机器学习“傻瓜式”理解(4)KNN算法(数据处理以及超参数)
首先我们需要了解到,我们在进行机器学习的过程中寻求的不是让训练处的在现有的数据集上达到最佳,而是我们需要让其在真实环境中达到最佳的效果。在上一节中我们将全部的数据集全部用于训练模型中,对于我们所训练出的模型无法知道其具体的准确度便投入真实环境使用,这样的做法极具风险性,而且我们也不推荐。
解决方案:机器学习最常用的解决方案便是实现测试集和训练集的相互分离(此方法仍具有局限性,后续会补充)。具体的操作方式是:将全部数据集的80%当做训练数据集,训练出来模型后我们通过另外20%的数据(称其为测试数据集)来验证所训练出来模型的准确度。
实现代码封装:
import numpy as np
def train_test_split(X,y,test_train = 0.2,seed = None):
'''check'''
assert X.shape[0] == y.shape[0],\
"the size must be valid"
assert 0.0 <= test_train <= 1.0,\
"the ratio must be in 0-1"
if seed:
np.random.seed(seed)
shuffle_index= np.random.permutation(len(X))
test_ratio = test_train
test_size = int(len(X) * test_ratio)
test_indexes = X[:test_size]
train_indxes = X[test_size:]
X_train = X[train_indxes]
X_test = X[test_indexes]
y_train = y[train_indxes]
y_test = y[test_indexes]
return X_train,X_test,y_train,y_test
KNN中的超参数:
首先明确一个概念,何为超参数?我们需要在机器学习中传入的参数便是指的是超参数。KNN中的超参数便是K,这是KNN中我们需要关注的第一个超参数。
思考一个问题,加上K=3,距离最近的三个点之间的每个类别占1/3,我们如何确定是属于哪一个类别?如同下图所示:
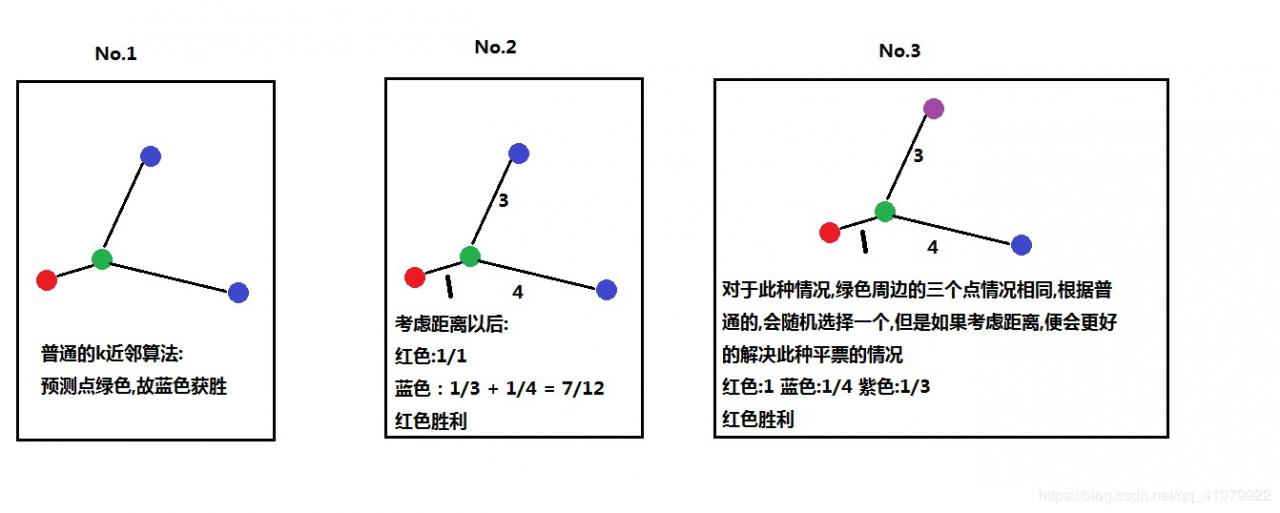
如上我们便引出了第二个超参数weights.
另外,我们在计算预测点和我们数据点之间的距离时使用的是欧拉距离,但是观察下图后你会发现:
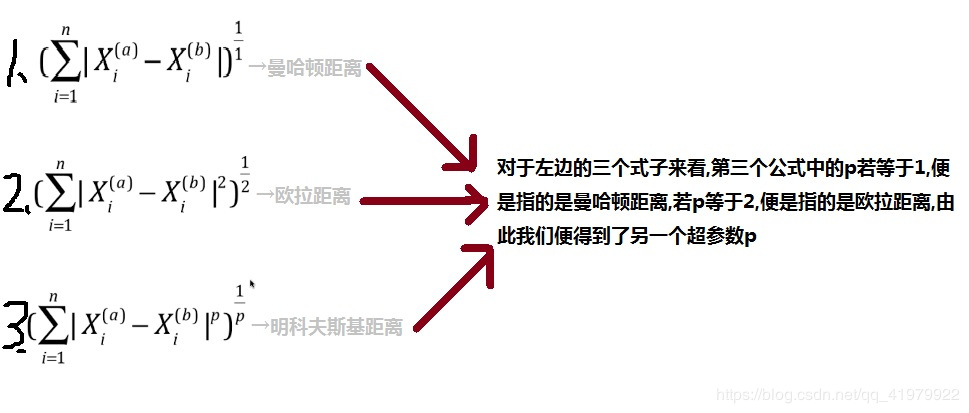
我们便得到了超参数p。
有两个解决方案:
①我们可以采用经验数值,例如KNN算法中我们使用经验数值K=5,
②网格搜索策略寻找最优参数。
问题:何为最好的超参数?
我们需要一个评判标准,分类算法的评判标准便是模型准确度(accuracy)。
其实现代码如下:(在库中metrics中)
import numpy as np
def accuracy_score(y_true,y_predict):
'''check'''
assert y_true.shape[0] == y_predict.shape[0],\
"the size must be valid"
return int((np.sum(y_true == y_predict) / len(y_true)) * 100)
使用sklearn中提供的真实数据集,通过网格搜索实现寻找最优的超参数:
1.手动寻找
先进行数据的处理:
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
'''使用sklearn的手写数字集'''
digits = datasets.load_digits()
X = digits.data
y = digits.target
X_train,X_test,y_train,y_test = train_test_split(X,y)
分为两种情况:
①寻找最优的超参数K和method(即是否考虑权重信息)
from sklearn.neighbors import KNeighborsClassifier
best_k = -1
best_score = 0.0
best_method = ""
best_p = ""
'''1.寻找最优的超参数K和weight'''
'''uniform:不考虑预测点与数据点的距离,distance正好相反'''
for method in ["uniform","distance"]:
for k in range(1,11):
knn_cif = KNeighborsClassifier(n_neighbors = k)
knn_cif.fit(X_train,y_train)
knn_score = knn_cif.score(X_test,y_test)
if knn_score > best_score:
best_score = knn_score
best_k = k
best_method = method
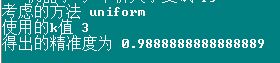
'''得出结果'''
print("考虑的方法",best_method)
print("使用的k值",best_k)
print("得出的精准度为",best_score)
运行结果如下:
②寻找最优的超参数K和P(此时不需要考虑method,因为若需要考虑P,则默认method=‘distance’)
for k in range(1,11):
for p in range(1,6):
knn_cif = KNeighborsClassifier(n_neighbors = k,weights="distance",p = p)
knn_cif.fit(X_train,y_train)
knn_score = knn_cif.score(X_test,y_test)
if knn_score > best_score:
best_score = knn_score
best_k = k
best_p = p
'''得出结果'''
print("考虑的P值",best_p)
print("使用的k值",best_k)
print("得出的精准度为",best_score)
运行结果如下:

补充:
模型参数:我们在机器学习过程中学到的参数,KNN算法中是没有模型参数的,后面我们讲到的线性回归和逻辑回归具有模型参数。
from sklearn.model_selection import GridSearchCV
param_grid = [
{
'weights':['uniform'],
'n_neighbors':[i for i in range(1,11)]
},
{
'weights':['distance'],
'n_neighbors':[i for i in range(1,11)],
'p':[ i for i in range(1,6)]
}
]
knn_cif = KNeighborsClassifier()
'''
参数介绍:n_jobs,使用处理的电脑内核的个数,默认为1,表示使用一个内核,为-1表示使用全部内核
verbose:表示学习过程中输出信息,一般为2,数越大,输出信息越详细
'''
grid_search = GridSearchCV(knn_cif,param_grid,n_jobs = -1,verbose = 2)
grid_search.fit(X_train,y_train)
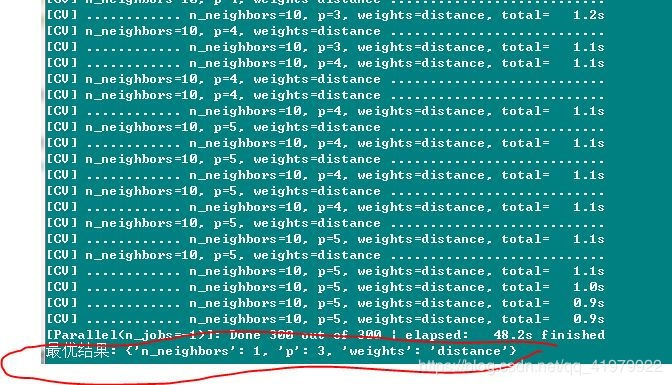
print("最优结果:",grid_search.best_params_)
运行过程以及结果显示:
我这里不长篇大论概述,我绘制了一张图,通过下图便可初步了解数据的归一化:
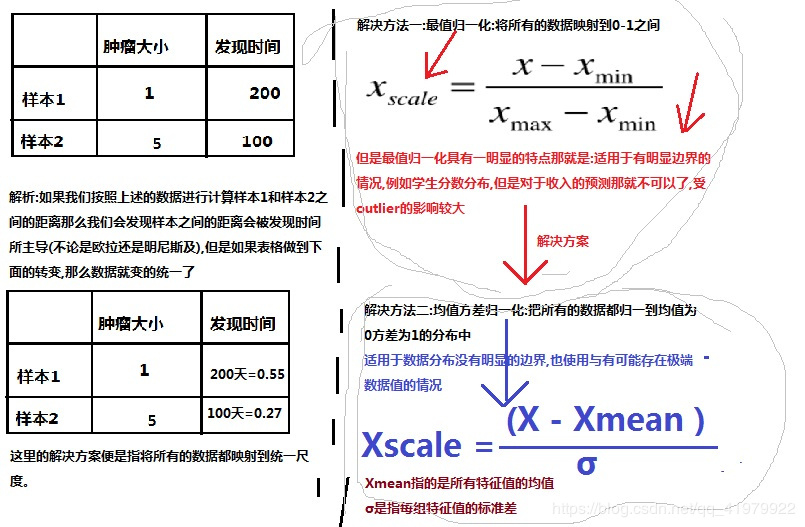

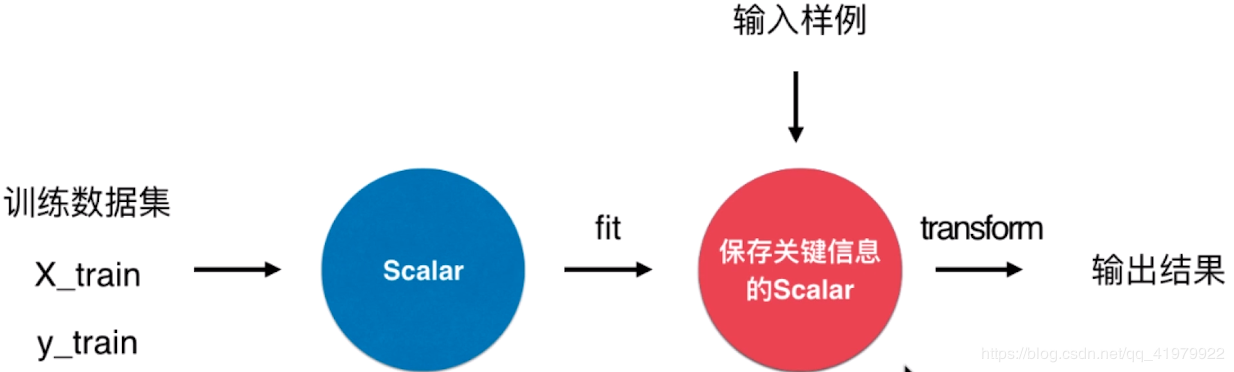
Sklearn中的归一化处理:
分为两个步骤:fit->tranform
归一化的封装代码:
import numpy as np
class StandardScaler:
def __init__(self):
self.mean_ = None
self.std_ = None
def fit(self,X):
'''according to X get mean and std'''
'''check'''
assert X.ndim == 2,"the dimension must be 2"
self.mean_ = np.array([np.mean[:,i] for i in range(0,X.shape[1])])
self.std_ = np.array([np.std[:,i] for i in range(0,X.shape[1])])
return self
def transform(self,X):
'''check'''
assert self.mean_ is not None and self.std_ is not None,\
"fit before transform"
assert X.ndim == 2,"the dimension must be 2"
assert X.shape[1] == len(self.mean_),\
"the value must be valid"
resX = np.empty(shape=X.shape,dtype=float)
for col in range(X.shape[1]):
resX[:,col] = (X[:,col] - self.mean_[col]) / self.std_[col]
return resX
sklearn中的使用和封装类似
总结:
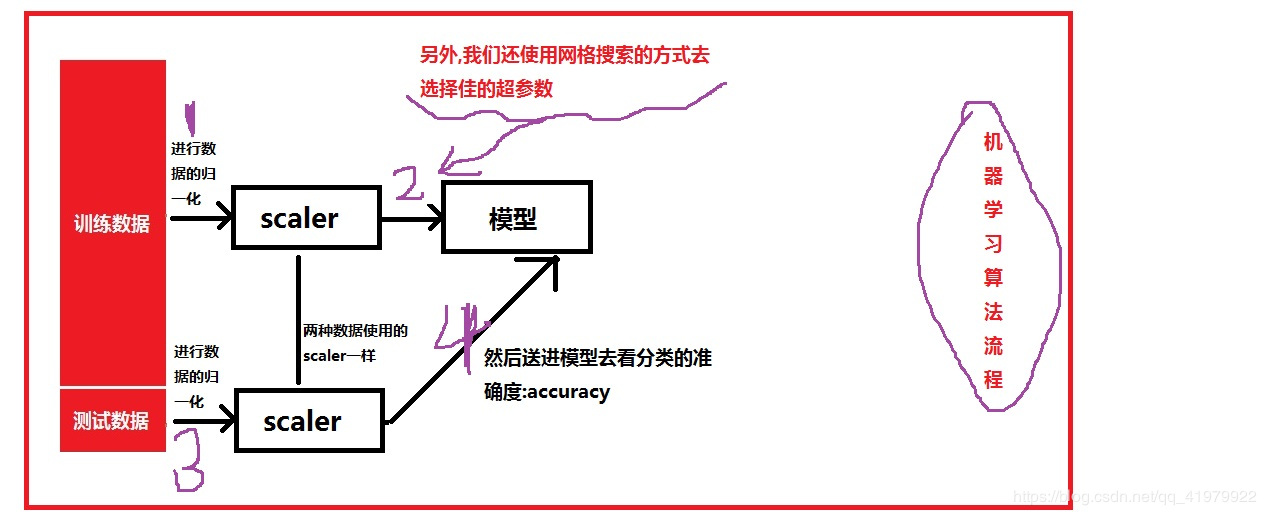
作者:崔振凯