纯numpy卷积神经网络实现手写数字识别的实践
前面讲解了使用纯numpy实现数值微分和误差反向传播法的手写数字识别,这两种网络都是使用全连接层的结构。全连接层存在什么问题呢?那就是数据的形状被“忽视”了。比如,输入数据是图像时,图像通常是高、长、通道方向上的3维形状。但是,向全连接层输入时,需要将3维数据拉平为1维数据。实际上,前面提到的使用了MNIST数据集的例子中,输入图像就是1通道、高28像素、长28像素的(1, 28, 28)形状,但却被排成1列,以784个数据的形式输入到最开始的Affine层。
图像是3维形状,这个形状中应该含有重要的空间信息。比如空间上邻近的像素为相似的值、RBG的各个通道之间分别有密切的关联性、相距较远的像素之间没有什么关联等,3维形状中可能隐藏有值得提取的本质模式。但是,因为全连接层会忽视形状,将全部的输入数据作为相同的神经元(同一维度的神经元)处理,所以无法利用与形状相关的信息。而卷积层可以保持形状不变。当输入数据是图像时,卷积层会以3维数据的形式接收输入数据,并同样以3维数据的形式输出至下一层。因此,在CNN中,可以(有可能)正确理解图像等具有形状的数据。
在全连接神经网络中,除了权重参数,还存在偏置。CNN中,滤波器的参数就对应之前的权重,并且,CNN中也存在偏置。
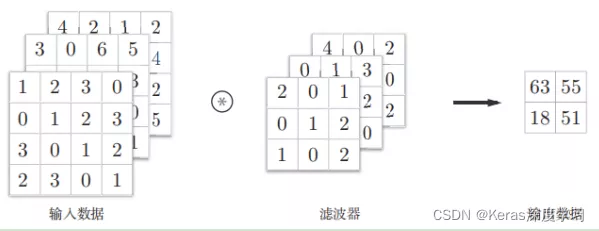
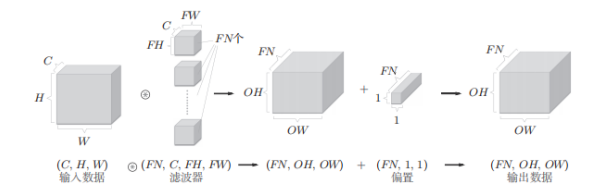
三维数据的卷积运算,通道方向上有多个特征图时,会按通道进行输入数据和滤波器的卷积运算,然后将结果相加,从而得到输出。
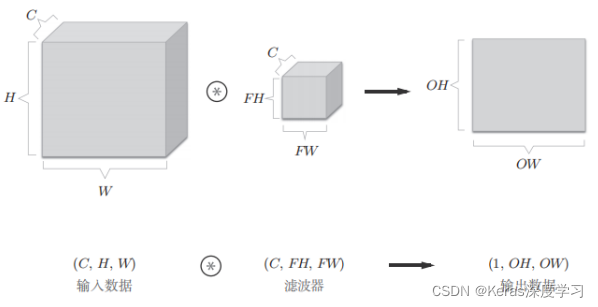
在上面的图中,输出的是一张特征图,换句话说,就是通道数为1的特征图。那么,如果要在通道方向上也拥有多个卷积运算的输出,就应该使用多个滤波器(权重)。

卷积运算的处理流如下:
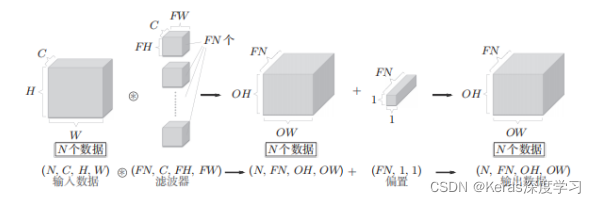
卷积运算的处理流,批处理如下:
而池化层是缩小高、长空间上的运算。
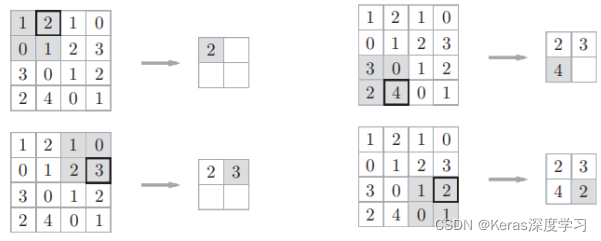
上图是Max池化,取出2x2区域中的最大值元素。除了Max池化外,还有Average池化,在图像识别领域,主要使用Max池化。
网络的构成是“Convolution - ReLU - Pooling -Affine - ReLU - Affine - Softmax”,训练代码如下:
import numpy as np
from collections import OrderedDict
import matplotlib.pylab as plt
from dataset.mnist import load_mnist
import pickle
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
"""
Parameters
----------
input_data : 由(数据量, 通道, 高, 长)的4维数组构成的输入数据
filter_h : 滤波器的高
filter_w : 滤波器的长
stride : 步幅
pad : 填充
Returns
-------
col : 2维数组
"""
N, C, H, W = input_data.shape
out_h = (H + 2*pad - filter_h)//stride + 1
out_w = (W + 2*pad - filter_w)//stride + 1
img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant')
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
for y in range(filter_h):
y_max = y + stride*out_h
for x in range(filter_w):
x_max = x + stride*out_w
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1)
return col
def col2im(col, input_shape, filter_h, filter_w, stride=1, pad=0):
"""
Parameters
----------
col :
input_shape : 输入数据的形状(例:(10, 1, 28, 28))
filter_h :
filter_w
stride
pad
Returns
-------
"""
N, C, H, W = input_shape
out_h = (H + 2*pad - filter_h)//stride + 1
out_w = (W + 2*pad - filter_w)//stride + 1
col = col.reshape(N, out_h, out_w, C, filter_h, filter_w).transpose(0, 3, 4, 5, 1, 2)
img = np.zeros((N, C, H + 2*pad + stride - 1, W + 2*pad + stride - 1))
for y in range(filter_h):
y_max = y + stride*out_h
for x in range(filter_w):
x_max = x + stride*out_w
img[:, :, y:y_max:stride, x:x_max:stride] += col[:, :, y, x, :, :]
return img[:, :, pad:H + pad, pad:W + pad]
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 监督数据是one-hot-vector的情况下,转换为正确解标签的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None # softmax的输出
self.t = None # 监督数据
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
#Affine层的实现
class Affine:
def __init__(self,W,b):
self.W=W
self.b=b
self.x=None
self.dW=None
self.db=None
self.original_x_shape = None
def forward(self,x):
#对于卷积层 需要把数据先展平
self.original_x_shape = x.shape
x=x.reshape(x.shape[0],-1)
self.x=x
out=np.dot(x,self.W)+self.b
return out
def backward(self,dout):
dx=np.dot(dout,self.W.T)
self.dW=np.dot(self.x.T,dout)
self.db=np.sum(dout,axis=0)
# 还原输入数据的形状(对应张量)
dx = dx.reshape(*self.original_x_shape)
return dx
#卷积层的实现
class Convolution:
def __init__(self,W,b,stride=1,pad=0):
self.W=W
self.b=b
self.stride=stride
self.pad=pad
# 中间数据(backward时使用)
self.x = None
self.col = None
self.col_W = None
# 权重和偏置参数的梯度
self.dW = None
self.db = None
def forward(self,x):
#滤波器的数目、通道数、高、宽
FN,C,FH,FW=self.W.shape
#输入数据的数目、通道数、高、宽
N,C,H,W=x.shape
#输出特征图的高、宽
out_h=int(1+(H+2*self.pad-FH)/self.stride)
out_w=int(1+(W+2*self.pad-FW)/self.stride)
#输入数据使用im2col展开
col=im2col(x,FH,FW,self.stride,self.pad)
#滤波器的展开
col_W=self.W.reshape(FN,-1).T
#计算
out=np.dot(col,col_W)+self.b
#变换输出数据的形状
#(N,h,w,C)->(N,c,h,w)
out=out.reshape(N,out_h,out_w,-1).transpose(0,3,1,2)
self.x = x
self.col = col
self.col_W = col_W
return out
def backward(self, dout):
FN, C, FH, FW = self.W.shape
dout = dout.transpose(0,2,3,1).reshape(-1, FN)
self.db = np.sum(dout, axis=0)
self.dW = np.dot(self.col.T, dout)
self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW)
dcol = np.dot(dout, self.col_W.T)
dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
return dx
#池化层的实现
class Pooling:
def __init__(self,pool_h,pool_w,stride=1,pad=0):
self.pool_h=pool_h
self.pool_w=pool_w
self.stride=stride
self.pad=pad
self.x = None
self.arg_max = None
def forward(self,x):
#输入数据的数目、通道数、高、宽
N,C,H,W=x.shape
#输出数据的高、宽
out_h=int(1+(H-self.pool_h)/self.stride)
out_w=int(1+(W-self.pool_w)/self.stride)
#展开
col=im2col(x,self.pool_h,self.pool_w,self.stride,self.pad)
col=col.reshape(-1,self.pool_h*self.pool_w)
#最大值
arg_max = np.argmax(col, axis=1)
out=np.max(col,axis=1)
#转换
out=out.reshape(N,out_h,out_w,C).transpose(0,3,1,2)
self.x = x
self.arg_max = arg_max
return out
def backward(self, dout):
dout = dout.transpose(0, 2, 3, 1)
pool_size = self.pool_h * self.pool_w
dmax = np.zeros((dout.size, pool_size))
dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten()
dmax = dmax.reshape(dout.shape + (pool_size,))
dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1)
dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad)
return dx
#SimpleNet
class SimpleConvNet:
def __init__(self,input_dim=(1,28,28),
conv_param={'filter_num':30,'filter_size':5,'pad':0,'stride':1},
hidden_size=100,
output_size=10,
weight_init_std=0.01):
filter_num=conv_param['filter_num']#30
filter_size=conv_param['filter_size']#5
filter_pad=conv_param['pad']#0
filter_stride=conv_param['stride']#1
input_size=input_dim[1]#28
conv_output_size=int((1+input_size+2*filter_pad-filter_size)/filter_stride)#24
#pool 默认的是2x2最大值池化 池化层的大小变为卷积层的一半30*12*12=4320
pool_output_size=int(filter_num*(conv_output_size/2)*(conv_output_size/2))
#权重参数的初始化部分 滤波器和偏置
self.params={}
#(30,1,5,5)
self.params['W1']=np.random.randn(filter_num,input_dim[0],filter_size,filter_size)*weight_init_std
#(30,)
self.params['b1']=np.zeros(filter_num)
#(4320,100)
self.params['W2']=np.random.randn(pool_output_size,hidden_size)*weight_init_std
#(100,)
self.params['b2']=np.zeros(hidden_size)
#(100,10)
self.params['W3']=np.random.randn(hidden_size,output_size)*weight_init_std
#(10,)
self.params['b3']=np.zeros(output_size)
#生成必要的层
self.layers=OrderedDict()
#(N,1,28,28)->(N,30,24,24)
self.layers['Conv1']=Convolution(self.params['W1'],self.params['b1'],conv_param['stride'],conv_param['pad'])
#(N,30,24,24)
self.layers['Relu1']=Relu()
#池化层的步幅大小和池化应用区域大小相等
#(N,30,12,12)
self.layers['Pool1']=Pooling(pool_h=2,pool_w=2,stride=2)
#全连接层
#全连接层内部有个判断 首先是把数据展平
#(N,30,12,12)->(N,4320)->(N,100)
self.layers['Affine1']=Affine(self.params['W2'],self.params['b2'])
#(N,100)
self.layers['Relu2']=Relu()
#(N,100)->(N,10)
self.layers['Affine2']=Affine(self.params['W3'],self.params['b3'])
self.last_layer=SoftmaxWithLoss()
def predict(self,x):
for layer in self.layers.values():
x=layer.forward(x)
return x
def loss(self,x,t):
y=self.predict(x)
return self.last_layer.forward(y,t)
def gradient(self,x,t):
#forward
self.loss(x,t)
#backward
dout=1
dout=self.last_layer.backward(dout)
layers=list(self.layers.values())
layers.reverse()
for layer in layers:
dout=layer.backward(dout)
#梯度
grads={}
grads['W1']=self.layers['Conv1'].dW
grads['b1']=self.layers['Conv1'].db
grads['W2']=self.layers['Affine1'].dW
grads['b2']=self.layers['Affine1'].db
grads['W3']=self.layers['Affine2'].dW
grads['b3']=self.layers['Affine2'].db
return grads
#计算准确率
def accuracy(self,x,t):
y=self.predict(x)
y=np.argmax(y,axis=1)
if t.ndim !=1:
t=np.argmax(t,axis=1)
accuracy=np.sum(y==t)/float(x.shape[0])
return accuracy
#保存模型参数
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
#载入模型参数
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]
if __name__=='__main__':
(x_train,t_train),(x_test,t_test)=load_mnist(flatten=False)
# 处理花费时间较长的情况下减少数据
x_train, t_train = x_train[:5000], t_train[:5000]
x_test, t_test = x_test[:1000], t_test[:1000]
net=SimpleConvNet(input_dim=(1,28,28),
conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},
hidden_size=100, output_size=10, weight_init_std=0.01)
train_loss_list=[]
#超参数
iter_nums=1000
train_size=x_train.shape[0]
batch_size=100
learning_rate=0.1
#记录准确率
train_acc_list=[]
test_acc_list=[]
#平均每个epoch的重复次数
iter_per_epoch=max(train_size/batch_size,1)
for i in range(iter_nums):
#小批量数据
batch_mask=np.random.choice(train_size,batch_size)
x_batch=x_train[batch_mask]
t_batch=t_train[batch_mask]
#计算梯度
#误差反向传播法 计算很快
grad=net.gradient(x_batch,t_batch)
#更新参数 权重W和偏重b
for key in ['W1','b1','W2','b2']:
net.params[key]-=learning_rate*grad[key]
#记录学习过程
loss=net.loss(x_batch,t_batch)
print('训练次数:'+str(i)+' loss:'+str(loss))
train_loss_list.append(loss)
#计算每个epoch的识别精度
if i%iter_per_epoch==0:
#测试在所有训练数据和测试数据上的准确率
train_acc=net.accuracy(x_train,t_train)
test_acc=net.accuracy(x_test,t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print('train acc:'+str(train_acc)+' test acc:'+str(test_acc))
# 保存参数
net.save_params("params.pkl")
print("模型参数保存成功!")
print(train_acc_list)
print(test_acc_list)
# 绘制图形
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
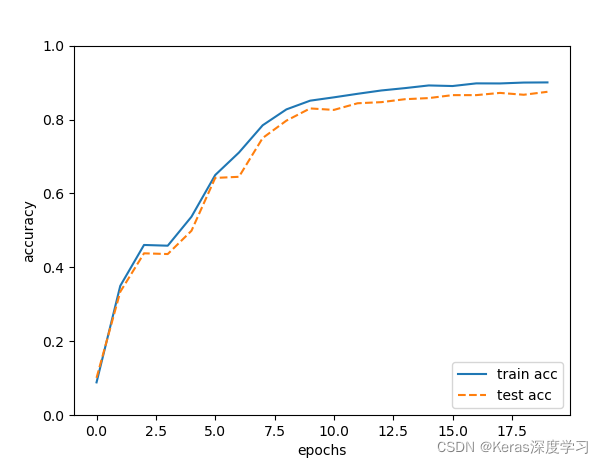
训练过程如下:

训练的结果如图所示:
到此这篇关于纯numpy实现卷积神经网络实现手写数字识别的实践的文章就介绍到这了,更多相关numpy手写数字识别内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!