飞桨深度学习学院-Python小白逆袭大神Day(4)笔记
Python小白逆袭大神Day4-《青春有你2》选手识别作业:对测试的图片进行分类代码详解步骤一步骤二步骤三步骤四步骤五步骤六
Day4-《青春有你2》选手识别
作业:对测试的图片进行分类
作者:禾-Ming

爬取5位参赛选手的照片,制作训练集。这里放上我借鉴的数据集
链接: link.
(#CPU环境启动请务必执行该指令
%set_env CPU_NUM=1 )这句可不运行,后边使用GPU
由于下载的照片名称不对,所以需要对文件进行文件名的修改,代码如下:
def rename(path):
filelist = os.listdir(path)
count = 1
for item in filelist:
src = os.path.join(os.path.abspath(path), item)
dst = os.path.join(os.path.abspath(path), '0' + format(str(i), '0>4s') + '.jpg')
os.rename(src, dst)
count = count + 1
其中path为dataset/train/anqi,以此类推其余四位参赛选手。
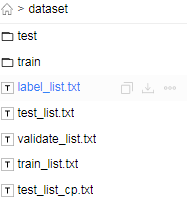
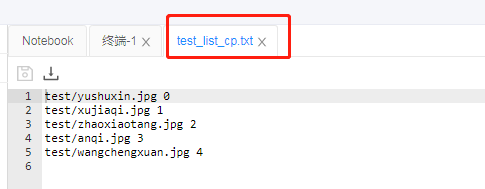
制作train_list.txt
import os
def get_train_tlist():
result=[]
path = "dataset/train"
stars = {'yushuxin': 0, 'xujiaqi': 1, 'zhaoxiaotang': 2, 'anqi': 3, r'wangchengxuan': 4}
for root, dirs, files in os.walk(path):
for item in files:
item_path = os.path.join(root, item)
res='t'+item_path.strip('dataset/')
# print(item_path)
# print(res)
name=item[:-8]
# print(name)
# print(' %s %d'% (res, stars[name]))
result.append('%s %d' % (res, stars[name]))
return result
train_list=get_train_tlist()
with open("./dataset/train_list.txt", "w") as f:
for line in train_list:
f.writelines(line)
f.writelines("\n")
步骤四
由于没有制作validate_list.txt,并且需要将test_list_file="test_list_cp.txt"修改,所以数据准备中的代码需作如下修改:
from paddlehub.dataset.base_cv_dataset import BaseCVDataset
class DemoDataset(BaseCVDataset):
def __init__(self):
# 数据集存放位置
self.dataset_dir = "dataset"
super(DemoDataset, self).__init__(
base_path=self.dataset_dir,
train_list_file="train_list.txt",
# validate_list_file="validate_list.txt",
test_list_file="test_list_cp.txt",
label_list_file="label_list.txt",
)
dataset = DemoDataset()
步骤五
注意其中的batch_size=32的修改以及由于没有验证集,所以需要注释掉 eval_interval=3
config = hub.RunConfig(
use_cuda=True, #是否使用GPU训练,默认为False;
num_epoch=3, #Fine-tune的轮数;
checkpoint_dir="cv_finetune_turtorial_demo" ,#模型checkpoint保存路径, 若用户没有指定,程序会自动生成;
batch_size=32, #训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
# eval_interval=3, #模型评估的间隔,默认每100个step评估一次验证集;
log_interval=10,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy()) #Fine-tune优化策略;
步骤六
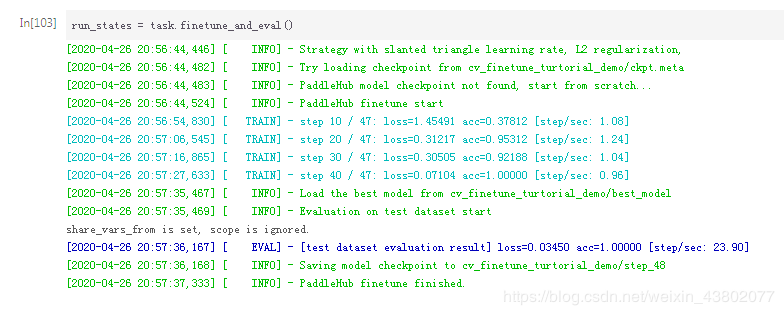
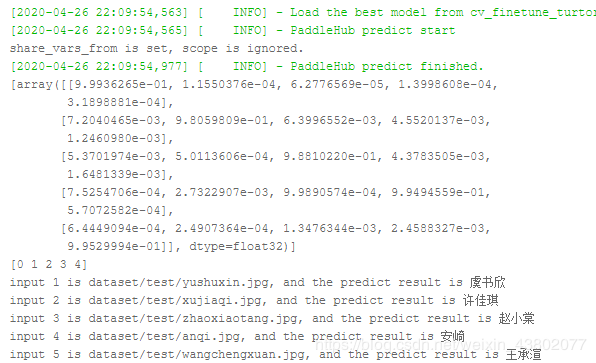
依次运行代码后,预测模型即可得到一下结果:
作者:禾-Ming