《动手学深度学习》task3
1.过拟合、欠拟合及其解决方案
作者:yq313210
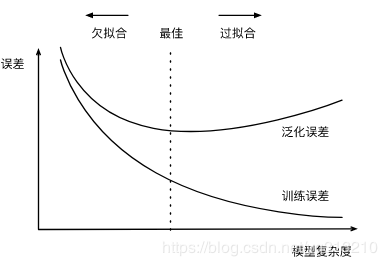
模型训练中经常出现的两类典型问题:
1.模型无法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting);
2.模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)。 在实践中,我们要尽可能同时应对欠拟合和过拟合。虽然有很多因素可能导致这两种拟合问题,我们重点讨论两个因素:模型复杂度和训练数据集大小。
给定训练数据集,模型复杂度和误差之间的关系:

1.关于torch.cat()的用法
cat是concatnate的意思:拼接,联系在一起。
cat的普通用法就是将两个tensor连接在一起
C = torch.cat( (A,B),0 ) #按维数0拼接(竖着拼)
C = torch.cat( (A,B),1 ) #按维数1拼接(横着拼
>>> import torch
>>> A=torch.ones(2,3) #2x3的张量(矩阵)
>>> A
tensor([[ 1., 1., 1.],
[ 1., 1., 1.]])
>>> B=2*torch.ones(4,3) #4x3的张量(矩阵)
>>> B
tensor([[ 2., 2., 2.],
[ 2., 2., 2.],
[ 2., 2., 2.],
[ 2., 2., 2.]])
>>> C=torch.cat((A,B),0) #按维数0(行)拼接
>>> C
tensor([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 2., 2., 2.],
[ 2., 2., 2.],
[ 2., 2., 2.],
[ 2., 2., 2.]])
>>> C.size()
torch.Size([6, 3])
>>> D=2*torch.ones(2,4) #2x4的张量(矩阵)
>>> C=torch.cat((A,D),1)#按维数1(列)拼接
>>> C
tensor([[ 1., 1., 1., 2., 2., 2., 2.],
[ 1., 1., 1., 2., 2., 2., 2.]])
>>> C.size()
torch.Size([2, 7])
另外,cat还可以将list连接起来。
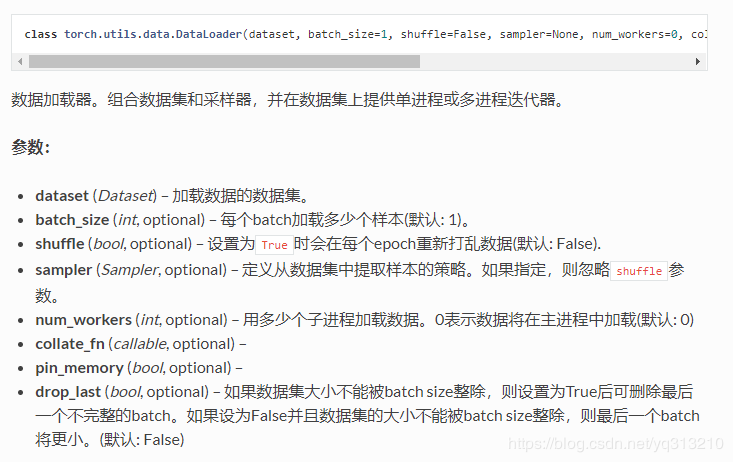
2.设置数据集的方式 参考官方文档
dataset = torch.utils.data.TensorDataset(train_features, train_labels) # 设置数据集
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True) # 设置获取数据方式

3.关于FlattenLayer()的作用
相当于做了一个扁平化 view(,-1)



关于GRU与LSTM 的理解
参考网址:人人都能看懂LSTM
人人都能看懂的GRU
作者:yq313210
相关文章
Iris
2021-08-03
Floria
2021-01-03
Ula
2023-05-13
Jacinda
2023-05-13
Winona
2023-05-13
Fawn
2023-05-13
Echo
2023-05-13
Maha
2023-05-13
Kande
2023-05-15
Viridis
2023-05-17
Pandora
2023-07-07
Tallulah
2023-07-17
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20
Irma
2023-07-20
Kirima
2023-07-20