banana
{3, 2, 'sdfa', 'orange', 'dfsf'}
{3, 2, 'sdfa', 'banana', 'orange', 'dfsf'}
*********
set 集合的 pop 方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除
help(set)
Help on class set in module builtins:
class set(object)
| set() -> new empty set object
| set(iterable) -> new set object
|
| Build an unordered collection of unique elements.
|
| Methods defined here:
|
| __and__(self, value, /)
| Return self&value.
|
| __contains__(...)
| x.__contains__(y) y in x.
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __gt__(self, value, /)
| Return self>value.
|
| __iand__(self, value, /)
| Return self&=value.
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __ior__(self, value, /)
| Return self|=value.
|
| __isub__(self, value, /)
| Return self-=value.
|
| __iter__(self, /)
| Implement iter(self).
|
| __ixor__(self, value, /)
| Return self^=value.
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self size of S in memory, in bytes
|
| __sub__(self, value, /)
| Return self-value.
|
| __xor__(self, value, /)
| Return self^value.
|
| add(...)
| Add an element to a set.
|
| This has no effect if the element is already present.
|
| clear(...)
| Remove all elements from this set.
|
| copy(...)
| Return a shallow copy of a set.
|
| difference(...)
| Return the difference of two or more sets as a new set.
|
| (i.e. all elements that are in this set but not the others.)
|
| difference_update(...)
| Remove all elements of another set from this set.
|
| discard(...)
| Remove an element from a set if it is a member.
|
| If the element is not a member, do nothing.
|
| intersection(...)
| Return the intersection of two sets as a new set.
|
| (i.e. all elements that are in both sets.)
|
| intersection_update(...)
| Update a set with the intersection of itself and another.
|
| isdisjoint(...)
| Return True if two sets have a null intersection.
|
| issubset(...)
| Report whether another set contains this set.
|
| issuperset(...)
| Report whether this set contains another set.
|
| pop(...)
| Remove and return an arbitrary set element.
| Raises KeyError if the set is empty.
|
| remove(...)
| Remove an element from a set; it must be a member.
|
| If the element is not a member, raise a KeyError.
|
| symmetric_difference(...)
| Return the symmetric difference of two sets as a new set.
|
| (i.e. all elements that are in exactly one of the sets.)
|
| symmetric_difference_update(...)
| Update a set with the symmetric difference of itself and another.
|
| union(...)
| Return the union of sets as a new set.
|
| (i.e. all elements that are in either set.)
|
| update(...)
| Update a set with the union of itself and others.
|
| ----------------------------------------------------------------------
| Static methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __hash__ = None
作者:GRIT_Kael