GoogLeNet卷积神经网络--TensorFlow2
GoogLeNet卷积神经网络--TensorFlow2结果展示loss和acc曲线计算参数程序
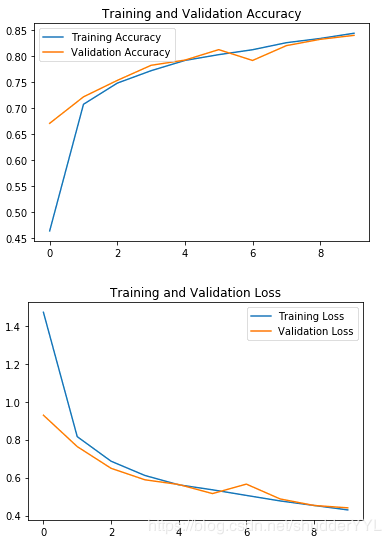
结果展示
作者:Jiollos
epoch = 10
acc = 83.98%

# -*- coding: utf-8 -*-
"""
Created on Tue Apr 14 2020
@author: jiollos
"""
# 导入包
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense, \
GlobalAveragePooling2D
from tensorflow.keras import Model
# 设置显示格式
np.set_printoptions(threshold=np.inf)
# 导入数据集
fashion = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
print("x_train.shape", x_train.shape)
# 给数据增加一个维度,使数据和网络结构匹配
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
# print("x_train.shape", x_train.shape)
# 构建单个卷积class
class ConvBNRelu(Model):
# 默认卷积核边长是3,步长为1,使用全零填充
def __init__(self, ch, kernelsz=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
# 设置sequence
self.model = tf.keras.models.Sequential([
Conv2D(ch, kernelsz, strides=strides, padding=padding), # 卷积核个数/卷积核尺寸/卷积步长/是否全零填充
BatchNormalization(), # 标准化BN层
Activation('relu') # ReLU激活函数
])
def call(self, x):
#在training=False时,BN通过整个训练集计算均值、方差去做批归一化,training=True时,通过当前batch的均值、方差去做批归一化。推理时 training=False效果好
x = self.model(x, training=False)
return x
# 构建inception模块class
class InceptionBlk(Model):
def __init__(self, ch, strides=1):
super(InceptionBlk, self).__init__()
# 定义
self.ch = ch
self.strides = strides
# 设置各卷积的内容,按照inception的结构依次设置
self.c1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_2 = ConvBNRelu(ch, kernelsz=3, strides=1)
self.c3_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c3_2 = ConvBNRelu(ch, kernelsz=5, strides=1)
# 3*3卷积核,步长为1,全零填充
self.p4_1 = MaxPool2D(3, strides=1, padding='same')
self.c4_2 = ConvBNRelu(ch, kernelsz=1, strides=strides)
# 前向传播
def call(self, x):
x1 = self.c1(x)
x2_1 = self.c2_1(x)
x2_2 = self.c2_2(x2_1)
x3_1 = self.c3_1(x)
x3_2 = self.c3_2(x3_1)
x4_1 = self.p4_1(x)
x4_2 = self.c4_2(x4_1)
# concat along axis=channel
# 将4个部分叠加起来,深度为3
x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3)
return x
class Inception10(Model):
# 设置默认ch=16,就是16个卷积核
def __init__(self, num_blocks, num_classes, init_ch=16, **kwargs):
super(Inception10, self).__init__(**kwargs)
self.in_channels = init_ch
self.out_channels = init_ch
self.num_blocks = num_blocks
self.init_ch = init_ch
# 直接为初始化中的值(3*3卷积核,步长为1)
self.c1 = ConvBNRelu(init_ch)
# 调用定义的sequence
self.blocks = tf.keras.models.Sequential()
# 有2个block,循环
for block_id in range(num_blocks):
for layer_id in range(2):
if layer_id == 0:
# 第1层,执行inception block,步长为2
block = InceptionBlk(self.out_channels, strides=2)
else:
# 第2层,执行inception block,步长为1
block = InceptionBlk(self.out_channels, strides=1)
self.blocks.add(block)
# enlarger out_channels per block
# 因为步长不一样,所以深度加深,保证输出特征抽取中信息的承载量一致
self.out_channels *= 2
# 最终经过inception后变为128个通道的数据,送入平均池化
# 平均池化层
self.p1 = GlobalAveragePooling2D()
# num_classes为分类数量
self.f1 = Dense(num_classes, activation='softmax')
def call(self, x):
# 执行4个结构
x = self.c1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
# 输入参数,运行
model = Inception10(num_blocks=2, num_classes=10)
# 设置优化器等模块
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 设置断点
checkpoint_save_path = "./checkpoint/Inception10.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
# 执行训练
history = model.fit(x_train, y_train, batch_size=1024, epochs=10, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
# 显示结果
model.summary()
# 保存权重
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
#plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.show()
#plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
作者:Jiollos