神经网络的数学原理(一):简单的预测机与分类器模型
计算机擅长的是什么?计算机可以不知疲倦的遵循基本指令做加法运算,而且速度相当之快。拥有这种强大的能力,使得计算机可以执行许多任务——比如说,在互联网上通过管道将0和1输送到计算机重建视频帧的过程只涉及一些加法运算,却使你可以在计算机上观看网络视频。
人类擅长什么?这个问题很难回答——人类擅长的东西太多了。我们来对比一下计算机和人类。人的很多活动的基础都建立在识别上——我们看看四周,将面前的景象收入眼底:左边是一个杯子,右边是一根笔,而面前放着一本厚厚的书——我们将这幅图景拍摄下来,传递给计算机,那么计算机能不能像人类一样识别出这些东西呢?
这种类型的任务对计算机而言并不像播放视频那样容易——因为我们怀疑识别图像需要人类的智能。要想让计算机解决这类问题,我们需要找出新方法,赋予机器一种“人工智能”。
下面,我们将分期讨论这个问题,看看如何使用一些简单的数学和易懂的模型,来解决一个图片识别问题。
1. 从一个简单的预测机中看神经网络的原理当我们看到一个形状的时候,我们的大脑进行了一些思考,然后得出这是一个杯子的结论。我们想让计算机来实现这个功能,但计算机不能思考,只能计算。所以,假如计算机可以执行识别物体之类的任务,那么它的模型是
这就是一台将问题加工成答案的机器,只是加工过程我们还不清楚。
下面,我们来创造一台这样的机器。
我们的机器要把一个量转变为另一个量,就像进行了一次单位换算的操作。我们有了一些数据:
| A | B |
|---|---|
| 0 | 0 |
| 100 | 62.137 |
也就是说,当量A值为0时,对应的量B值为0;当量A值为100时对应的量B值为62.137。
我们希望搭建一台机器:
由于我们知道这个转化过程很简单,所以假设A和B具有线性关系:
有了这个模型,我们只需要确定k的值就完成了这个机器。考虑到现实中很多问题不是线性的,也就是说不能用简单的数学公式表达,所以我们不使用A和B的数学关系来求k。我们将采用另一个方式利用已有数据,完成我们的机器。
我们采用这个过程:
既然不知道k的值,我们先随机挑选一个k值,比如k = 0.5。那么,我们输入A = 100,机器将告诉我们B = 50,但实际上B的值是62.137——也就是说,我们的机器产生了误差!
有了误差,我们就可以对机器做一些调整。误差大于0,说明我们的k太小了。我们让k = 0.6,再次输入A = 100。这会,机器告诉我们,B = 60。好了,这会误差是2.137——小了很多。
我们继续消除误差,让k = 0.7:这时,误差变成了-7.863——这回过犹不及了,这个值比先前的误差2.137要更糟,而且负号告诉我们,我们的k太大了(也就是超调了)。现在,我们发现k = 0.6是比较好的。
当然,我们可以选择在更小的幅度内调节k值。比如,k = 0.6太小而k = 0.7太大,我们选择让k = 0.61,这次的误差是1.137,要比2.137的误差更好。
可以看的出来,我们可以通过调整k的值来不断减小误差,直到这个误差小到我们可以接受。那么,我们就得到了一个机器,我们输入A的值,它可以给出一个B的值,而且我们有理由相信这个值足够准确。这样,我们就有了一台简单的预测器——输入A的值,它将预测B的值。
这样,我们其实已经浏览了一遍神经网络的核心过程。让我们来梳理一下:
我们使用数据来训练机器,使得输出不断接近正确答案。 在训练的过程中,我们尝试得到一个答案,求解误差,再对答案更正——这个过程可能会进行多次。这种方式被称为迭代。 2. 另一个例子——简单的分类器 简单的分类器是什么样的:我们已经构建好了一个核心是线性函数的预测器,我们可以通过计算误差进行迭代以提高输出的精度。这个预测器可以接受输入,进行预测,输出结果。
使用这种思路,我们还可以搭建一个分类器:
假设我们有一些物体。为了简化问题,假设这些物体只能被分成X类和Y类。我们只需测量这些物体的两个特征值,并将其画在坐标系中:
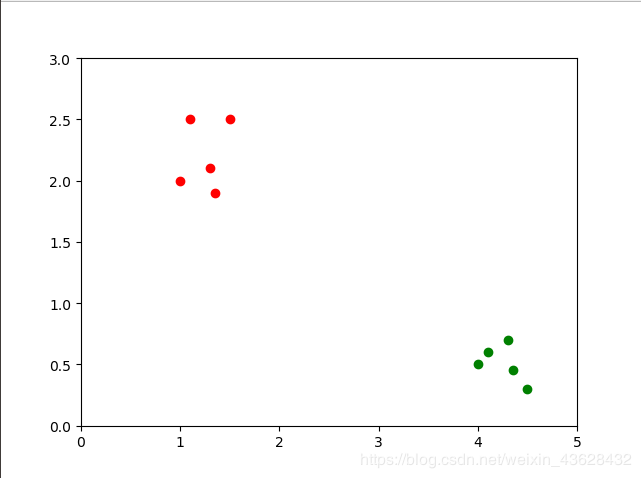
图中,两条坐标轴代表了两种特征值,图中的散点可以代表这些物体。可以看到,它们明显的分成了两类。我们想要一个分类器,那么我们可以用一条线把它们分开,像这样:
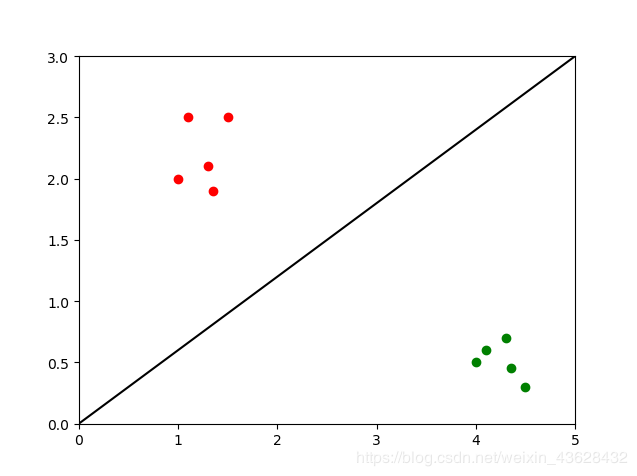
这样,我们就有了一个简单的分类器。有了这个分类器,我们拿到一个新的物体时只需要测量其两个特征值,然后将它画在图上,看看它在直线的哪一侧——我们有理由相信直线某一侧的物体是同一类。
同时,这条关键的直线其实也是一个线性函数,也就是说,我们可以通过调整斜率来调整这个分类器。这个调整过程和得到一个预测器很类似:我们要通过已有数据来对模型进行训练。
训练分类器假设我们有了一组数据:
| 实例 | 特征x | 特征y |
|---|---|---|
| 1 | 3.0 | 1.0 |
| 2 | 1.0 | 3.0 |
我们把它们叫做训练样本,它们在图像上的表现是
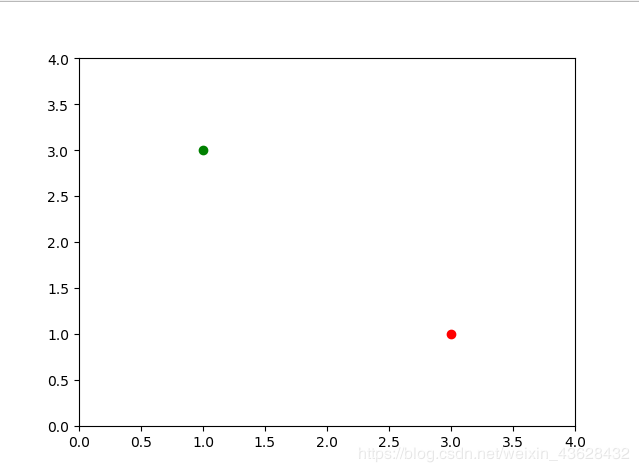
我们要用一条直线y = k·x来进行分类,同样的,我们来随机选择一个数值k = 0.25。这样,x = 3.0时y = 0.75。我们如何计算误差值呢?首先,我们要确定目标值——目标值应该比实际的y值,也就是1.0大一点,以避免直线恰好落在这个点上。我们使用1.1作为期望目标值,这样,误差E = 1.1 - 0.75 = 0.35!
我们要用这个误差值来调整斜率k:我们有了y = k·x和误差值E,它们之间有什么关系呢?我们假设期望值为t,用t = (k + Δk)·x来表示,那么E = t - y,展开并化简,我们就得到了E = Δk·x!我们要对斜率k进行调整,而调整的大小Δk = E / x。
现在,我们的误差值E = 0.35,x = 3.0,我们要调整的Δk = 0.35 / 3.0 = 0.1167。这样,我们就可以把最初的斜率更新为0.25 + 0.1167 = 0.3667了。
我们完成了对一个实例的训练,下面我们来从另一个实例中学习:我们将x = 1.0带入更新后的直线,得到y = 0.3667,这与训练样本中的3.0相差很大。这次我们的期望值选择为2.9,误差E = 2.5333。我们再次改进斜率,Δk = 2.5333 / 1.0 = 2.5333,新的k = 2.5333 + 0.3667 = 2.9。
我们来画出这条直线:
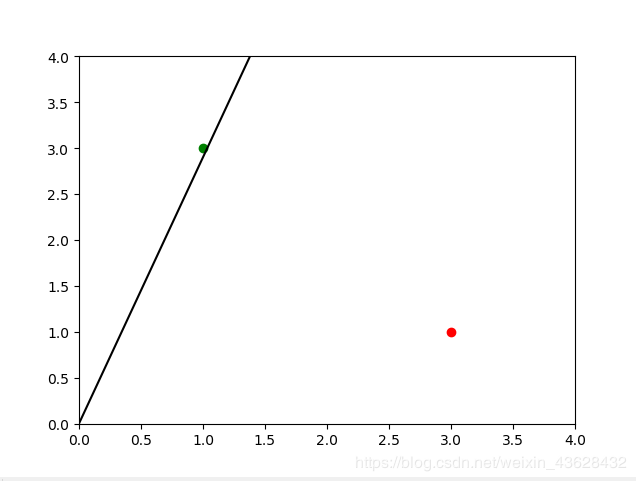
这个分类器并没有很好的把两个点分开!
实际上,我们仔细考虑前面的计算过程,可以发现这样的计算过程会抛弃先前所有训练样本的学习成果,而只保留最后一个实例的学习。所以,训练得到的直线将和最后一次训练样本非常匹配,而完全不顾其它的数据。
我们的分类器存在问题。在机器学习中,这个问题的解决思路被称为适度改进。我们不能使改进过于激烈,而应该部分的使用Δk。这样,我们想要引入一个学习率L,使得Δk = L(E / x)。有了L,我们不但可以保留先前迭代周期中学到的“知识”,而且可以抑制错误的训练数据——我们其实无法保证训练样本是完全正确的。
下面我们使用新的计算过程来进行训练:
选择学习率L = 0.5。
初始k = 0.25,使用第一个训练样本x = 3.0,这时y = 0.75,期望值为1.1,误差值为0.35。那么,Δk = 0.5 * 0.35 / 3.0 = 0.0583,更新的k = 0.25 + 0.0583 = 0.3083。
我们继续这个过程:x = 1.0时,y = 0.3083,期望值为2.9,误差值E = 2.9 - 0.3083 = 2.5917。那么,Δk = 0.5 * 2.5917 / 1.0 = 1.2958,最终的k值为1.2958 + 0.3083,即1.6042。
我们来看看现在的分类器:

这次引入了学习率,我们得到了更好的结果!
*这样,我们已经理解了一些神经网络中的重要概念:学习率与适度改进,迭代和训练。*之后,我们将正式引入神经网络的概念。
作者:NumLock桌