tensorflow 神经网络做中文情感分析
本文使用哈工大分词做文本预处理; 两层隐层神经网络;
# -*- coding: utf-8 -*-
# @bref :使用tensorflow做中文情感分析
import numpy as np
import tensorflow as tf
import random
from sklearn.feature_extraction.text import CountVectorizer
import os
import traceback
# 读取当前的文件路径
# D:\PycharmProjects2020\tensor1\gensiom_word2vec
real_dir_path = os.path.split(os.path.realpath(__file__))[0]
# 对文件路径进行拼接D:\PycharmProjects2020\tensor1\gensiom_word2vec\data/pos_bak.txt
pos_file = os.path.join(real_dir_path, 'data/pos_bak.txt')
neg_file = os.path.join(real_dir_path, 'data/neg_bak.txt')
# 使用哈工大分词和词性标注
from pyltp import Segmentor, Postagger
# 导入分词模型
seg = Segmentor()
seg.load('F:\modelmodel\ltp_data_v3.4.0\cws.model')
# 导入标记模型
poser = Postagger()
poser.load('F:\modelmodel\ltp_data_v3.4.0\pos.model')
# 当前文件所在路径
real_dir_path = os.path.split(os.path.realpath(__file__))[0]
# 停用词路径
stop_words_file = os.path.join(real_dir_path, '../util/stopwords.txt')
# 定义允许的词性 LTP 使用 863 词性标注集,详细请参考 词性标准集。
allow_pos_ltp = ('a', 'i', 'j', 'n', 'nh', 'ni', 'nl', 'ns', 'nt', 'nz', 'v', 'ws')
#分词、去除停用词、词性筛选
# 这个方法可以把s="今 天去 钓 鱼了 你 去么" 过滤成为['今天', '钓鱼']
def cut_stopword_pos(s):
# s.split()是为了把"今 天去 钓 鱼了 你 去么"改成 今天去钓鱼了你去么
# 便于后边的sement进行分词
words = seg.segment(''.join(s.split()))
# 标记今天|去|钓鱼|了|你|去|么
# nt|v|v|u|r|v|u
poses = poser.postag(words)
# {',': None, '?': None, '、': None, '。': None,
stopwords = {}.fromkeys([line.rstrip() for line in open(stop_words_file,encoding='UTF-8')])
sentence = []
#for i, pos in enumerate(poses):这段话执行如下
# 0 nt
# 1 wp
# 2 n
# 3 v
for i, pos in enumerate(poses):
if (pos in allow_pos_ltp) and (words[i] not in stopwords):
sentence.append(words[i])
return sentence
# 读取文本把过滤成这种dict_keys(['心得', '勘误', '疑点', '兴趣', '朋友', '访问', '网站', '交流', '切磋', 'www',
def create_vocab(pos_file, neg_file):
def process_file(file_path):
with open(file_path, 'r',encoding='UTF-8') as f:
v = []
lines = f.readlines()
for line in lines:
sentence = cut_stopword_pos(line)
v.append(' '.join(sentence))
return v
sent = process_file(pos_file)
sent += process_file(neg_file)
# CountVectorizer(max_df=0.9, min_df=1)
tf_v = CountVectorizer(max_df=0.9, min_df=1)
tf = tf_v.fit_transform(sent)
#print tf_v.vocabulary_
return tf_v.vocabulary_.keys()
#获取词汇
vocab = create_vocab(pos_file, neg_file)
#依据词汇将评论转化为向量
def normalize_dataset(vocab):
dataset = []
# vocab:词汇表; review:评论; clf:评论对应的分类, [0, 1]表示负面评论,[1, 0]表示正面
def string_to_vector(vocab, review, clf):
words = cut_stopword_pos(review) # list of str
# 看有几个坑就放几个0,,[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]14个坑14个0
features = np.zeros(len(vocab))
# 遍历cut_stopword_pos处理后的review 如果review的词在词汇表vocab
for w in words:
if w.encode('utf-8') in vocab:
features[vocab.index(w.encode('utf-8'))] = 1
return [features, clf]
with open(pos_file, 'r',encoding='UTF-8') as f:
lines = f.readlines()
for line in lines:
one_sample = string_to_vector(vocab, line, [1, 0])
dataset.append(one_sample)
with open(neg_file, 'r',encoding='UTF-8') as f:
lines = f.readlines()
for line in lines:
one_sample = string_to_vector(vocab, line, [0, 1])
dataset.append(one_sample)
return dataset
# 把vocab放进这个方法
dataset = normalize_dataset(vocab)
random.shuffle(dataset) #打乱顺序
#取样本的10%作为测试数据
# len(dataset)元素的个数
test_size = int(len(dataset) * 0.1)
dataset = np.array(dataset)
train_dataset = dataset[:-test_size]
test_dataset = dataset[-test_size:]
# print 'test_size = {}'.format(test_size)
print('test_size = {}'.format(test_size))
#print 'size of train_dataset is {}'.format(train_dataset)
#Feed-forward nueral network
#定义每个层有多少个神经元
n_input_layer = len(vocab) #输入层每个神经元代表一个term
n_layer_1 = 1000 #hiden layer
n_layer_2 = 1000 # hiden layer
n_output_layer = 2
#定义待训练的神经网络
def neural_netword(data):
#定义第一层神经元的w和b, random_normal定义服从正态分布的随机变量
layer_1_w_b = {'w_':tf.Variable(tf.random_normal([n_input_layer, n_layer_1])), 'b_':tf.Variable(tf.random_normal([n_layer_1]))}
layer_2_w_b = {'w_':tf.Variable(tf.random_normal([n_layer_1, n_layer_2])), 'b_':tf.Variable(tf.random_normal([n_layer_2]))}
layer_output_w_b = {'w_':tf.Variable(tf.random_normal([n_layer_2, n_output_layer])), 'b_':tf.Variable(tf.random_normal([n_output_layer]))}
layer_1 = tf.add(tf.matmul(data, layer_1_w_b['w_']), layer_1_w_b['b_'])
layer_1 = tf.nn.relu(layer_1) #relu做激活函数
layer_2 = tf.add(tf.matmul(layer_1, layer_2_w_b['w_']), layer_2_w_b['b_'])
layer_2 = tf.nn.relu(layer_2)
layer_output = tf.add(tf.matmul(layer_2, layer_output_w_b['w_']), layer_output_w_b['b_'])
return layer_output
batch_size = 50
X = tf.placeholder('float', [None, n_input_layer]) #None表示样本数量任意; 每个样本纬度是term数量
Y = tf.placeholder('float')
#使用数据训练神经网络
def train_neural_network(X, Y):
predict = neural_netword(X)
#cost func是输出层softmax的cross entropy的平均值。 将softmax 放在此处而非nn中是为了效率.
cost_func = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=predict, labels=Y))
#设置优化器
optimizer = tf.train.AdamOptimizer().minimize(cost_func)
epochs = 13 #epoch本意是时代、纪, 这里是迭代周期
with tf.Session() as session:
session.run(tf.initialize_all_variables()) #初始化所有变量,包括w,b
random.shuffle(train_dataset)
train_x = train_dataset[:, 0] #每一行的features;
train_y = train_dataset[:, 1] #每一行的label
# print 'size of train_x is {}'.format(len(train_x))
print('size of train_x is {}'.format(len(train_x)))
for epoch in range(epochs):
epoch_loss = 0 #每个周期的loss
i = 0
while i < len(train_x):
start = i
end = i + batch_size
batch_x = train_x[start:end]
batch_y = train_y[start:end]
#run的第一个参数fetches可以是单个,也可以是多个。 返回值是fetches的返回值。
#此处因为要打印cost,所以cost_func也在fetches中
_, c = session.run([optimizer, cost_func], feed_dict={X:list(batch_x), Y:list(batch_y)})
epoch_loss += c
i = end
print(epoch, ' : ', epoch_loss)
#评估模型
test_x = test_dataset[:, 0]
test_y = test_dataset[:, 1]
#argmax能给出某个tensor对象在某一维上的其数据最大值所在的索引值, 这里是索引值的list。tf.equal用于检测匹配,返回bool型的list
correct = tf.equal(tf.argmax(predict, 1), tf.argmax(Y, 1))
#tf.cast 可以将[True, False, True] 转化为[1, 0, 1]
#reduce_mean用于在某一维上计算平均值, 未指定纬度则计算所有元素
accurqcy = tf.reduce_mean(tf.cast(correct, 'float'))
print('准确率: {}'.format(accurqcy.eval({X:list(test_x), Y:list(test_y)})))
#等价: print session.run(accuracy, feed_dict={X:list(test_x), Y:list(test_y)})
train_neural_network(X, Y)
输出结果:
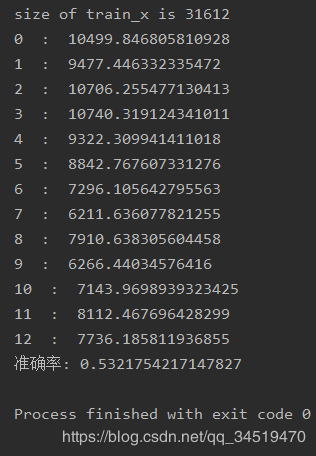
杂乱分析代码:
import numpy as np
import tensorflow as tf
import random
from sklearn.feature_extraction.text import CountVectorizer
import os
import traceback
# 读取当前的文件路径
# D:\PycharmProjects2020\tensor1\gensiom_word2vec
real_dir_path = os.path.split(os.path.realpath(__file__))[0]
# 对文件路径进行拼接D:\PycharmProjects2020\tensor1\gensiom_word2vec\data/pos_bak.txt
pos_file = os.path.join(real_dir_path, 'data/pos_bak.txt')
neg_file = os.path.join(real_dir_path, 'data/neg_bak.txt')
# 使用哈工大分词和词性标注
from pyltp import Segmentor, Postagger
# 导入分词模型
seg = Segmentor()
seg.load('F:\modelmodel\ltp_data_v3.4.0\cws.model')
# 导入标记模型
poser = Postagger()
poser.load('F:\modelmodel\ltp_data_v3.4.0\pos.model')
# 当前文件所在路径
real_dir_path = os.path.split(os.path.realpath(__file__))[0]
# 停用词路径
stop_words_file = os.path.join(real_dir_path, '../util/stopwords.txt')
# 定义允许的词性 LTP 使用 863 词性标注集,详细请参考 词性标准集。
allow_pos_ltp = ('a', 'i', 'j', 'n', 'nh', 'ni', 'nl', 'ns', 'nt', 'nz', 'v', 'ws')
#分词、去除停用词、词性筛选
# word=seg.segment('今天去钓鱼了你去么')
word1="今 天去 钓 鱼了 你 去么"
print(''.join(word1.split()))
a=seg.segment(''.join(word1.split()))
print(
'|'.join(a)
)
poses = poser.postag(a)
print(
'|'.join(poses)
)
stopwords = {}.fromkeys(
[
line.rstrip() for line in open(stop_words_file,encoding='UTF-8')
]
)
# stopwords = {}.fromkeys([line.rstrip() for line in open(stop_words_file)])
print(stopwords)
# for i, pos in enumerate(poses):
#
# print(i,pos)
sentence=[]
for i, pos in enumerate(poses):
if (pos in allow_pos_ltp) and (a[i] not in stopwords):
sentence.append(a[i])
print(sentence)
# --------------------------------------------------------------------
def cut_stopword_pos(s):
# s.split()是为了把"今 天去 钓 鱼了 你 去么"改成 今天去钓鱼了你去么
# 便于后边的sement进行分词
words = seg.segment(''.join(s.split()))
# 标记今天|去|钓鱼|了|你|去|么
# nt|v|v|u|r|v|u
poses = poser.postag(words)
# {',': None, '?': None, '、': None, '。': None,
stopwords = {}.fromkeys([line.rstrip() for line in open(stop_words_file,encoding='UTF-8')])
sentence = []
# 0 nt
# 1 wp
# 2 n
# 3 v
for i, pos in enumerate(poses):
if (pos in allow_pos_ltp) and (words[i] not in stopwords):
sentence.append(words[i])
return sentence
# ----------------------------------------------------
real_dir_path = os.path.split(os.path.realpath(__file__))[0]
# 对文件路径进行拼接D:\PycharmProjects2020\tensor1\gensiom_word2vec\data/pos_bak.txt
aaa = os.path.join(real_dir_path, 'data/pos.txt')
bbb = os.path.join(real_dir_path, 'data/neg.txt')
def process_file(file_path):
with open(file_path, 'r',encoding='UTF-8') as f:
v = []
lines = f.readlines()
for line in lines:
sentence = cut_stopword_pos(line)
v.append(' '.join(sentence))
return v
# -------------------------------------------------------
def create_vocab(pos_file, neg_file):
def process_file(file_path):
with open(file_path, 'r',encoding='UTF-8') as f:
v = []
lines = f.readlines()
for line in lines:
sentence = cut_stopword_pos(line)
v.append(' '.join(sentence))
return v
sent = process_file(pos_file)
sent += process_file(neg_file)
tf_v = CountVectorizer(max_df=0.9, min_df=1)
tf = tf_v.fit_transform(sent)
#print tf_v.vocabulary_
return tf_v.vocabulary_.keys()
#获取词汇
vocab = create_vocab(aaa, bbb)
print(vocab)
features = np.zeros(len(vocab))
print(features)
print(np.zeros(len(word1)))
# ----------------------------------------------------------
def normalize_dataset(vocab):
dataset = []
# vocab:词汇表; review:评论; clf:评论对应的分类, [0, 1]表示负面评论,[1, 0]表示正面
def string_to_vector(vocab, review, clf):
words = cut_stopword_pos(review) # list of str
# 看有几个坑就放几个0,,[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]14个坑14个0
features = np.zeros(len(vocab))
# 遍历cut_stopword_pos处理后的review 如果review的词在词汇表vocab
for w in words:
if w.encode('utf-8') in vocab:
features[vocab.index(w.encode('utf-8'))] = 1
return [features, clf]
with open(aaa, 'r',encoding='UTF-8') as f:
lines = f.readlines()
for line in lines:
one_sample = string_to_vector(vocab, line, [1, 0])
dataset.append(one_sample)
with open(bbb, 'r',encoding='UTF-8') as f:
lines = f.readlines()
for line in lines:
one_sample = string_to_vector(vocab, line, [0, 1])
dataset.append(one_sample)
return dataset
# ------------------------------------------------------------
# for i in normalize_dataset(vocab):
# print(i)
dataset = normalize_dataset(vocab)
random.shuffle(dataset) #打乱顺序
# ------------------------------------------------------------
#取样本的10%作为测试数据 len(dataset)元素的个数
test_size = int(len(dataset) * 0.1)
print(test_size)
print(np.array(dataset))
print(len(vocab))
# ------------------------------------------------------------
#Feed-forward nueral network
#定义每个层有多少个神经元
n_input_layer = len(vocab) #输入层每个神经元代表一个term
n_layer_1 = 1000 #hiden layer
n_layer_2 = 1000 # hiden layer
n_output_layer = 2
layer_1_w_b = {'w_': tf.Variable(tf.random_normal([n_input_layer, n_layer_1])),
'b_': tf.Variable(tf.random_normal([n_layer_1]))}
# ------------------------------------------------------------
if __name__ == '__main__':
cut_stopword_pos(word1)
print(cut_stopword_pos(word1))
process_file(aaa)
print(process_file(aaa))
作者:李圣经언니