吴恩达,神经网络优化课后作业总结版
1.我们将在原代码的基础上进行添加各类优化设置。(即添加剂)
1. 正则 、droput、动量梯度下降、adam
2. 第一步,导入数据
from lr_utils import load_dataset
import numpy as np
import matplotlib.pyplot as plt
import h5py
train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = load_dataset()
m_train = train_set_y.shape[1] #训练集里图片的数量。
m_test = test_set_y.shape[1] #测试集里图片的数量。
num_px = train_set_x_orig.shape[1] #训练、测试集里面的图片的宽度和高度(均为64x64)。
#将训练集的维度降低并转置。
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0],-1).T
#将测试集的维度降低并转置。
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T
train_x = train_set_x_flatten / 255
test_x = test_set_x_flatten / 255
利用he方法,进行初始化参数,若是不明白he初始化,可以去我上一篇查看。
def initialize_parameters_deep(layer_dims):
'''
参数:
layer_dims:网络每一层的单元数
返回:
parameters:初始化后的参数 字典形式
"W1", "b1", ..., "WL", "bL":
Wl -- weight matrix of shape (layer_dims[l], layer_dims[l-1])
bl -- bias vector of shape (layer_dims[l], 1)
'''
np.random.seed(1)
parameters = {}
L = len(layer_dims) # 神经网络层数+1 包括输入层
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l - 1]) * np.sqrt(2. / layer_dims[l - 1]) # *0.01
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
assert (parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l - 1]))
assert (parameters['b' + str(l)].shape == (layer_dims[l], 1))
return parameters
编写无添加剂向前传播过程:注意,这是主要给测试集使用的
def linear_forward(A, W, b):
'''
隐层/输出层 前向传播的线性组合部分
参数:
A:上一层的激活函数输出 初始值是样本特征矩阵X
W:当前层的权重参数矩阵
b: 当前层的偏置参数向量
返回:
Z:当前层的线性组合输出
cache:元组形式 (A,W,b)
'''
Z = np.dot(W, A) + b
assert (Z.shape == (W.shape[0], A.shape[1]))
cache = (A, W, b)
return Z, cache
def sigmoid(Z):
'''
2分类,输出层采用sigmoid激活函数
输出层前向传播的激活函数部分
参数:
Z:当前层(输出层)的线性组合输出
返回:
A:当前层(输出层)的激活输出
cache: Z
'''
A = 1. / (1 + np.exp(-Z))
cache = Z
assert (A.shape == Z.shape)
return A, cache
def relu(Z):
'''
隐层统一采用relu激活函数
参数:
Z:当前层(隐层)的线性组合输出
返回:
A:当前层(隐层)的激活输出
cache: Z
'''
A = np.maximum(0, Z)
cache = Z
assert (A.shape == Z.shape)
return A, cache
def linear_activation_forward(A_prev, W, b, activation):
'''
隐层(输出层)的前向传播操作,包括线性组合和激活函数两部分
参数:
A_perv:上一层的激活函数输出 初始值是样本特征矩阵X
W:上一层和当前层之间的权重参数矩阵
b: 上一层和当前层之间的偏置参数向量
activation:使用的激活函数类型 一般所有隐层的激活函数是一样的 输出层如果作2分类使用sigmoid
返回:
A: 当前层的激活函数输出
cache:存储重要的中间结果,方便运算。元组形式(linear_cache,activation_cache)=((A_prev,W,b),Z)
'''
if activation == 'sigmoid':
Z, linear_cache = linear_forward(A_prev, W, b) # 线性单元
A, activation_cache = sigmoid(Z) # 激活单元
elif activation == 'relu':
Z, linear_cache = linear_forward(A_prev, W, b) # 线性单元
A, activation_cache = relu(Z) # 激活单元
assert (A.shape == (W.shape[0], A_prev.shape[1]))
cache = (linear_cache, activation_cache)
return A, cache
def L_model_forward(X, parameters):
'''
L层神经网络整体的前向传播 调用之前写好的每层的前向传播 用for循环迭代
参数:
X:数据集的特征矩阵 (n_x,m)
parameters:模型参数
返回:
AL:模型最后的输出
caches:列表形式,存储每一层前向传播的cache=(linear_cache,activation_cache)
=((A_prev,W,b),Z)
对于linear_relu_forward()有L-1项cache 下标0~L-2
对于linear_sigmoid_forward()有1项cache 下标L-1
'''
caches = []
A = X # A0 前向传播初始项
L = len(parameters) // 2 # 神经网络层数(不包含输入层)
# 前向传播通项
# 隐层和输出层激活函数不同 for循环迭代隐层前向传播 输出层前向传播单独算
# 隐层
for l in range(1, L): # l: 1~L-1
A_prev = A
A, cache = linear_activation_forward(A_prev, parameters['W' + str(l)],parameters['b' + str(l)], 'relu')
caches.append(cache)
# 输出层
AL, cache = linear_activation_forward(A, parameters['W' + str(L)],parameters['b' + str(L)], 'sigmoid')
caches.append(cache)
return AL, caches
编写损失函数
def compute_cost(AL, Y):
'''
实现cost函数,计算代价
参数:
AL:输出层的激活输出 模型最终输出 (1,m)
Y:样本的真实标签 0/1 (1,m)
返回:
cost: 交叉熵代价
'''
cost = np.mean(-Y * np.log(AL) - (1 - Y) * np.log(1 - AL))
cost = np.squeeze(cost) # Y和AL都是用2维数组表示的向量 cost算出来是[[cost]],利用squeeze把它变成cost
assert (cost.shape == ())
return cost
无添加剂更新梯度
def update_parameters(parameters, grads, learning_rate):
'''
使用梯度下降法更新模型参数
参数:
parameters:模型参数
grads:计算的参数梯度 字典形式
learning_rate:学习率
返回:
parameters:更新后的参数 字典形式
parameters["W" + str(l)] = ...
parameters["b" + str(l)] = ...
'''
L = len(parameters) // 2 # 神经网络层数(输入层是第0层 不算输入层)
# 一次梯度下降迭代 更新参数
for l in range(L): # l 0~L-1
parameters['W' + str(l + 1)] = parameters['W' + str(l + 1)] - learning_rate * grads['dW' + str(l + 1)]
parameters['b' + str(l + 1)] = parameters['b' + str(l + 1)] - learning_rate * grads['db' + str(l + 1)]
return parameters
一,重要步骤:添加正则(损失函数)

#损失函数加正则
def compute_cost_with_regularization(AL, Y,parameters, lambd):
W1 = parameters['W1']
W2 = parameters['W2']
W3 = parameters['W3']
W4 = parameters['W4']
m = AL.shape[1]
cross_entropy_cost = compute_cost(AL, Y)
L2_reglarization_cost = 1. / m * lambd / 2 * (
np.sum(np.square(W1)) + np.sum(np.square(W2)) + np.sum(np.square(W3) + np.sum(np.square(W4))))
cost = L2_reglarization_cost + cross_entropy_cost
return cost
反向传播加入正则
def sigmoid_backward(dA, cache):
'''
sigmoid激活单元(输出层)的反向传播
参数:
dA:当前层(输出层)激活输出AL的梯度
cache:存储当前层(输出层)的线性组合输出Z,方便激活单元反向传播的计算
返回:
dZ:当前层(输出层)线性组合输出Z的梯度
'''
Z = cache
s = 1. / (1 + np.exp(-Z))
# dZ=dA*(A对Z求导) A=sigmoid(Z) A对Z的导数=A(1-A)
dZ = dA * s * (1 - s)
assert (dZ.shape == Z.shape)
return dZ
def relu_backward(dA, cache):
'''
隐层统一使用relu激活函数
relu激活单元(隐层)的反向传播
参数:
dA:当前层(隐层)激活输出Al的梯度
cache:存储当前层(隐层)的线性组合输出Z,方便激活单元反向传播的计算
返回:
dZ:当前层(隐层)线性组合输出Z的梯度
'''
Z = cache
# dZ=dA*(A对Z求导) 当Z>0时 A对Z求导=1 否则为0
dZ = np.array(dA, copy=True)
dZ[Z <= 0] = 0
assert (dZ.shape == Z.shape)
return dZ
def linear_backward(dZ, cache,lambd): #加入正则项
'''
输出层/隐层 线性单元的反向传播
参数:
dZ:当前层组合输出Z的梯度
cache:存储当前层前向传播的线性单元参数 (A_prev,W,b),方便线性单元反向传播的计算
lambd: 正则参数
返回:
dA_prev:前一层激活输出的梯度
dW:当前层权重参数矩阵的梯度
db:当前层偏置参数向量的梯度
'''
A_prev, W, b = cache
m = A_prev.shape[1] # 样本数
#W 正则求导剩余项
dW = 1. / m * np.dot(dZ, A_prev.T) + lambd / m * W # m个样本的平均梯度
db = 1. / m * np.mean(dZ, axis=1, keepdims=True)
dA_prev = np.dot(W.T, dZ)
assert (dW.shape == W.shape)
assert (db.shape == b.shape)
assert (dA_prev.shape == A_prev.shape)
return dA_prev, dW, db
# 反向传播
def linear_activation_backward(dA, cache,lambd,activation):
"""
输出层\隐层的反向传播操作,包括激活函数和线性组合两部分
dvar 代表 最终输出对var的偏导
参数:
dA:当前层的激活输出梯度dAl 初始值是dAL (代价函数对AL求偏导)
cache:前向传播阶段存储的重要参数和中间结果,便于与反向传播共享参数,方便运算。元组形式(linear_cache,activation_cache)=((A_prev,W,b),Z)
lambd:正则
activation:使用的激活函数类型 一般所有隐层的激活函数是一样的 输出层如果作2分类使用sigmoid
返回:
dA_prev:前一层激活输出的梯度dA(l-1)
dW:当前层权重矩阵的梯度 和当前层W维度一致
db:当前层偏置向量的梯度 和当前层b维度一致
"""
linear_cache, activation_cache = cache
if activation == 'sigmoid':
dZ = sigmoid_backward(dA, activation_cache) # 激活单元反向传播
dA_prev, dW, db = linear_backward(dZ, linear_cache,lambd) # 线性单元反向传播
elif activation == 'relu':
dZ = relu_backward(dA, activation_cache) # 激活单元反向传播
dA_prev, dW, db = linear_backward(dZ, linear_cache,lambd) # 线性单元反向传播
return dA_prev, dW, db
编写加入正则项的梯度更新函数
def backward_propagation_with_regularization(AL, Y, caches, lambd):
'''
L层神经网络整体的反向传播 调用之前写好的每层的反向传播 用for循环迭代
参数:
AL:前向传播最终的输出
Y:数据集样本真实标签 0/1
caches:前向传播缓存的重要参数和中间结果 方便运算
列表形式,存储每一层前向传播的cache=(linear_cache,activation_cache)
=((A_prev,W,b),Z)
对于linear_relu_forward()有L-1项cache 下标0~L-2
对于linear_sigmoid_forward()有1项cache 下标L-1
lambd:正则化系数
返回:
grads:字典形式 存储每一层参数的梯度:
grads["dA" + str(l)] = ...
grads["dW" + str(l)] = ...
grads["db" + str(l)] = ...
'''
grads = {}
L = len(caches) # 网络层数 不包含输入层
m = AL.shape[1]
Y = Y.reshape(AL.shape)
# 反向传播初始项
dAL = -Y / AL + (1 - Y) / (1 - AL)
# 输出层单独计算 隐层统一用for循环计算
current_cache = caches[L - 1] # 输出层前向传播的cache
grads['dA' + str(L)], grads['dW' + str(L)], grads['db' + str(L)] = linear_activation_backward(dAL,current_cache,lambd,'sigmoid') # grads['dAl']实际上是grads['dAl-1'] 便于与dW,db统一处理
for l in reversed(range(L - 1)): # l:L-2~0
current_cache = caches[l]
dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads['dA' + str(l + 2)], current_cache,lambd,'relu')
grads["dA" + str(l + 1)] = dA_prev_temp
grads["dW" + str(l + 1)] = dW_temp
grads["db" + str(l + 1)] = db_temp
return grads
lambd参数 很难调试,需要不断的去试。取值范围摇摆不定,lambd大了会出现训练集欠拟合,lambd太小了会出现过拟合。大家可以尝试一下。
2.编写加入droput的向前传播 因为droput尽量不要与L2正则共用,所以不在能原有的向前传播函数中添加droput函数 我们单独编写一个带有droput函数的向前传播 再编写一个带有droput函数的反向传播dropout是在深度学习中广泛使用的正则化技术。 它在每次迭代中使一些神经单元随机失活.
当你使一些关闭一些神经元, 实际上就简化了模型. dropout的思想就是对于每次迭代,训练的是一个不同的模型(只使用神经元的一个子集). 使用dropout,神经元对之前其他神经元的激活输出不再那么敏感(不会赋予很大的权重),因为这些神经元随时都可能关闭。

带有droput项的向前传播函数
def forward_propagation_with_dropout(X, parameters, keep_prob):
"""
实现带dropout的前向传播: LINEAR -> RELU + DROPOUT -> LINEAR -> RELU + DROPOUT -> LINEAR -> SIGMOID.
参数:
X:输入特征矩阵(nx=2,m)
参数 -- 字典形式 包含 "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape (20, 2)
b1 -- bias vector of shape (20, 1)
W2 -- weight matrix of shape (3, 20)
b2 -- bias vector of shape (3, 1)
W3 -- weight matrix of shape (1, 3)
b3 -- bias vector of shape (1, 1)
keep_prob - 使用dropout的层的单元保留概率
返回:
A3 :模型前向传播输出 (1,m)
cache :前向传播的缓存结果 便于与反向传播共享参数 元组形式
"""
np.random.seed(1)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
W4 = parameters['W4']
b4 = parameters['b4']
Z1 = np.dot(W1, X) + b1
A1,_ = relu(Z1)
D1 = np.random.rand(A1.shape[0], A1.shape[1])
#移除第一层的droput
# D1 = (D1 < keep_prob)
# A1 = A1 * D1
# A1 /= keep_prob
Z2 = np.dot(W2, A1) + b2
A2,_ = relu(Z2)
D2 = np.random.rand(A2.shape[0], A2.shape[1])
#移除第二层的droput
# D2 = (D2 < keep_prob)
# A2 = A2 * D2
# A2 /= keep_prob
Z3 = np.dot(W3, A2) + b3
A3,_ = relu(Z3)
D3 = np.random.rand(A3.shape[0], A3.shape[1])
D3 = (D3 < keep_prob)
A3 = A3*D3
A3 /= keep_prob
Z4 = np.dot(W4,A3)+b4
A4,_ = sigmoid(Z4)
cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3,D3, A3, W3, b3,Z4,A4,W4,b4)
return A4, cache
在使用droput时,我发现神经网络隐藏层每层加入droput,会出现训练的模型拟合度非常低,在我关闭隐藏层: 第一层,和第二层,该拟合度低的现象出现了缓解。
编写带有droput的反向传播因为向前传播过程中我剔除了 隐藏层一、隐藏层二、的droput
所以在 反向传播 过程中 要与向前传播一致。同样剔除 1层,2层的droput
def backward_propagation_with_dropout(X, Y, cache, keep_prob):
"""
实现带dropout的反向传播
参数:
X:输入特征矩阵(nx=2,m)
Y: 样本真实标签(1,m)
cache:forward_propagation_with_dropout()缓存的结果,并与共享参数
keep_prob:使用dropout的层的单元保留概率
返回:
gradients grads:每次迭代后模型中参数的梯度 dZ,dW,db
"""
m = X.shape[1]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, D3,A3, W3, b3,Z4,A4,W4,b4) = cache
dZ4 = A4 - Y
dW4 = 1./m*np.dot(dZ4,A3.T)
db4 = 1. / m * np.sum(dZ4, axis=1, keepdims=True)
dA3 = np.dot(W4.T,dZ4)
dA3 = dA3 * D3
dA3 /= keep_prob
dZ3 = dA3 * np.int64(A3 > 0)
dW3 = 1. / m * np.dot(dZ3, A2.T)
db3 = 1. / m * np.sum(dZ3, axis=1, keepdims=True)
dA2 = np.dot(W3.T, dZ3)
#剔除该层的dropur
# dA2 = dA2 * D2
# dA2 /= keep_prob
dZ2 = dA2 * np.int64(A2 > 0)
dW2 = 1. / m * np.dot(dZ2, A1.T)
db2 = 1. / m * np.sum(dZ2, axis=1, keepdims=True)
dA1 = np.dot(W2.T, dZ2)
#剔除该层的dropur
# dA1 = dA1 * D1
# dA1 /= keep_prob
dZ1 = dA1 * np.int64(A1 > 0)
dW1 = 1. / m * np.dot(dZ1, X.T)
db1 = 1. / m * np.sum(dZ1, axis=1, keepdims=True)
gradients = {'dZ4':dZ4,'dW4':dW4,'db4':db4,'dA3':dA3,
"dZ3": dZ3, "dW3": dW3, "db3": db3, "dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
3.编写加入 Mini-batch、Momentum、adam优化器
1. Mini-batch 梯度下降
分为两步
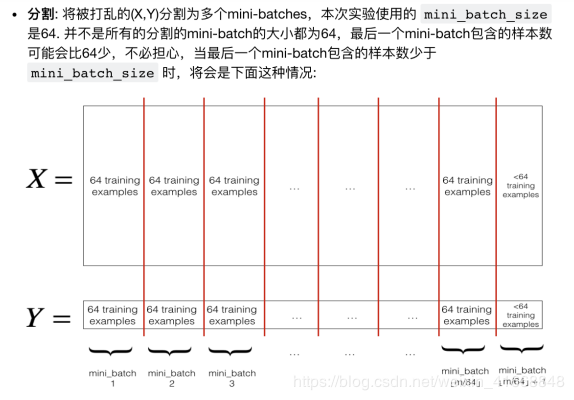

#创建mini-batches
def random_mini_batches(X,Y,mini_batch_size=64,seed=0):
np.random.seed(seed)
m = X.shape[1]
mini_batches = []
#1随机打乱X,Y
permutation = list(np.random.permutation(m)) #生成一个随机序列
shuffled_X = X[:,permutation]
shuffled_Y = Y[:,permutation].reshape((1,m))
#2分割(shuffled_x,shuffled_y)
import math
num_complete_minibatches = math.floor(m/mini_batch_size)
for k in range(0,num_complete_minibatches):
mini_batch_X = shuffled_X[:, k * mini_batch_size:(k + 1) * mini_batch_size]
mini_batch_Y = shuffled_Y[:, k * mini_batch_size:(k + 1) * mini_batch_size]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# 处理特征情况 (最后一个 mini-batch包含的样本 < mini_batch_size)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[:, num_complete_minibatches * mini_batch_size:]
mini_batch_Y = shuffled_Y[:, num_complete_minibatches * mini_batch_size:]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
mini_batches = random_mini_batches(train_x, train_set_y, mini_batch_size)
print("shape of the 1st mini_batch_X: " + str(mini_batches[0][0].shape))
print("shape of the 2nd mini_batch_X: " + str(mini_batches[1][0].shape))
print("shape of the 3rd mini_batch_X: " + str(mini_batches[2][0].shape))
print("shape of the 4rd mini_batch_X: " + str(mini_batches[3][0].shape))
print("shape of the 1st mini_batch_Y: " + str(mini_batches[0][1].shape))
print("shape of the 2nd mini_batch_Y: " + str(mini_batches[1][1].shape))
print("shape of the 3rd mini_batch_Y: " + str(mini_batches[2][1].shape))
print("shape of the 4rd mini_batch_Y: " + str(mini_batches[3][1].shape))

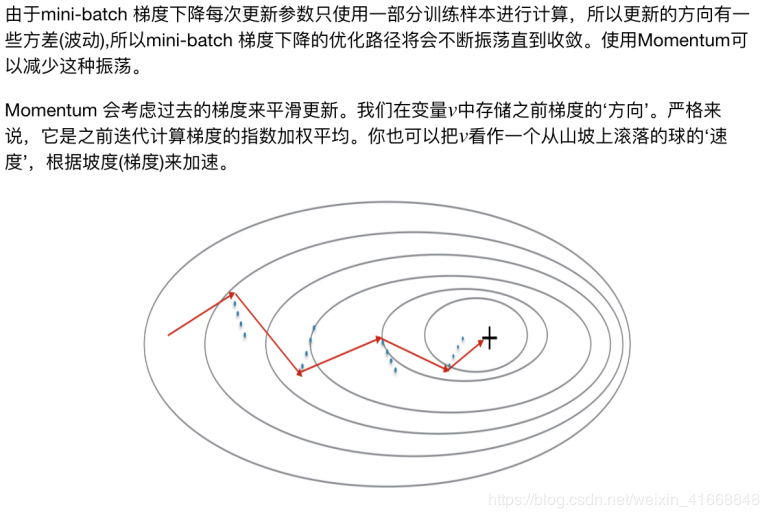
 首先要初始化速度V的参数
for 循环中的 I 从0开始,参数的初始化从1开始,使用(l+1)
首先要初始化速度V的参数
for 循环中的 I 从0开始,参数的初始化从1开始,使用(l+1)
#初始化速度 v,字典形式 RMS
def initialize_velocity(parameters):
"""
初始化每个参数的速度,字典形式:
- keys: "dW1", "db1", ..., "dWL", "dbL"
- values: 与参数/梯度同维的矩阵或向量,初始化为0 W,dW,VdW是同维的
参数:
parameters -- Python字典 包含模型参数.
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
返回:
v -- python字典 包含当前的速度.
v['dW' + str(l)] = velocity of dWl
v['db' + str(l)] = velocity of dbl
"""
L = len(parameters) // 2 # 神经网络的层数
v = {}
# 初始化速度
for l in range(L): # 0~L-1
v['dW' + str(l + 1)] = np.zeros((parameters['W' + str(l + 1)].shape[0], parameters['W' + str(l + 1)].shape[1]))
v['db' + str(l + 1)] = np.zeros((parameters['b' + str(l + 1)].shape[0], parameters['b' + str(l + 1)].shape[1]))
return v
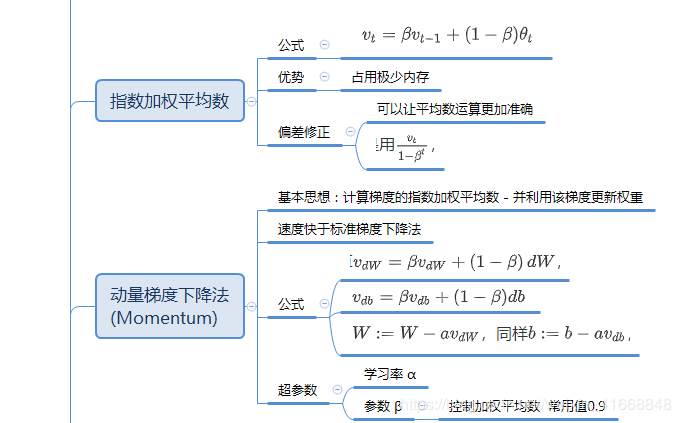
- 编写Momentum参数更新
#实现Momentum梯度更新
def update_parameters_with_momentum(parameters, grads, v, beta, learning_rate):
"""
使用Momentum更新参数
参数:
parameters -- Python字典 包含所有参数:
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
grads -- Python字典包含对所有参数计算的梯度:
grads['dW' + str(l)] = dWl
grads['db' + str(l)] = dbl
v -- Python字典 包含所有参数的当前速度(初始化为0,不断覆盖):
v['dW' + str(l)] = ...
v['db' + str(l)] = ...
beta -- momentum超参数
learning_rate -- 学习率
返回:
parameters -- Python字典 包含更新后的参数
v -- Python字典 包含更新后的速度
"""
L = len(parameters) // 2 # 神经网络层数
# 使用Momentum更新每个参数
for l in range(L):
v['dW' + str(l + 1)] = beta * v['dW' + str(l + 1)] + (1 - beta) * grads['dW' + str(l + 1)]
v['db' + str(l + 1)] = beta * v['db' + str(l + 1)] + (1 - beta) * grads['db' + str(l + 1)]
parameters['W' + str(l + 1)] = parameters['W' + str(l + 1)] - learning_rate * v['dW' + str(l + 1)]
parameters['b' + str(l + 1)] = parameters['b' + str(l + 1)] - learning_rate * v['db' + str(l + 1)]
return parameters, v
实现adam优化
原理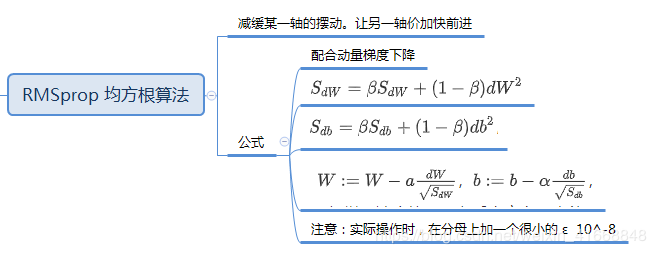
 首先初始化 v,s参数
首先初始化 v,s参数
#RMS+Mom
def initialize_adma(parameters):
L = len(parameters) // 2
v = {}
s = {}
for l in range(L):
v['dW' + str(l+1)] = np.zeros((parameters['W'+str(l+1)].shape[0],parameters['W'+str(l+1)].shape[1]))
v['db' + str(l+1)] = np.zeros((parameters['b'+str(l+1)].shape[0],parameters['b'+str(l+1)].shape[1]))
s['dW' + str(l + 1)] = np.zeros((parameters['W' + str(l + 1)].shape[0], parameters['W' + str(l + 1)].shape[1]))
s['db' + str(l + 1)] = np.zeros((parameters['b' + str(l + 1)].shape[0], parameters['b' + str(l + 1)].shape[1]))
return v,s
编写adam参数更新
主要参数:β1要选0.9、β2要选0.999、ε=10−8β_1要选0.9、β_2要选0.999、ε=10^-8β1要选0.9、β2要选0.999、ε=10−8
#实现RMS+Mom梯度更新
def updata_parameters_with_adam(parameters,grads,v,s,t,learning_rate,beta1,beta2,epsilon):
"""
v - - Python字典
Adam变量
梯度的指数加权平均
s - - Python字典
Adam变量
梯度平方的指数加权平均
learning_rate - - 学习率.
beta1 - - 梯度指数加权平均的超参数
beta2 - - 梯度平方指数加权平均的超参数
epsilon - - 超参数 避免除以0
"""
L = len(parameters) // 2
v_corrected = {}
s_corrected = {}
for l in range(L):
v['dW' + str(l + 1)] = beta1 * v['dW' + str(l + 1)] + (1 - beta1) * grads['dW' + str(l + 1)]
v['db' + str(l + 1)] = beta1 * v['db' + str(l + 1)] + (1 - beta1) * grads['db' + str(l + 1)]
#偏差修正
v_corrected['dW'+str(l+1)] = v['dW'+str(l+1)]/(1-beta1**t)
v_corrected['db'+str(l+1)] = v['db'+str(l+1)]/(1-beta1 ** t)
s['dW' + str(l + 1)] = beta2 * s['dW' + str(l + 1)] + (1 - beta2) * (grads['dW' + str(l + 1)] ** 2)
s['db' + str(l + 1)] = beta2 * s['db' + str(l + 1)] + (1 - beta2) * (grads['db' + str(l + 1)] ** 2)
s_corrected['dW' + str(l + 1)] = s['dW' + str(l + 1)] / (1 - beta2 ** t)
s_corrected['db' + str(l + 1)] = s['db' + str(l + 1)] / (1 - beta2 ** t)
parameters['W' + str(l + 1)] = parameters['W' + str(l + 1)] - learning_rate * (v_corrected['dW' + str(l + 1)] / np.sqrt(s_corrected['dW' + str(l + 1)] + epsilon))
parameters['b' + str(l + 1)] = parameters['b' + str(l + 1)] - learning_rate * (v_corrected['db' + str(l + 1)] / np.sqrt(s_corrected['db' + str(l + 1)] + epsilon))
return parameters, v, s
编写预测函数:
注意事项:droput只用于train,而不能用于test
def predict(X, Y, parameters,keep_prob):
'''
使用训练好的模型进行预测
参数:
X:数据集样本特征矩阵(n_x,m)
Y:数据集样本真实标签 0/1 (1,m)
parameters:训练好的参数
返回:
p:数据集样本预测标签 0/1
'''
# 前向传播
if keep_prob 0.5] = 1
print("Accuracy: " + str(np.mean(p == Y)))
else: #测试集预测专用通道
AL, caches = L_model_forward(X, parameters)
m = X.shape[1]
p = np.zeros((1, m))
p[AL > 0.5] = 1
print("Accuracy: " + str(np.mean(p == Y)))
return p
整合模型
def L_layer_model(X, Y, layers_dims, optimizer,lambd, keep_prob, learning_rate=0.001,num_iterations=2000, print_cost=False):
"""
:param X: 训练集样本特征矩阵(n_x,m_train)
:param Y: 训练集样本标签 0/1 (1,m_train)
:param layers_dims: layers_dims:各层的单元数
:param optimizer: 优化器类别
:param lambd: 正则参数
:param keep_prob: droput参数
:param learning_rate: 学习率
:param num_iterations: 迭代数
:param print_cost: 打印开关
:return: parameters:训练好的参数 字典形式
parameters["W" + str(l)] = ...
parameters["b" + str(l)] = ...
"""
np.random.seed(1)
costs = [] # 存储每100次前向传播计算的代价
# 初始化参数
t = 0 #迭代次数
beta1 = 0.9
beta2 = 0.999
epsilon = 1e-8
seed = 10
mini_batch_size = 64
parameters = initialize_parameters_deep(layers_dims)
# 梯度下降迭代
# batch GD 每次反向传播使用全部样本计算梯度
if optimizer == 'gd':
pass
elif optimizer == 'momentum':
v = initialize_velocity(parameters)
elif optimizer == 'adam':
v,s = initialize_adma(parameters)
for i in range(0, num_iterations):
seed = seed + 1
mini_batches = random_mini_batches(X, Y, mini_batch_size, seed)
for minibatch in mini_batches:
(minibatch_X,minibatch_Y) = minibatch
# 前向传播
if keep_prob == 1: #不使用droput
AL, caches = L_model_forward(minibatch_X, parameters)
elif keep_prob < 1:# 使用droput
AL,caches = forward_propagation_with_dropout(minibatch_X,parameters,keep_prob)
# 计算代价
if lambd == 0: # 不使用L2正则
cost = compute_cost(AL,minibatch_Y)
else:
cost = compute_cost_with_regularization(AL, minibatch_Y, parameters, lambd)
#反向传播计算梯度
if lambd == 0 and keep_prob == 1: #不使用L2也不使用dropout
grads = backward_propagation_with_regularization(AL,minibatch_Y, caches, lambd)
elif lambd != 0: # 使用L2
grads = backward_propagation_with_regularization(AL,minibatch_Y, caches, lambd)
elif keep_prob < 1: #使用dropout
grads = backward_propagation_with_dropout(minibatch_X, minibatch_Y, caches, keep_prob)
# 更新参数
if optimizer == 'gd':
parameters = update_parameters(parameters, grads, learning_rate)
elif optimizer == 'momentum':
parameters,v = update_parameters_with_momentum(parameters, grads, v, beta1, learning_rate)
elif optimizer == 'adam':
t = t + 1
updata_parameters_with_adam(parameters, grads, v, s, t, learning_rate, beta1, beta2, epsilon)
# 每100次迭代打印一次代价 并存储
if print_cost and i % 100 == 0:
print("Cost after iteration {}: {}".format(i, np.squeeze(cost)))
costs.append(cost)
# 绘制代价对迭代次数的变化曲线
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
if __name__ == '__main__':
#定义网络结构
layers_dims = [12288, 20, 7, 5, 1] # 各层的单元数 四层
mini_batch_size = 64
# momentum
parameters = L_layer_model(train_x,train_set_y, layers_dims, optimizer='momentum',lambd=0.001,keep_prob=1,learning_rate = 0.001,num_iterations =2000, print_cost=True)
predictions_train = predict(train_x, train_set_y, parameters,keep_prob=1)
predictions_test = predict(test_x, test_set_y, parameters,keep_prob=1)
在我加入L2正则项后,发现
lambd 越小,准确度会下降关掉L2正则加入droput后发现
3层的droput 会欠拟合 只留一层会好些 增加神经元后,会出现欠拟合。费解了加入mini-btach(动量梯度下降)关闭droput 打开L2
缩小lambd至0.001,增加迭代次数 1000次 拟合的非常好。 1500次 开始出现过拟合 2000次 过拟合 迭代次数往上不再有任何效果了加入adam后
droput = 0.5时,效果非常差,欠拟合 droput = 0.8时,表现不错 关闭droput打开L2 lambd = 0.0001 出现较好效果在此过程中,我不断再调试学习率,最好是编写一个学习率衰减。来进行迭代收缩。
参考:https://blog.csdn.net/sdu_hao/article/details/84978559#5.He%20%E5%88%9D%E5%A7%8B%E5%8C%96
作者:bngu91