【迁移网络学习实战】- Kaggle猫狗分类大赛 - 单模型测试 - 前7.8%
【迁移网络学习】- Kaggle猫狗分类大赛 - 前7.8%
作者:一只稚嫩的小金毛
数据集下载:
链接:https://pan.baidu.com/s/1AIj0FhdCQPeAWg4Sw7DEOQ
提取码:aejj
想要将深度学习应用于小型图像数据集,一种常用且非常高效的方法是使用预训练网络。预训练网络是一个保存好的网络,之前已在大型数据集**(比如在ImageNet数据集140万张标记图像)**上训练好。如果这个原始数据集足够大且足够通用,那么预训练网络学到的特征的空间层次结构可以有效地作为视觉世界的通用模型。比如VGG、ResNet、Inception、Inception-ResNet、Xception这些通用网络都已经训练好,我们只需要进行迁移就行。
使用预训练网络有两种方法:特征提取和微调模型。由于内容较多,主要介绍进行特征提取方法的学习。对于卷积神经网络,特征提取就是取出之前训练好的网络的卷积基,在上面运行新数据,然后在输出上面重新训练一个新的分类器或者全连接层。
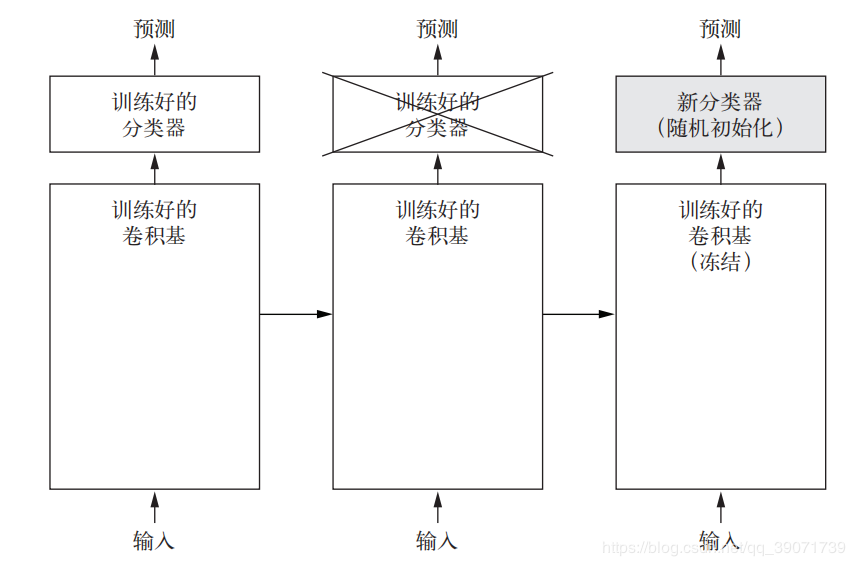
数据:使用Kaggle猫狗大战这个比赛的数据集进行实战,这个比赛也是大名鼎鼎,很多时候都看到。去官网下载了这个数据集,这个数据集包含25000张猫狗图像(每个类别都有12500张),大小为543MB(压缩后)。
import cv2
import numpy as np
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from keras.layers import *
from keras.models import *
import matplotlib.pyplot as plt
from keras.applications import VGG16
# 图片数量、尺寸
n = 25000
width = 224
# 设置张量
X = np.zeros((n, width, width, 3), dtype=np.uint8)
y = np.zeros((n,), dtype=np.uint8)
# 加载图片并设置标签
for i in tqdm(range(12500)):
X[i] = cv2.resize(cv2.imread('D:/DeepLearning/cat_dog/kaggle/train/cat.%d.jpg' % i), (width, width))
X[i+12500] = cv2.resize(cv2.imread('D:/DeepLearning/cat_dog/kaggle/train/dog.%d.jpg' % i), (width, width))
y[12500:] = 1
# 划分验证集
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2)
# VGG-16论文中预处理
def preprocess_input(x):
return x - [103.939, 116.779, 123.68]
# 加载VGG-16的预训练权重
cnn_model = VGG16(include_top=False, input_shape=(width, width, 3), weights='imagenet')
# 冻结卷积层
for layer in cnn_model.layers:
layer.trainable = False
# 构建网络
inputs = Input((width, width, 3))
x = inputs
x = Lambda(preprocess_input, name='preprocessing')(x)
x = cnn_model(x)
x = GlobalAveragePooling2D()(x)
x = Dense(512, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs, x)
# 网络相关设置
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
history = model.fit(X_train, y_train, batch_size=8, epochs=5, validation_data=(X_valid, y_valid),verbose=2)
# 保存模型
model.save('model.h5')
# 获取训练相关指标
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
# 画出Acc、Loss曲线
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
2.测试部分
import cv2
import numpy as np
from tqdm import tqdm
from keras.models import *
import pandas as pd
# 测试集图片
m = 12500
width = 224
# 加载模型
model = load_model('model.h5')
X_test = np.zeros((m, width, width, 3), dtype=np.uint8)
for i in tqdm(range(m)):
X_test[i] = cv2.resize(cv2.imread('D:/DeepLearning/cat_dog/kaggle/test/%d.jpg' % (i+1)), (width, width))
# 模型预测
y_pred = model.predict(X_test, batch_size=8, verbose=1)
# 写进CSV文件
df = pd.read_csv('sample_submission.csv')
# 约束分数范围,提高排名
df['label'] = y_pred.clip(min=0.005, max=0.995)
df.to_csv('pred.csv', index=None)
三、结果
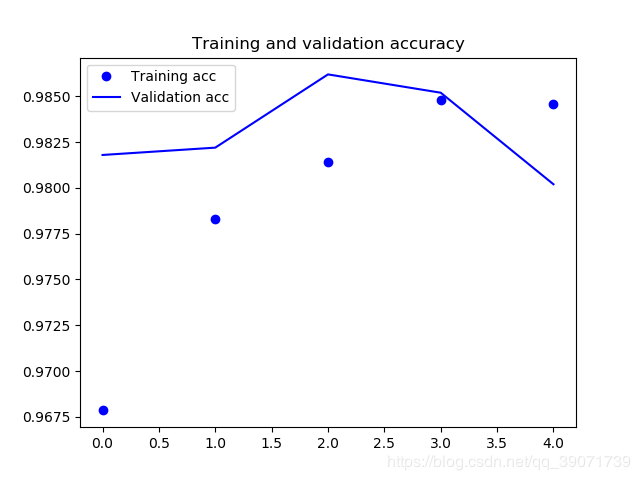
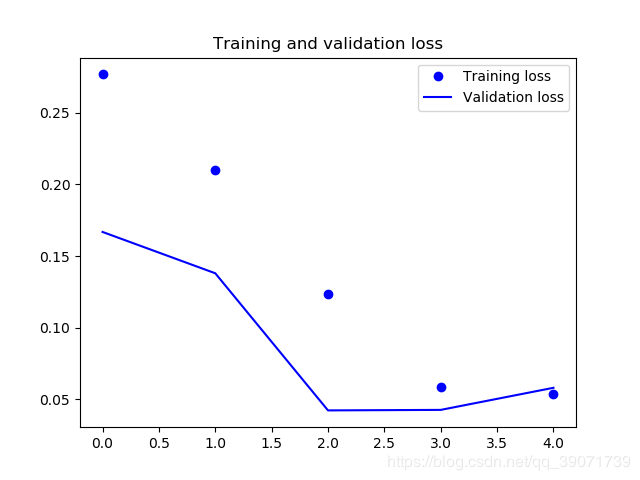
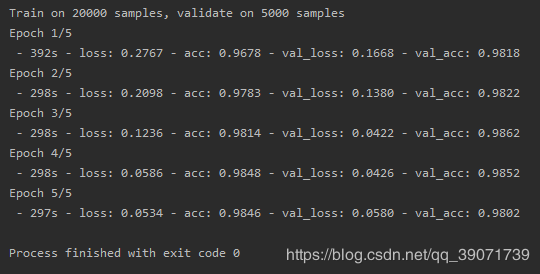
从结果来看,是获得了一个巨大的提升。训练集的正确率达到了98.46%,验证集的正确率达到98.02%,而且时间短,效果好,迁移学习获得了预期的效果。
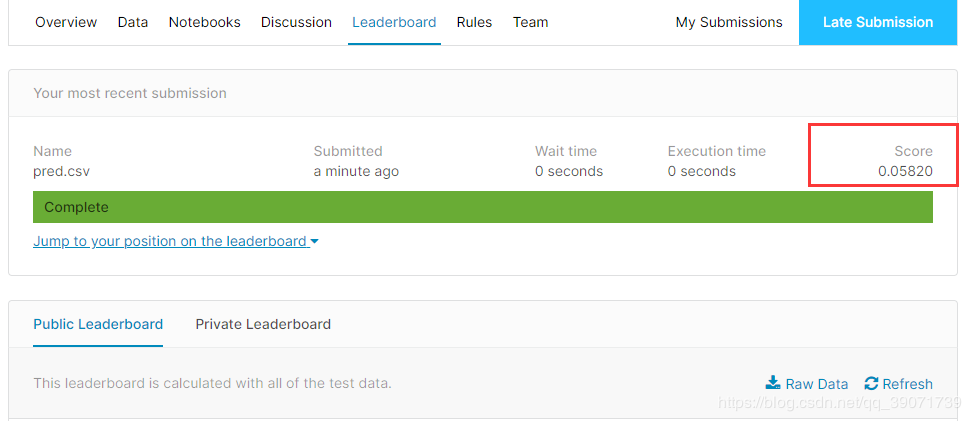
上传至官方进行评估,提交了结果,得分在0.0582,由于该排行榜停止了更新,大概看了下,理论上目前成绩应该在109名左右,前8%,可以说第一次迁移学习实战是成功的。
作者:一只稚嫩的小金毛
相关文章
Lani
2021-05-07
Rebecca
2021-05-19
Iris
2021-08-03
Winema
2020-09-03
Ebony
2021-02-05
Ophelia
2023-07-20
Dagny
2023-07-20
Roselani
2023-07-20
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20
Carly
2023-07-20
Irma
2023-07-20
Posy
2023-07-20
Vanna
2023-07-20
Maha
2023-07-20
Kirima
2023-07-20