数据采集及可视化实现
通过编写爬虫程序,实现对空气质量指数网站上指定地区和时间段内的AQI进行获取,并实现数据可视化
实验步骤:
安装pyspider
在anaconda prompt中使用命令行安装:
若提示升级,则根据提示进行

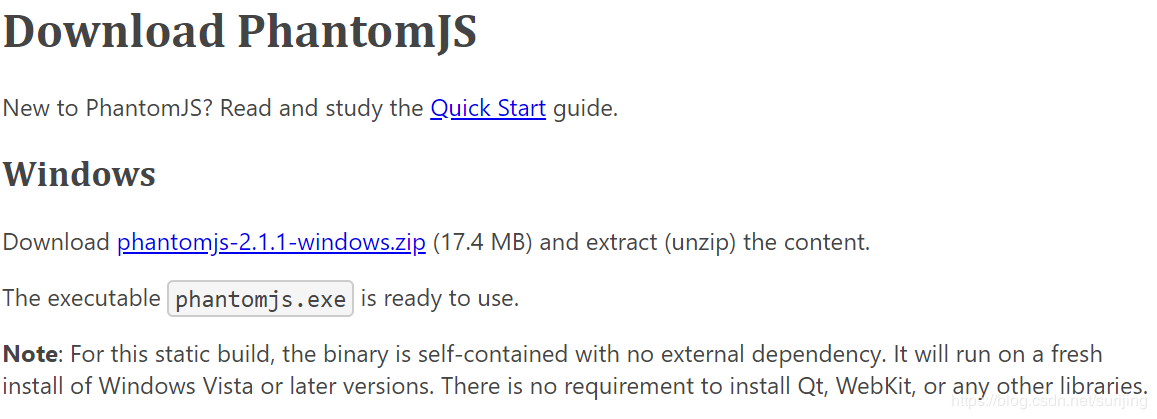
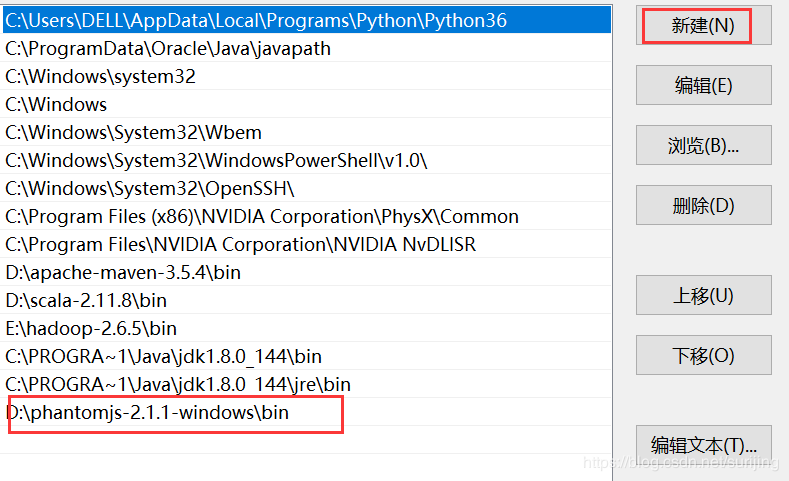
下载PhantomJS,并配置环境变量
可在如下网址中进行下载
https://phantomjs.org/download.html
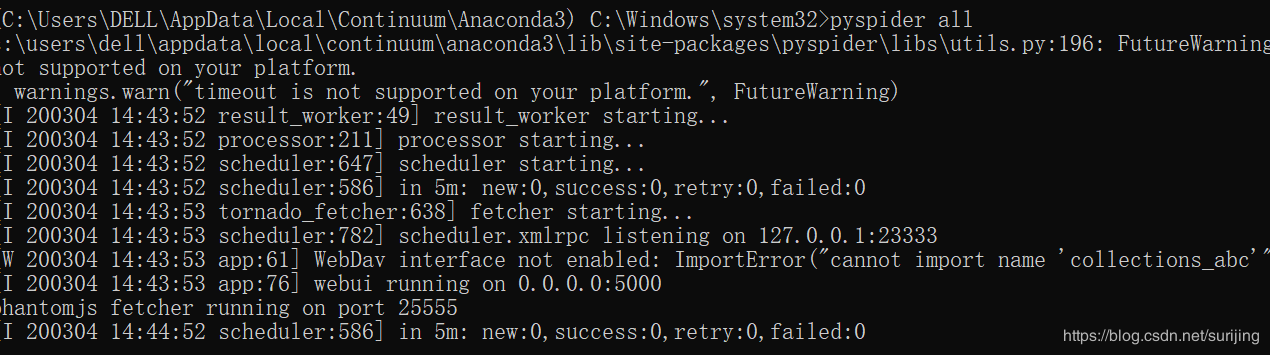
5.用命令行启动pyspider
如果出现下图命令,则启动成功
如果,python的版本3.7以上,建议降级,因为会有语言冲突
在命令行输入如下命令:
pip uninstall WsgiDAV==2.4.1
启动成功后可以通过默认地址:http://localhost:5000/进入spider web界面
并点击create new project 可以新建爬虫job
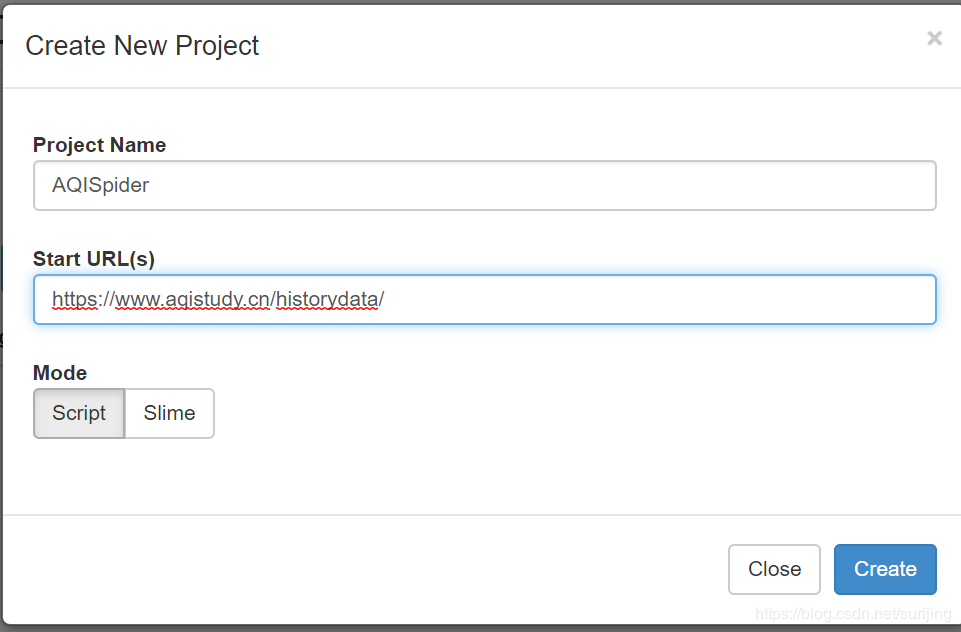
图中的地址便是我要爬取的地址,填写完信息之后点击create
进入怕成项目编写界面:
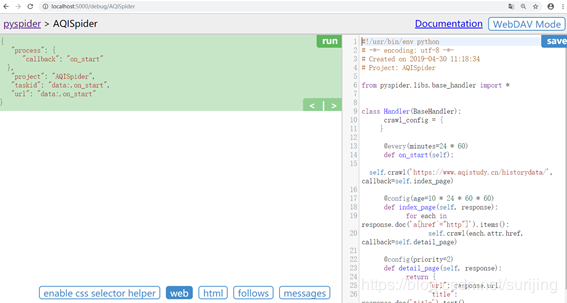
左边是代码调试界面,右边是代码运行结果,点击run 即可运行,每次修改代码之后需要保存(save)
数据采集
选取要爬取的url
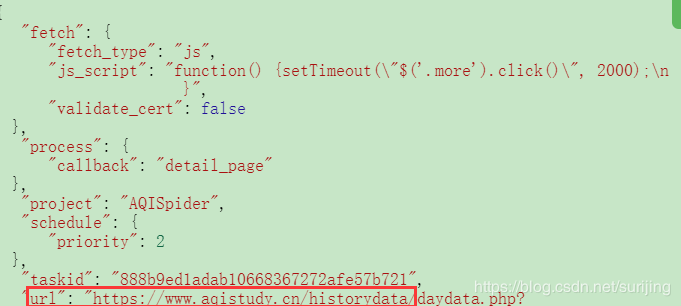
点击右侧的三角按钮
由于url是我们需要的,所以需要修改url获取表达式
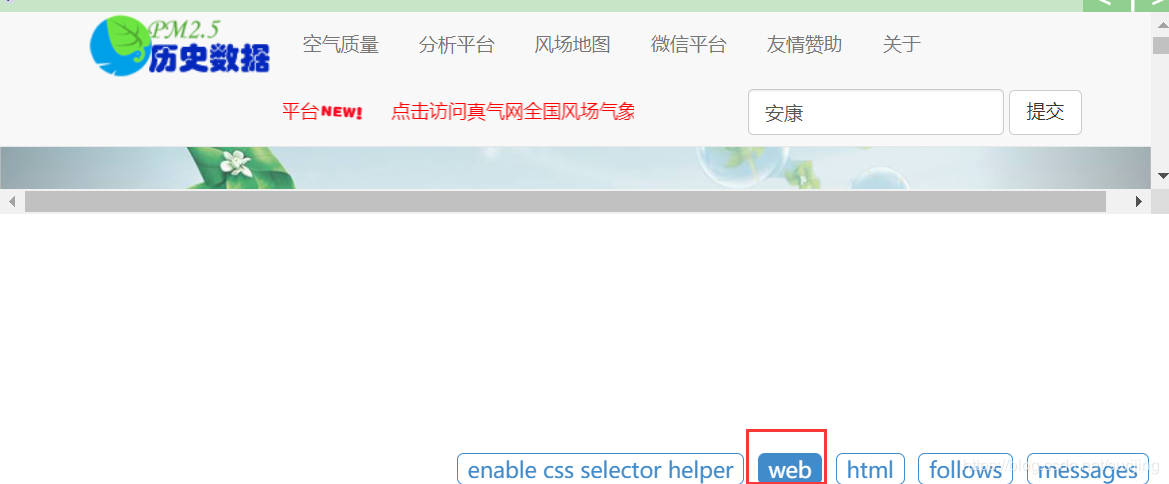
点击enable css selector helper,然后点击想要获取的数据,即可生成响应的数据提取表达式:

点击箭头,可以将生成的表达式插入到光标所在的地方,及’div>li>a‘


重新运行之后:
在index_page方法中的self.crawl中加入下面代码:
fetch_type='js',js_script="""function() {setTimeout("$('.more').click()", 2000);
}"""# 等待浏览器加载数据
保存后,再次
在pyspider中生成的代码里Handler类中新建方法:
@config(age=10 * 24 * 60 * 60)
def index1_page(self, response):
for each in response.doc('.unstyled1 a').items():
self.crawl(each.attr.href,validate_cert=False,fetch_type='js',js_script="""function() {setTimeout("$('.more').click()", 2000);
}""",callback=self.detail_page)# 代码中的JS为等待浏览器加载数据
将方法index_page方法中的callbacke值改为index1_page。

此时所产生的65个链接是城市月份的数据。
选择最后一个(2019年4月的数据):
@config(priority=2)
def detail_page(self, response):
import pandas as pd
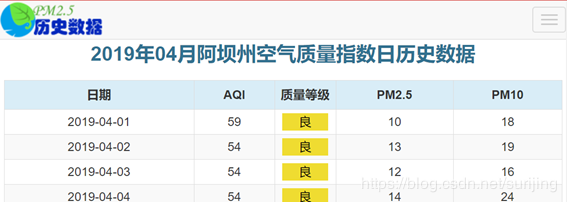
title_data= response.doc("* tr > th").text()# 获取标签数据
data = response.doc("* > * tr > td").text()# 获取表格内的具体数据
title_list = title_data.split(" ")# 将获取的数据进行分割
data_list = data.split(" ")
data_AQI={}# 新建字典用来存放处理后的数据
for i in range(len(title_list)):# 按照标签进行数据处理
data_AQI[title_list[i]]= data_list[i::9]# 将数据处理为字典形式
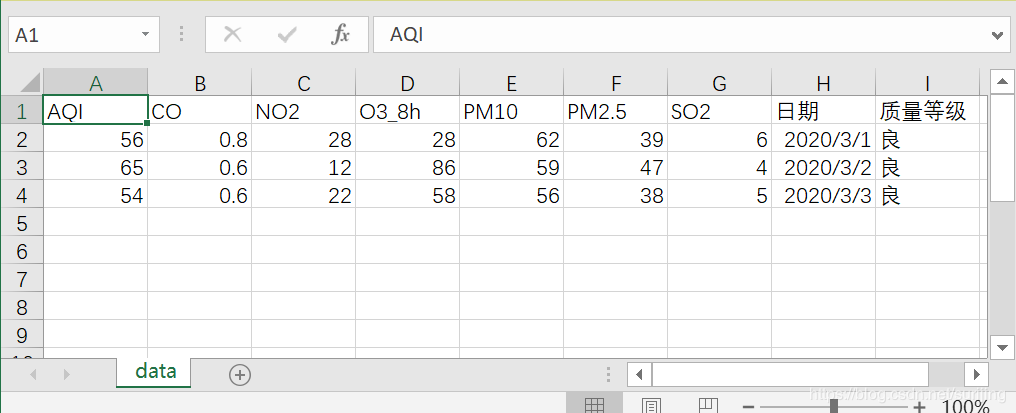
data = pd.DataFrame(data_AQI)# 转换成DataFrame格式
data.to_csv("D:\\data.csv",index=False,encoding="GBK")# 路径可以更换为想要存储数据的路径,此处存储至windows本地桌面,windows中的编码格式为GBK。
return
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import pandas as pd
import matplotlib.dates as mdate
import matplotlib.pyplot as plt
from pylab import mpl
from datetime import datetime
plt.style.use("seaborn-whitegrid")
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 设置matplotlib字体,解决中文显示问题
def visualization_mat(filename):
data = pd.read_csv(filename, encoding="GBK")
# 创建画布,返回figure,axes两个元组 赋予fig,axes,并创建了两行一列的两个子图 一般只用到axes
fig, axes = plt.subplots(nrows=2, ncols=1, dpi=80,figsize=(8,6))
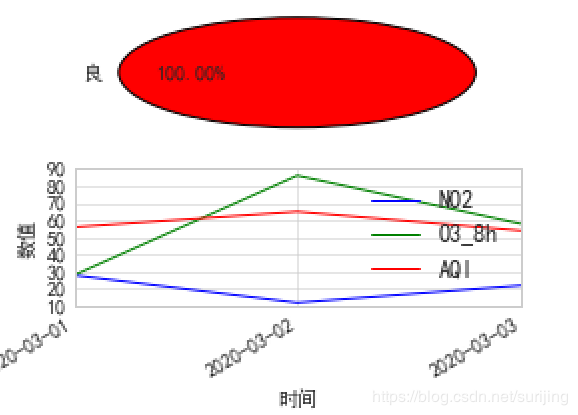
# 质量等级使用饼图展示
level = list(data["质量等级"]) # 简单的数据处理,选取饼图的标签
level_name = list(set(level))
#饼状图需要导入的是:plt.pie(x, labels= )
axes[0].pie([level.count(i) for i in level_name],labels=level_name,
autopct="%1.2f%%",colors=["r", "g", "b","y"]) # 设置饼图的相关属性
ts =[datetime.strptime(i, '%Y-%m-%d') for i in data["日期"]]
# PM数据使用折线图展示
axes[1].plot(ts,data["NO2"])
axes[1].plot(ts,data["O3_8h"])
axes[1].plot(ts,data["AQI"])
axes[1].xaxis.set_major_formatter(mdate.DateFormatter('%Y-%m-%d'))#设置时间标签显示格式
axes[1].set_xticks([datetime.strptime(i, '%Y-%m-%d').date() for i in data["日期"]])
axes[1].set_xlabel("时间") # 为坐标轴设置标签
axes[1].set_ylabel("数值")
axes[1].legend()
plt.gcf().autofmt_xdate()# 日期自动旋转
# plt.savefig(filename+’.jpg’)# 保存图片
plt.show() #展示图像
visualization_mat ("D:\\ data.csv")
作者:TKE_aoliao
相关文章
Welcome
2021-07-30
Psyche
2023-07-20
Winola
2023-07-20
Gella
2023-07-20
Grizelda
2023-07-20
Janna
2023-07-20
Ophelia
2023-07-21
Crystal
2023-07-21
Laila
2023-07-21
Aine
2023-07-21
Bliss
2023-07-21
Lillian
2023-07-21
Tertia
2023-07-21
Olive
2023-07-21
Glory
2023-07-21
Angie
2023-07-21
Nora
2023-07-24