爬虫小案例:适合Python零基础、对爬虫数据采集感兴趣的同学!
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
小的时候心中总有十万个为什么类似的问题,今天带大家爬取一个问答类的网站,本堂课使用正则表达式对文本类的数据进行提取,正则表达式是数据提取的通用方法。
适合人群:
Python零基础、对爬虫数据采集感兴趣的同学!
环境介绍:
python 3.6
pycharm
requests
re
json
爬虫的一般思路
1、确定爬取的url路径,headers参数
2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
3、解析数据 -- re模块:提供全部的正则表达式功能
4、保存数据 -- 保存json格式的数据
1、确定爬取的url路径,headers参数

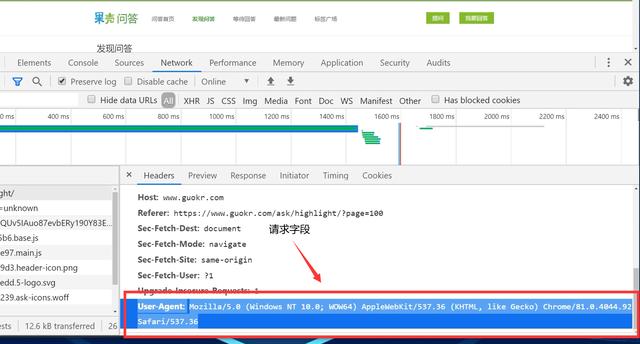
base_url = 'https://www.guokr.com/ask/highlight/?page={}'.format(str(page))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据

response = requests.get(base_url, headers=headers)
data = response.text
# print(data)
3、解析数据 -- re模块:提供全部的正则表达式功能
编译正则表达式 预编译的代码对象比直接使用字符串要快,因为解释器在执行字符串形式的代码前都推荐大家把字符串编译成代码对象
pattern = re.compile('(.*?)
', re.S)
pattern_list = pattern.findall(data) # -->list
# print(pattern_list)
# json [{[]}]{}
# 构建json数据格式
for i in pattern_list:
data_dict = {}
data_dict['title'] = i[1]
data_dict['href'] = i[0]
data_list.append(data_dict)
# 转换成json格式
# json.dumps 序列化时对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False:
json_data_list = json.dumps(data_list, ensure_ascii=False)
# print(json_data_list)
with open("guoke02.json", 'w', encoding='utf-8') as f:
f.write(json_data_list)
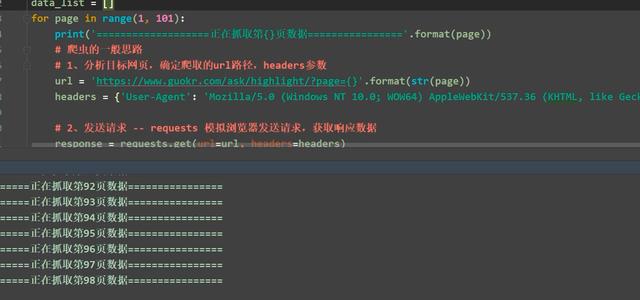

4、保存json格式的文件

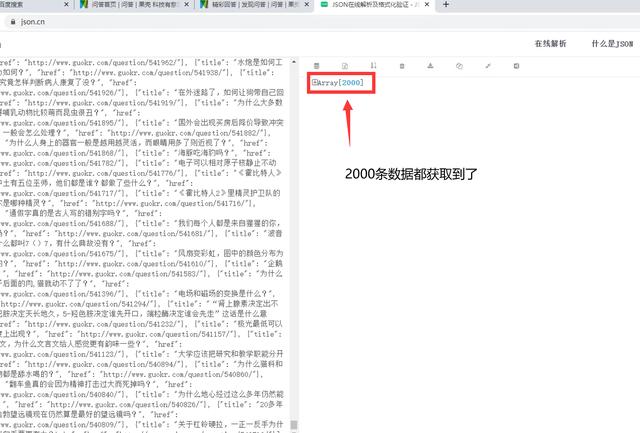
每页20条数据,共100页,2000条数据~
如果你处于想学Python或者正在学习Python,Python的教程不少了吧,但是是最新的吗?说不定你学了可能是两年前人家就学过的内容,在这小编分享一波2020最新的Python教程。获取方式,私信小编 “ 资料 ”,即可免费获取哦!
完整代码如下:
# requests
# re
# json
# 爬虫的一般思路
# 1、确定爬取的url路径,headers参数
# 2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
# 3、解析数据 -- re模块:提供全部的正则表达式功能
# 4、保存数据 -- 保存json格式的数据
import requests # pip install requests
import re
import json
# 1、确定爬取的url路径,headers参数
base_url = 'https://www.guokr.com/ask/highlight/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# 2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
response = requests.get(base_url, headers=headers)
data = response.text
# print(data)
# 3、解析数据 -- re模块:提供全部的正则表达式功能
# 印度人把男人的生殖器叫林伽,把女人的生殖器叫瑜尼,林伽和瑜尼的交合,便是瑜伽。这是真还是假的
# 3、1 编译正则表达式 预编译的代码对象比直接使用字符串要快,因为解释器在执行字符串形式的代码前都必须把字符串编译成代码对象
pattern = re.compile('(.*?)
', re.S)
pattern_list = pattern.findall(data) # -->list
# print(pattern_list)
# json [{[]}]{}
# 构建json数据格式
data_list = []
for i in pattern_list:
data_dict = {}
data_dict['title'] = i[1]
data_dict['href'] = i[0]
data_list.append(data_dict)
# 转换成json格式
# json.dumps 序列化时对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False:
json_data_list = json.dumps(data_list, ensure_ascii=False)
print(json_data_list)
# 保存json格式的文件
with open("guoke01.json", 'w', encoding='utf-8') as f:
f.write(json_data_list)
 其实还好啦
其实还好啦
 原创文章 167获赞 111访问量 2万+
关注
私信
展开阅读全文
原创文章 167获赞 111访问量 2万+
关注
私信
展开阅读全文
作者:其实还好啦