【NLP】Seq2Seq模型与实战(Tensoflow2.x、Keras)
根据输出和输入序列不同数量rnn可以有多种不同的结构,不同结构自然就有不同的引用场合。如下图,
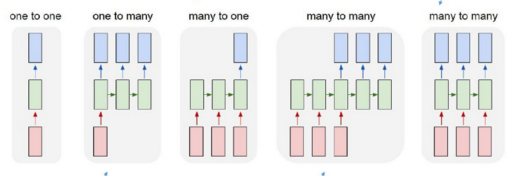
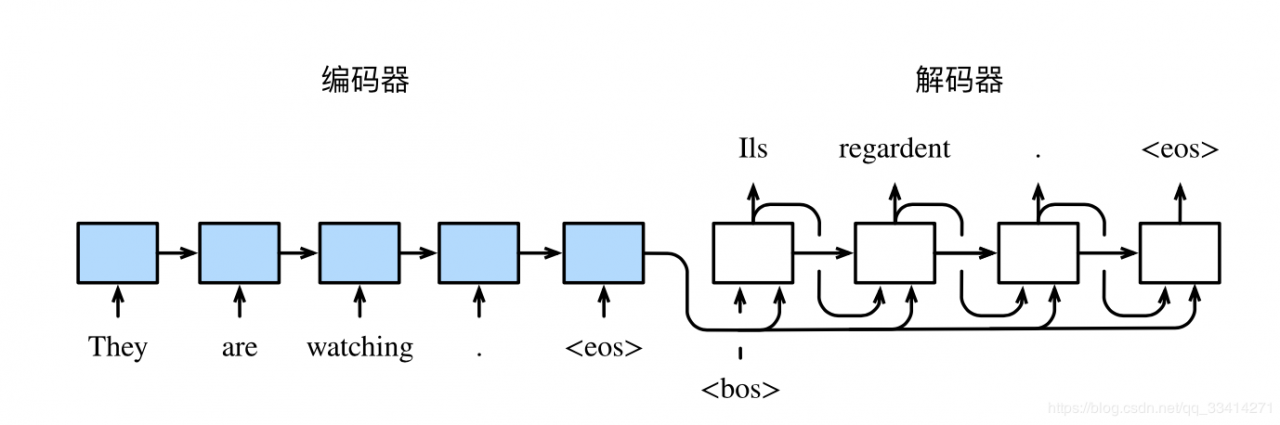
在 many to many 的两种模型中,上图可以看到第四和第五种是有差异的,经典的rnn结构的输入和输出序列必须要是等长,它的应用场景也比较有限。而第四种它可以是输入和输出序列不等长,这种模型便是seq2seq模型,即Sequence to Sequence。它实现了从一个序列到另外一个序列的转换,比如google曾用seq2seq模型加attention模型来实现了翻译功能,类似的还可以实现聊天机器人对话模型。经典的rnn模型固定了输入序列和输出序列的大小,而seq2seq模型则突破了该限制。
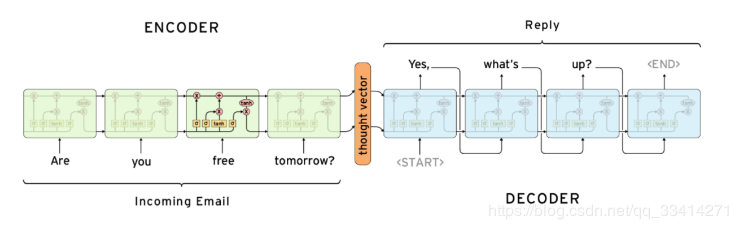
其实对于seq2seq的decoder,它在训练阶段和预测阶段对rnn的输出的处理可能是不一样的,比如在训练阶段可能对rnn的输出不处理,直接用target的序列作为下时刻的输入,预测阶段会将rnn的输出当成是下一时刻的输入。
编码器的作用是把一个不定⻓的输入序列变换成一个定⻓的背景变量c,并在该背景变量中编码输入序列信息。常用的编码器是循环神经网络。
用函数f 表达循环神经网络隐藏层的变换:
编码器通过自定义函数q将各个时间步的隐藏状态变换为背景变量:

获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
decoder则负责根据语义向量生成指定的序列,这个过程也称为解码。
在输出序列的时间步t′ ,解码器将上一时间步的输出y(t′−1) 以及背景变量c作为输入,并将它们与上一时间步的隐藏状态s(t′−1) 变换为当前时 间步的隐藏状态s(t′) 。因此,我们可以用函数g表达解码器隐藏层的变换:
![]()
基于当前时间步的解码器隐藏状态 s(t′) 、上一时间步的输出y(t′ −1) 以及背景 变量c来计算当前时间步输出y(t′) 的概率分布。
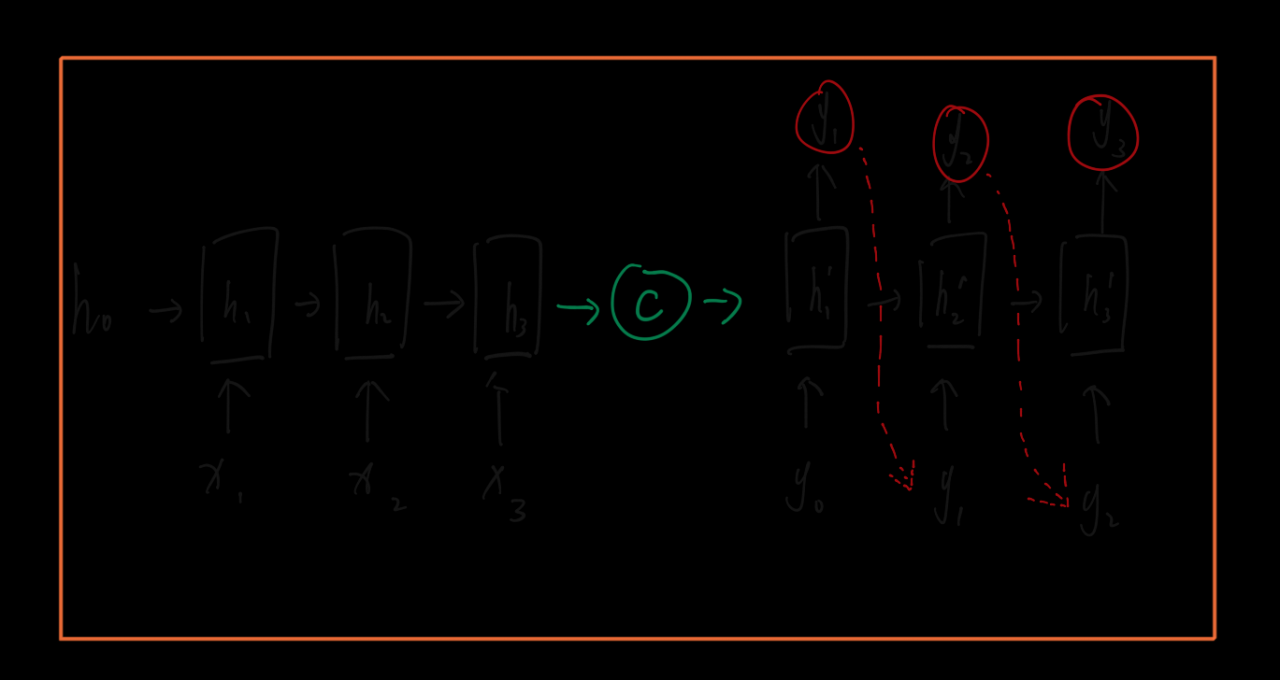
最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的rnn中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。
1.3 模型训练根据最大似然估计,我们可以最大化输出序列基于输入序列的条件概率:
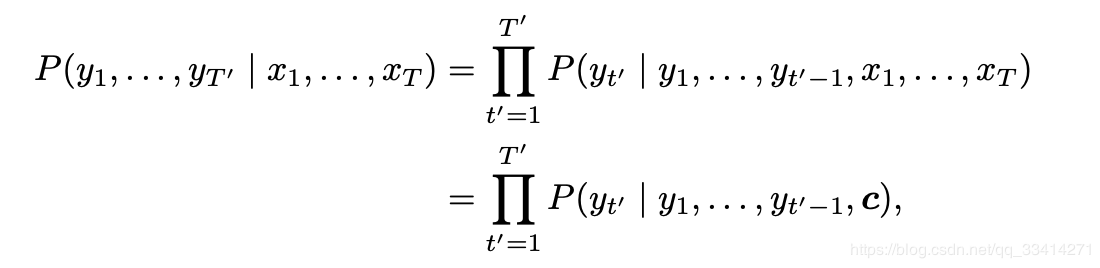
并得到该输出序列的损失:
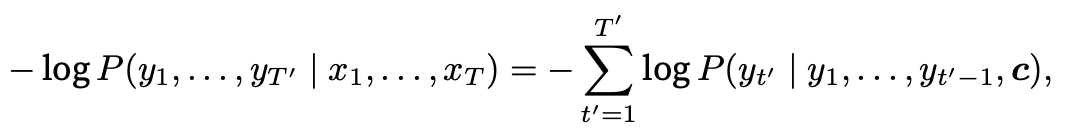
在模型训练中,所有输出序列损失的均值通常作为需要最小化的损失函数。
一般我们需要将解码器在上一个时间步的输出作为当前时间步的输入:
在训练中也可以将标签序列(训练集的真实输出序列)在上一个时间步的标签作为解码器在当前时间步的输入。这叫作强制教学(teacher forcing)。
二、 实战实战项目参考:
1、时序数据预测,来源于google在kaggle上公开的一个项目Web Traffic Time Series Forecasting。数据量600M+。
https://github.com/JEddy92/TimeSeries_Seq2Seq
2、时序数据预测:https://github.com/Olliang/Time-Series-Forcasting
3、图像生成:https://github.com/timsainb/tensorflow2-generative-models
4、文本摘要:https://www.kaggle.com/sandeepbhogaraju/text-summarization-with-seq2seq-model/comments#728381
5、机器翻译:https://www.kaggle.com/bachrr/seq2seq-for-english-arabic-translation-in-keras/comments#741129
6、字符级别的翻译:https://github.com/ktoulgaridis/char-seq2seq-translate
7、聊天机器人:https://github.com/tensorlayer/seq2seq-chatbot
实践地6个项目如下:
# Imports Cell
from __future__ import print_function
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense
import numpy as np
2.1超参数设置
设置batch大小、训练重复次数、编码向量维度、数据路径等
# Basic Parameters
batch_size = 64 # Batch size for training.
epochs = 10 # Number of epochs to train for.
latent_dim = 256 # Latent dimensionality of the encoding space.
num_samples = 10000 # Number of samples to train on.
# Path to the data txt file on disk.
data_path = './ell.txt'
2.2数据的预处理
从txt文件中读取数据;
input_texts存储英文输入;
target_texts存储翻译后成希腊语的单词;
input_characters表示英文中无重复的字符;
target_characters表示希腊语中对应的无重复字符。
解码的时候需要起始字符和结束字符,这里分别用制表符’\t’和回车符’\n’来表示
# Vectorize the data.
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
for line in lines[: min(num_samples, len(lines) - 1)]:
input_text, target_text, _ = line.split('\t')
# We use "tab" as the "start sequence" character
# for the targets, and "\n" as "end sequence" character.
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
查看数据的特征,编码的对应维度是69,解码对应的维度是110
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
input_token_index = dict(
[(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict(
[(char, i) for i, char in enumerate(target_characters)])
print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
Number of samples: 10000
Number of unique input tokens: 69
Number of unique output tokens: 110
Max sequence length for inputs: 25
Max sequence length for outputs: 49
print('input_characters:',input_characters)
print('target_characters:',target_characters)
input_characters: [' ', '!', '%', "'", ',', '-', '.', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'R', 'S', 'T', 'U', 'V', 'W', 'Y', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '€']
target_characters: ['\t', '\n', ' ', '!', '%', "'", ',', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '?', 'C', 'D', 'E', 'F', 'I', 'K', 'M', 'O', 'T', 'U', 'a', 'd', 'e', 'h', 'i', 'm', 'n', 'o', 'r', 't', '·', ';', '΄', 'Ά', 'Έ', 'Ή', 'Ί', 'Ό', 'Ώ', 'ΐ', 'Α', 'Β', 'Γ', 'Δ', 'Ε', 'Ζ', 'Η', 'Θ', 'Ι', 'Κ', 'Λ', 'Μ', 'Ν', 'Ξ', 'Ο', 'Π', 'Ρ', 'Σ', 'Τ', 'Υ', 'Φ', 'Χ', 'Ψ', 'ά', 'έ', 'ή', 'ί', 'α', 'β', 'γ', 'δ', 'ε', 'ζ', 'η', 'θ', 'ι', 'κ', 'λ', 'μ', 'ν', 'ξ', 'ο', 'π', 'ρ', 'ς', 'σ', 'τ', 'υ', 'φ', 'χ', 'ψ', 'ω', 'ϊ', 'ϋ', 'ό', 'ύ', 'ώ', 'ὠ']
2.3模型输入
设置编码、解码的数据维度
编码输入维度:(输入长度,最大输入序列长度,编码字符集合个数)
解码输入维度:(输入长度,最大输出序列长度,解码字符集合个数)
# Initialize Model Arrays
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
装入对应的数据
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.
encoder_input_data[i, t + 1:, input_token_index[' ']] = 1.
for t, char in enumerate(target_text):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
decoder_input_data[i, t + 1:, target_token_index[' ']] = 1.
decoder_target_data[i, t:, target_token_index[' ']] = 1.
print('encoder_input_data:',encoder_input_data.shape)
print('decoder_input_data:',decoder_input_data.shape)
print('decoder_target_data:',decoder_target_data.shape)
encoder_input_data: (10000, 25, 69)
decoder_input_data: (10000, 49, 110)
decoder_target_data: (10000, 49, 110)
2.4模型构建
# Define an input sequence and process it.
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# We discard `encoder_outputs` and only keep the states.
encoder_states = [state_h, state_c]
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None, num_decoder_tokens))
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# Run training
model.compile(optimizer='rmsprop', loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
Train on 8000 samples, validate on 2000 samples
Epoch 1/10
8000/8000 [==============================] - 69s 9ms/sample - loss: 1.5498 - accuracy: 0.6326 - val_loss: 1.7987 - val_accuracy: 0.5402
Epoch 2/10
8000/8000 [==============================] - 67s 8ms/sample - loss: 1.2061 - accuracy: 0.6883 - val_loss: 1.4995 - val_accuracy: 0.5926
Epoch 3/10
8000/8000 [==============================] - 62s 8ms/sample - loss: 1.0012 - accuracy: 0.7326 - val_loss: 1.3102 - val_accuracy: 0.6387
Epoch 4/10
8000/8000 [==============================] - 63s 8ms/sample - loss: 0.8812 - accuracy: 0.7538 - val_loss: 1.2051 - val_accuracy: 0.6592
Epoch 5/10
8000/8000 [==============================] - 63s 8ms/sample - loss: 0.8107 - accuracy: 0.7700 - val_loss: 1.1377 - val_accuracy: 0.6777
Epoch 6/10
8000/8000 [==============================] - 63s 8ms/sample - loss: 0.7565 - accuracy: 0.7841 - val_loss: 1.0627 - val_accuracy: 0.6970
Epoch 7/10
8000/8000 [==============================] - 59s 7ms/sample - loss: 0.7083 - accuracy: 0.7962 - val_loss: 1.0445 - val_accuracy: 0.6986
Epoch 8/10
8000/8000 [==============================] - 59s 7ms/sample - loss: 0.6639 - accuracy: 0.8085 - val_loss: 0.9673 - val_accuracy: 0.7245
Epoch 9/10
8000/8000 [==============================] - 59s 7ms/sample - loss: 0.6242 - accuracy: 0.8195 - val_loss: 0.9362 - val_accuracy: 0.7339
Epoch 10/10
8000/8000 [==============================] - 55s 7ms/sample - loss: 0.5891 - accuracy: 0.8300 - val_loss: 0.9095 - val_accuracy: 0.7399
# Save model
model.save('s2s.h5')
2.5模型使用
为什么下面这段代码又在构建模型,原因是seq2seq在训练和生成的时候并不完全相同;
训练的时候,解码器是有预先输入的,我们会把正确的下句作为输入指导解码器进行学习,具体来说,不管上一个时刻解码器的输出是什么,我们都用预先给定的输入作为本时刻的输入;
这种训练方式称为Teacher forcing
但是在生成的时候,解码器是没有预先输入的,我们会把上一个时刻解码器的输出作为本时刻的输入,如此迭代的生成句子
训练的时候我们的model是一整个seq2seq的模型,这个黑盒在给定encoder_input和decoder_input的情况下可以产生对应的输出
但是生成时我们没有decoder_input,我们就把黑盒拆成两个黑盒,一个是编码器,一个是解码器,方便我们的操作。
# Next: inference mode (sampling).
# Here's the drill:
# 1) encode input and retrieve initial decoder state
# 2) run one step of decoder with this initial state
# and a "start of sequence" token as target.
# Output will be the next target token
# 3) Repeat with the current target token and current states
# Define sampling models
# 第一个黑盒,编码器,给定encoder_inputs,得到encoder的状态
encoder_model = Model(encoder_inputs, encoder_states)
# 第二个黑盒,解码器
# 解码器接受三个输入,两个是初始状态,一个是之前已经生成的文本
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
# 解码器产生三个输出,两个当前状态,一个是每个时刻的输出,其中最后一个时刻的输出可以用来计算下一个字
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
# Reverse-lookup token index to decode sequences back to
# something readable.
reverse_input_char_index = dict(
(i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict(
(i, char) for char, i in target_token_index.items())
下述代码就实现了迭代的解码
假设我们已经生成了前n个字,我们把前n个字作为输入,得到第n+1个字,再把这n+1个字作为输入,得到第n+2个字,以此类推
def decode_sequence(input_seq):
# Encode the input as state vectors.
# 先把上句输入编码器得到编码的中间向量,这个中间向量将是解码器的初始状态向量
states_value = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1.
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Populate the first character of target sequence with the start character.
# 初始的解码器输入是开始符'\t'
target_seq[0, 0, target_token_index['\t']] = 1.
# Sampling loop for a batch of sequences
# (to simplify, here we assume a batch of size 1).
stop_condition = False
decoded_sentence = ''
# 迭代解码
while not stop_condition:
# 把当前的解码器输入和当前的解码器状态向量送进解码器
# 得到对下一个时刻的预测和新的解码器状态向量
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# Sample a token
# 采样出概率最大的那个字作为下一个时刻的输入
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# Exit condition: either hit max length
# or find stop character.
# 如果采样到了结束符或者生成的句子长度超过了decoder_len,就停止生成
if (sampled_char == '\n' or
len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# Update the target sequence (of length 1).
# 否则我们更新下一个时刻的解码器输入和解码器状态向量
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# Update states
states_value = [h, c]
return decoded_sentence
for seq_index in range(100):
# Take one sequence (part of the training set)
# for trying out decoding.
input_seq = encoder_input_data[seq_index: seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print('-')
print('Input sentence:', input_texts[seq_index])
print('Decoded sentence:', decoded_sentence)
-
Input sentence: Go.
Decoded sentence: Είναι πολύ παλές.
-
Input sentence: Run!
Decoded sentence: Σε θα το πορέσω.
-
Input sentence: Run!
Decoded sentence: Σε θα το πορέσω.
-
Input sentence: Who?
Decoded sentence: Πότε τον παραστου;
-
Input sentence: Wow!
Decoded sentence: Πόστε τον Τομ;
······
参考资料:
https://blog.csdn.net/wangyangzhizhou/article/details/77883152
作者:土豆洋芋山药蛋