Python爬虫之B站视频下载器
看见B站上也有很多有趣的视频,想将其下载下来却发现没有下载接口,就想用Python写爬虫来下载B站视频
仅供学习,禁止用于非法用途
需要被爬取的网站bilibili.com
效果图
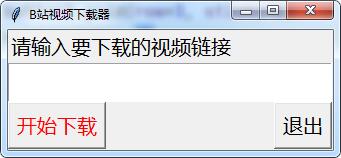
爬虫之前先查看一下robots协议
https://www.bilibili.com/robots.txt
User-agent: *
Disallow: /include/
Disallow: /mylist/
Disallow: /member/
Disallow: /images/
Disallow: /ass/
Disallow: /getapi
Disallow: /search
Disallow: /account
Disallow: /badlist.html
Disallow: /m/
很好,一个字都看不懂
简单找了几个视频,发现B站视频主要是flv和mp4,flv知道是什么,那么m4s是个什么东西

M4S文件扩展是Myst IV: Revelation Save Game File 文件,最初由Open Source 为 MP4Box开发。 我们的数据显示M4S 文件在China 中经常被PC用户使用,在Windows 10 平台上也很流行。 这些用户中有很大一部分使用 Google Chrome浏览网页。
用人话给你说一遍,就是有两个m4s文件,一个是视频,一个是音频,把他们合并成mp4,就可以愉快观看了
这里flv文件以https://www.bilibili.com/video/BV1xs411Q799?from=search&seid=17914779325804531164为例
m4s文件以https://www.bilibili.com/video/BV1Ek4y1R7pD?spm_id_from=333.851.b_7265706f7274466972737431.10为例
首先先把GUI界面写出来(丑的惨不忍睹)
from tkinter import *
root = Tk()
root.title('B站视频下载器')
root.geometry("325x120+500+250")
lable = Label(root, text="请输入要下载的视频链接", font=('微软雅黑', 15))
lable.grid(sticky=W)
entry = Entry(root, font=('微软雅黑', 20))
entry.grid(sticky=W)
button = Button(root, text="开始下载", font=('微软雅黑', 15), fg='red', command=start)
button.grid(row=3, sticky=W)
button2 = Button(root, text='退出', font=('微软雅黑', 15), command=lambda: exit())
button2.grid(row=3, sticky=E)
root.mainloop()
flv
开始写代码,首先看看这个视频链接在哪里
https://upos-sz-mirrorks3.bilivideo.com/upgcxcode/73/45/6534573/6534573-1-64.flv?e=ig8euxZM2rNcNb4VhwdVtW4VhwdVNEVEuCIv29hEn0lqXg8Y2ENvNCImNEVEUJ1miI7MT96fqj3E9r1qNCNEtodEuxTEtodE9EKE9IMvXBvE2ENvNCImNEVEK9GVqJIwqa80WXIekXRE9IMvXBvEuENvNCImNEVEua6m2jIxux0CkF6s2JZv5x0DQJZY2F8SkXKE9IB5QK==&uipk=5&nbs=1&deadline=1587129834&gen=playurl&os=ks3bv&oi=2936338712&trid=b695a2f633e8469b884609cd987c9541u&platform=pc&upsig=1fc07f8f3fb9749a73aacdf5749dbc42&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=520093739&logo=80000000
抓包发现这是它的视频链接,这么多参数,看着都头大,那么这些参数是哪来的?
我也不知道
我找了很久,最后发现这个网页源代码里就有他的视频播放链接
所以就可以写代码了
def flv_download(name, url, header):
r = requests.get(url, headers=info_headers).text
url = re.findall(re.compile(r'"url":"(.*?)"'), r)[0]
response = requests.get(url, headers=header)
with open('%s.mp4' % name, 'wb') as f:
f.write(response.content)
messagebox.showinfo('提示', '%s 下载完成' % name)
这样就可以下载flv文件了
m4s那么怎么下载m4s文件呢
源代码里发线了这样的结构
“video”:[{“id”:80,“baseUrl”:“http://cn-hbyc2-dx-v-15.bilivideo.com/upgcxcode/36/78/178317836/178317836-1-30080.m4s?expires=1587129600&platform=pc&ssig=MeGNMYQHgujhgBLEcybFiw&oi=2936338712&trid=58ade969830643c48fdc274f0b4ebbc4u&nfc=1&nfb=maPYqpoel5MI3qOUX6YpRA==&mid=520093739&logo=80000000”
和
“audio”:[{“id”:30280,“baseUrl”:“http://cn-hbyc2-dx-v-15.bilivideo.com/upgcxcode/36/78/178317836/178317836-1-30280.m4s?expires=1587129600&platform=pc&ssig=FUobjdRMPfVopbLvS2bJ8g&oi=2936338712&trid=58ade969830643c48fdc274f0b4ebbc4u&nfc=1&nfb=maPYqpoel5MI3qOUX6YpRA==&mid=520093739&logo=80000000”
好像这就是我们要的文件诶
这样就可以写代码了
def m4s_download(name, url, header):
r = requests.get(url, headers=info_headers).text
video = re.findall(re.compile(r'"baseUrl":"(.*?)","base_url":"(.*?)"'), r)[0][0]
audio = re.findall(re.compile(r'"audio":\[\{"id":.*?,"baseUrl":"(.*?)"'), r)[0]
with open('video.m4s', 'wb') as f1:
f1.write(requests.get(video, headers=header).content)
with open('audio.m4s', 'wb') as f2:
f2.write(requests.get(audio, headers=header).content)
path = os.getcwd()
os.system('cd %s' % path)
os.system('ffmpeg -i video.m4s -i audio.m4s -codec copy ' + name + '.mp4')
os.remove('video.m4s')
os.remove('audio.m4s')
messagebox.showinfo('提示', '%s 下载完成' % name)
ffmpeg
我们通过ffmpeg来合并m4s文件
指令如下
ffmpeg -i video.m4s -i audio.m4s -codec copy 保存名称.mp4
在这之前要先将FFmpeg配置环境变量
环境变量配置方法

最后,完整代码如下
import os
import requests
import re
from tkinter import *
from tkinter import messagebox
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
if not os.path.exists('result'):
os.mkdir('result')
os.chdir('result')
info_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'Referer': 'https://www.bilibili.com/',
'Host': 'www.bilibili.com',
'Cookie': "_uuid=16411677-46B3-DB26-C2B0-6EAA61A37CE021218infoc; buvid3=9CB12915-53A3-4356-BA96-AC5A29E057EB53918infoc; CURRENT_FNVAL=16; LIVE_BUVID=AUTO5415844438322276; rpdid=|(kmJYJJmYJ)0J'ul)RR)m|J); sid=5urb14kc; DedeUserID=520093739; DedeUserID__ckMd5=b7bf4bcd47177a49; SESSDATA=21f8e59d%2C1600514358%2C80365*31; bili_jct=e2a165fd6fe383d051eb3ee160bd1462; INTVER=1; PVID=1",
}
def flv_download(name, url, header):
r = requests.get(url, headers=info_headers).text
url = re.findall(re.compile(r'"url":"(.*?)"'), r)[0]
response = requests.get(url, headers=header)
with open('%s.mp4' % name, 'wb') as f:
f.write(response.content)
messagebox.showinfo('提示', '%s 下载完成' % name)
def m4s_download(name, url, header):
r = requests.get(url, headers=info_headers).text
video = re.findall(re.compile(r'"baseUrl":"(.*?)","base_url":"(.*?)"'), r)[0][0]
audio = re.findall(re.compile(r'"audio":\[\{"id":.*?,"baseUrl":"(.*?)"'), r)[0]
with open('video.m4s', 'wb') as f1:
f1.write(requests.get(video, headers=header).content)
with open('audio.m4s', 'wb') as f2:
f2.write(requests.get(audio, headers=header).content)
path = os.getcwd()
os.system('cd %s' % path)
os.system('ffmpeg -i video.m4s -i audio.m4s -codec copy ' + name + '.mp4')
os.remove('video.m4s')
os.remove('audio.m4s')
messagebox.showinfo('提示', '%s 下载完成' % name)
def start():
ua = UserAgent()
url = entry.get()
download_headers = {
'User-Agent': ua.random,
'Referer': url,
}
try:
r = requests.get(url, headers=info_headers).text
except requests.exceptions.MissingSchema:
messagebox.showerror('错误', '请输入正确的链接')
else:
messagebox.showinfo("提示", '开始下载\n可能需要一定的时间')
soup = BeautifulSoup(r, 'lxml')
name = str(soup.title.string).split('_')[0]
name = name.replace('/', '').replace(r'\\', '').replace(':', '').replace('*', '').replace('?', '').replace(r'"',
'').replace(
'', '').replace('|', '')
if re.search('m4s', r) != None:
m4s_download(name, url, download_headers)
else:
flv_download(name, url, download_headers)
root = Tk()
root.title('B站视频下载器')
root.geometry("325x120+500+250")
lable = Label(root, text="请输入要下载的视频链接", font=('微软雅黑', 15))
lable.grid(sticky=W)
entry = Entry(root, font=('微软雅黑', 20))
entry.grid(sticky=W)
button = Button(root, text="开始下载", font=('微软雅黑', 15), fg='red', command=start)
button.grid(row=3, sticky=W)
button2 = Button(root, text='退出', font=('微软雅黑', 15), command=lambda: exit())
button2.grid(row=3, sticky=E)
root.mainloop()
源代码可通过网盘get,在使用之前务必先阅读README.html
链接:https://pan.baidu.com/s/1LZZbMqqm7FT4Z7ngTrVwaQ
提取码:pnnp
作者:realmels