深度学习笔记_tensorflow2.0_过拟合(二)
减少过拟合方法:
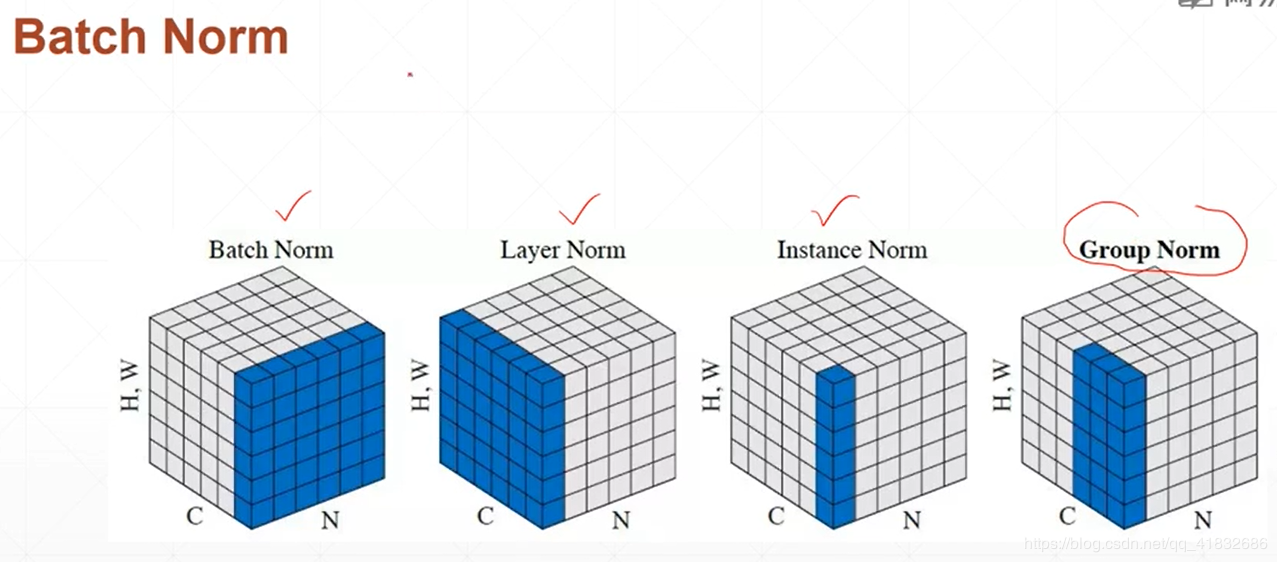
交叉验证 normalization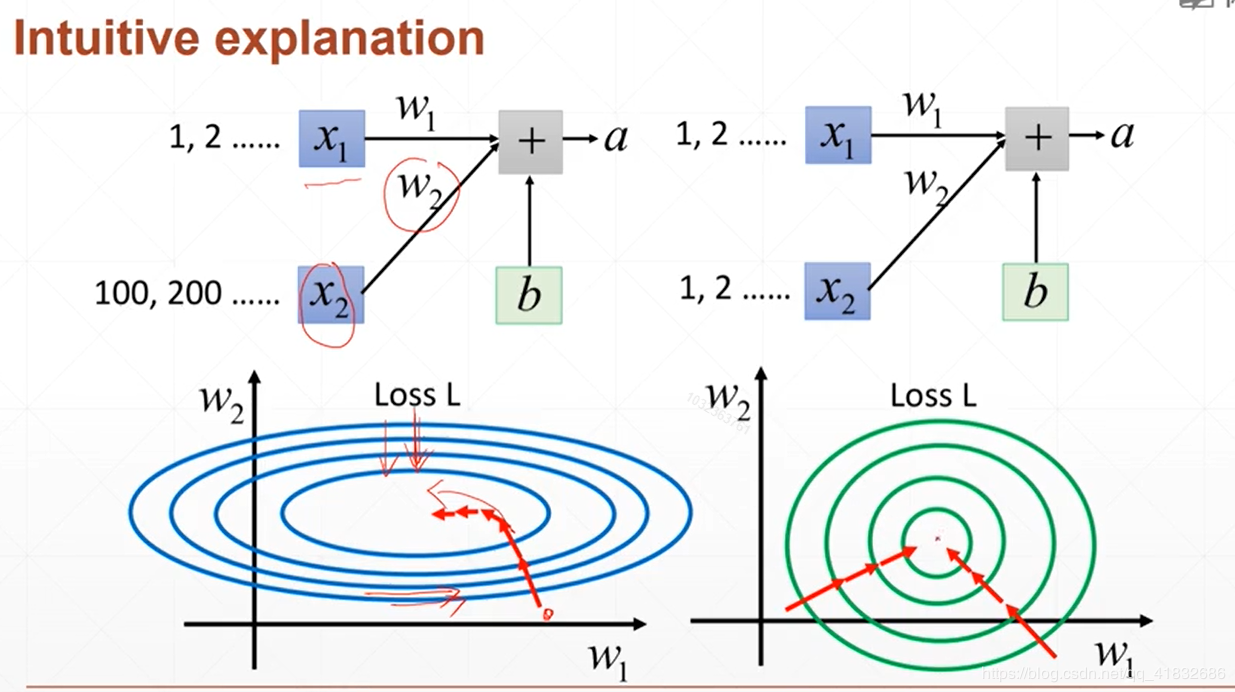
 学习率调整,
learning rate decay
momentum动量调整
学习率调整,
learning rate decay
momentum动量调整
k折交叉检验:

正则化: 更小的权值w,从某种意义上说,表示网络的复 杂度更低,对数据的拟合刚刚好(这个法则也叫做奥卡姆剃刀) 添加正则化相当于参数的解空间添加了约束,限制了模型的复杂度 L1正则化的形式是添加参数的绝对值之和作为结构风险项,L2正则化的形式添加参数的平方和作为结构风险项 L1正则化鼓励产生稀疏的权重,即使得一部分权重为0,用于特征选择;L2鼓励产生小而分散的权重,鼓励让模型做决策的时候考虑更多的特征,而不是仅仅依赖强依赖某几个特征,可以增强模型的泛化能力,防止过拟合。 正则化参数 λ越大,约束越严格,太大容易产生欠拟合。正则化参数 λ越小,约束宽松,太小起不到约束作用,容易产生过拟合。 如果不是为了进行特征选择,一般使用L2正则化模型效果更好。

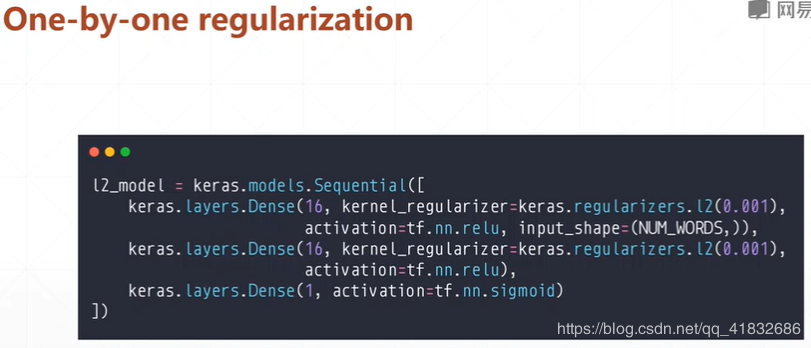
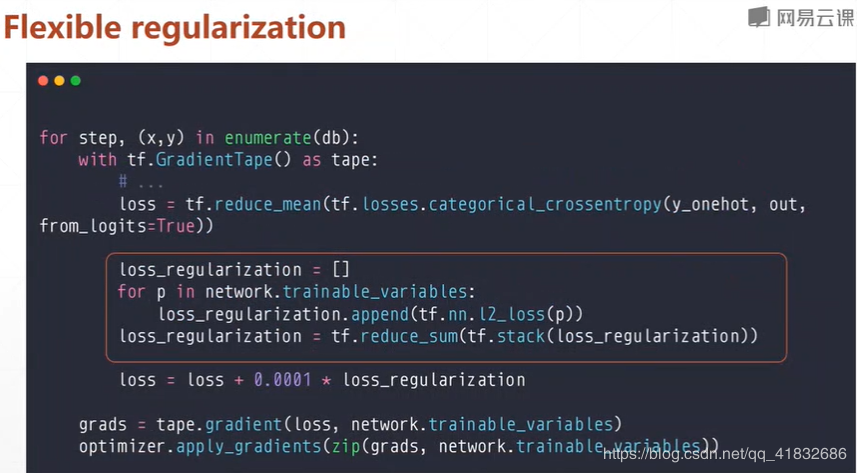
随机梯度下降:
减少显存消耗,sample处batch进行梯度下降计算。
作者:夏季梦幻想