shell编程-文本文件处理(grep sed awk文本三剑客)
一、grep和正则表达式
1、正则表达式
以一串字符作为表达式向系统传达意思(过滤匹配数据),元字符是描述字符的字符,正则表达式是有一串字符和元字符构成的字符串,主要功能为文本查询和字符串操作,匹配文本
大部分linux只支持基本的正则表达式。
hel*o helo hello hellllo #*前面的l可以为0次或多次匹配
...76.. #.表示可以是任意字符
^cloud #匹配以cloud为首的行
micky$ #匹配以micky结尾的所有行
^$ #匹配空行
[0-9]/[0123456789] #穷举或范围表示
[^0-2] #不再0-2范围的数字
\. #转义特殊符号变普通字符
\ #精确匹配the
\{n\} #匹配前面的字符出现n次
\{n,\} #匹配前面的字符至少出现n次
\{n,m\} #匹配前面的字符出现n-m次
2、grep命令
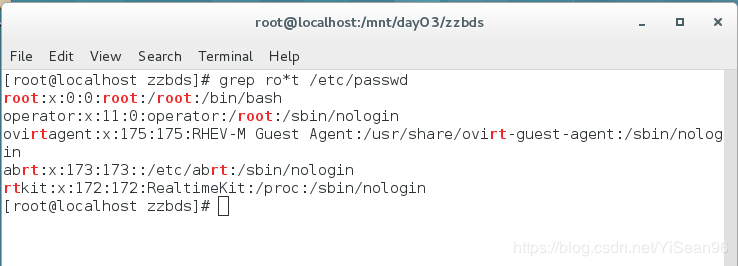
全面搜索正则表达式并显示出来,文本搜索工具,根据用户指定的“模式”进行匹配检查
模式:由正则表达式或者字符以及基本文字字符编辑的过滤条件
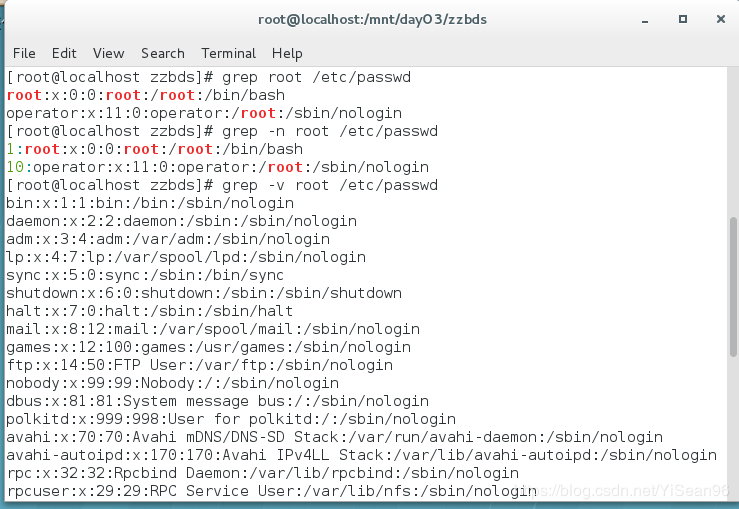
grep -n root /etc/passwd #查找带行号的root
grep -v root /etc/passwd #没有root的行
grep -vc root /etc/passwd #总行数
二、sed编辑器
sed 行编辑器,在线编辑器
vim 交互式编辑器
速度快
一次处理一行内容,当前处理行存储在临时缓冲区,用sed编辑命令处理缓冲区中的内容。处理完成后将缓冲区的内容送往屏幕,直到文件末尾。
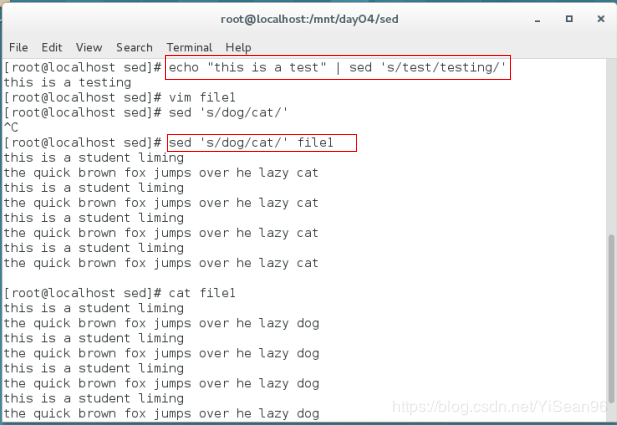
echo "this is a test" | sed 's/test/testing/' #将test转换testing
sed 's/dog/cat/' file1 #改变文档中的字符,原文档保存
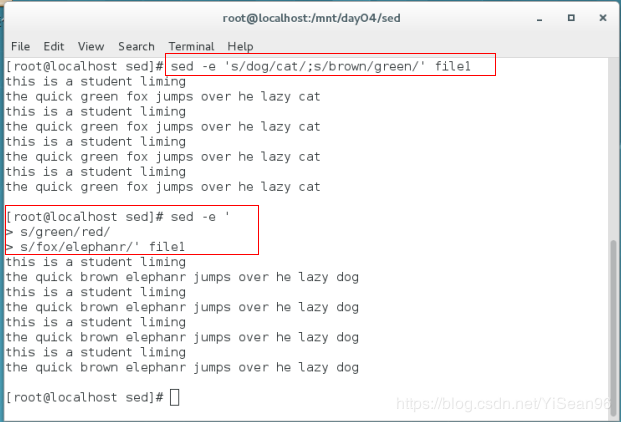
sed -e 's/dog/cat/;s/brown/green/' file1 #同时改两个
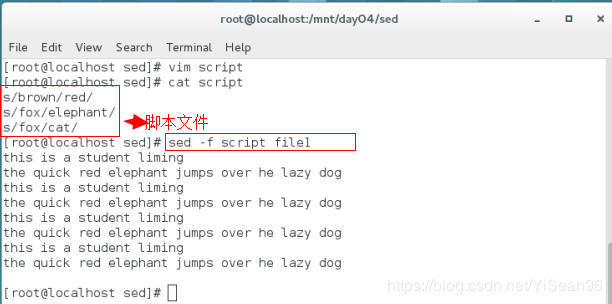
sed -f script file1 #将1命令用于2
2、标记替换
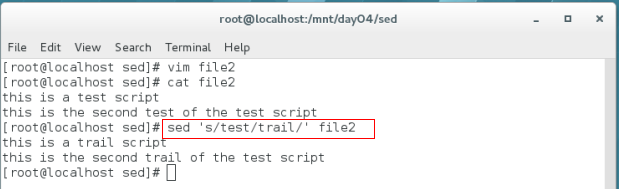
sed 's/test/trail/' file2 #默认替换每一行第一次
sed 's/test/trail/2' file2 #替换第二次出现的
sed -n 's/test/trail/p' file3 #p替换标记,只输出被命令修改过的行
sed 's/test/trail/w test' file2 #将替换行放入指定文件中
sed 's/\/bin\/bash/\/bin\/csh/' passwd
=sed 's!/bin/bash!/bin/csh/!' passwd
=sed 's#/bin/bash#/bin/csh/#' passwd
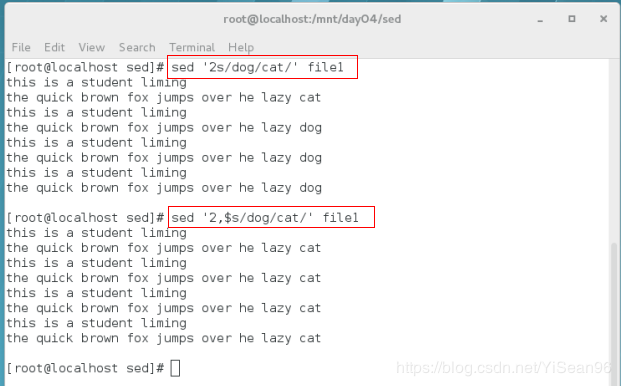
sed '2,3s/dog/cat/' file1 #只变第二三行
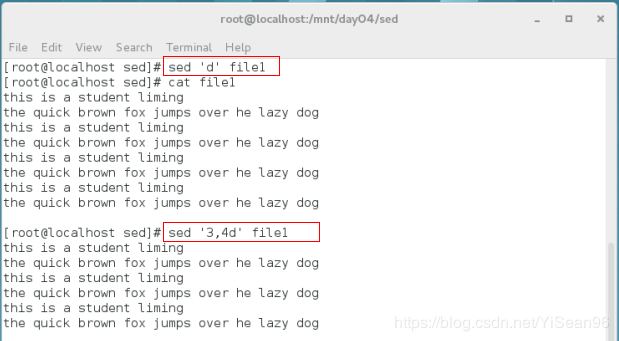
sed 'd' file1 #删除输出不改变源文件
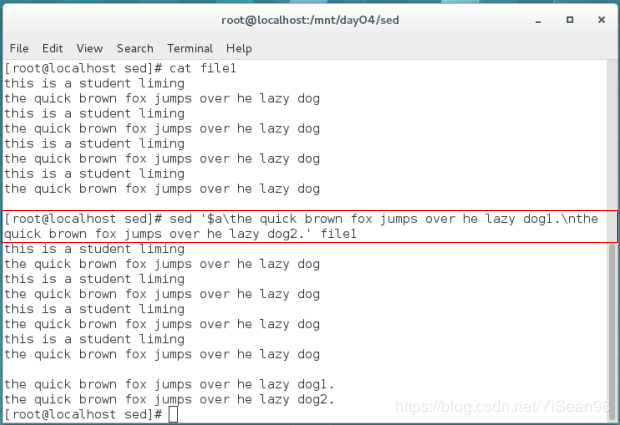
echo 'test line 2' | sed 'i\test line 1' #前加
echo 'test line 2' | sed 'a\test line 1' #后加
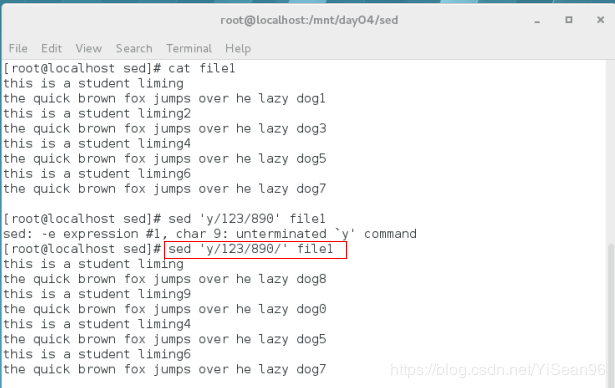
sed 'y/123/890/' file1 #处理单个字符其他不变
sed '/number 2/r date1' date2 #将date1 内容插在date2 number 2 后



三、awk
1、正则表达式扩展出来的一些元字符。grep不支持扩展正则表达式
? 匹配?之前字符0次或一次
+ 匹配前面那些字符多次 ,0次不行
() | 结合使用,(| | |)任远的一个字符存在即可
2、awk样式扫描和处理语言
读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表等。
awk程序由一个主输入循环维持(默认搭建好框架),主输入循环反复执行,直到条件被触发,
3、awk语句由模式和动作组成,模式决定动作何时触发,动作执行对输入行的处理
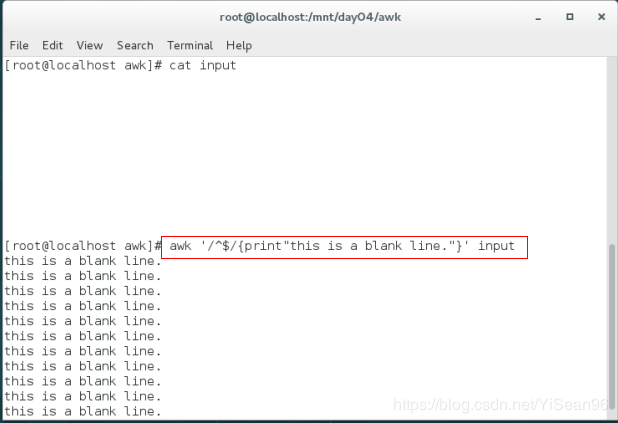
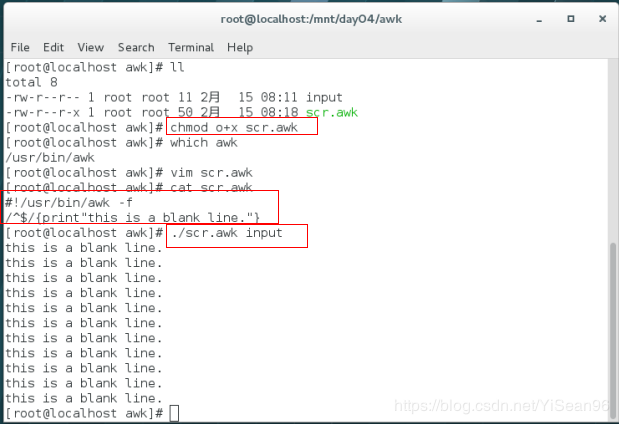
awk '/^$/{print"this is a blank line."}' input
^$ 模式 print"this is a blank line." 动作 #在$^空行时触发动作
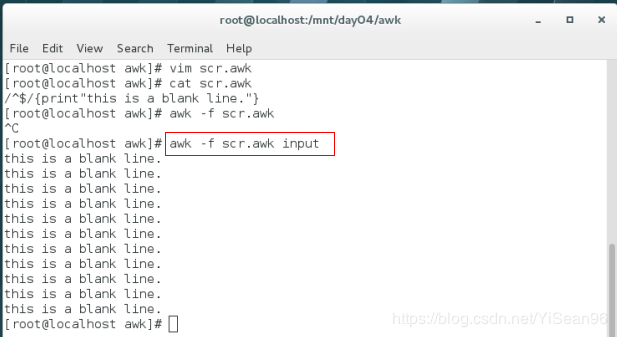
#!/usr/bin/awk -f
/^$/{print"this is a blank line."} #内容
./scr.awk input #运行
4、记录和域
awk认为输入文件为结构化,将awk输入文件的行定义为记录,行中的每个字符串定义为域,域之间用空格(可以多个)/tab(最多一个)。
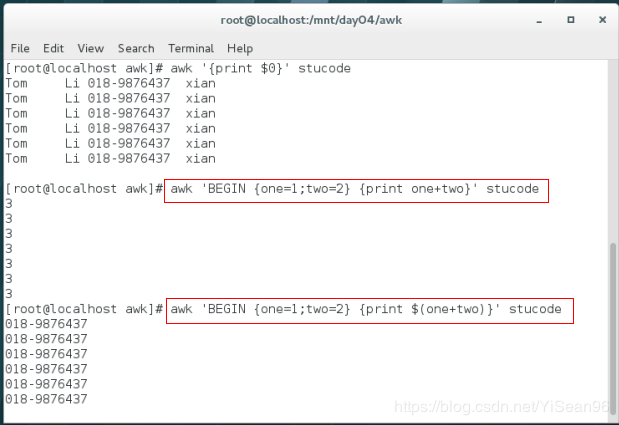
awk '{print $2,$1,$4,$3}' stucode #按域排序,默认一个空格
awk 'BEGIN {FS=","} {print $1 $3}' stucode #设定域的分隔符

5、关系和布尔运算
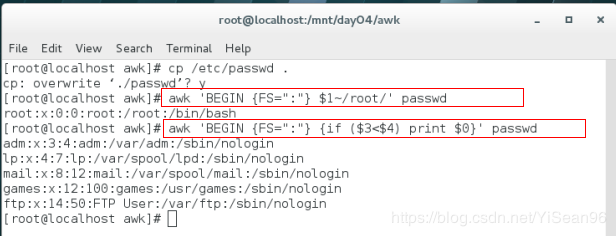
awk 'BEGIN {FS=":"} $1~/root/' passwd #~匹配正则表达式,~!不匹配
awk 'BEGIN {FS=":"} {if ($3==1 || $4==10) print $0}' passwd
#精确匹配
awk 'BEGIN {FS=":"} {if ($3<$4) print $0}' passwd #条件匹配

6、表达式
AWK表达式用来存储,操作和获取数据。一个awk表达式可由数值,字符常量,变量,操作符,函数,正则表达式自由组合而成。
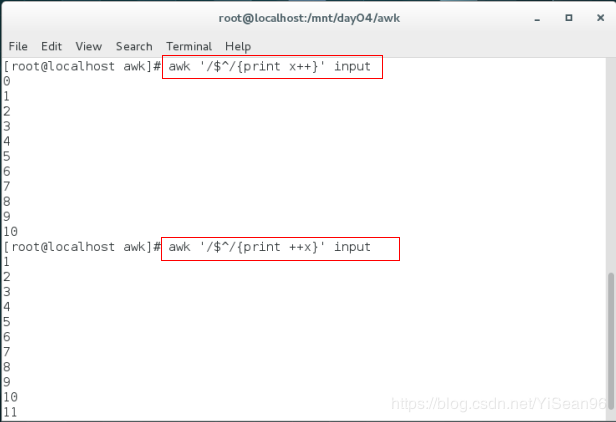
awk '/$^/{print x++}' input #统计空行值
#!/usr/bin/awk -f
BEGIN {FS=","}
{
TOTAL=$4+$5+$6
AVG=TOTAL/3
print $1,AVG
} #脚本内容
7、系统变量
改变默认值
定义系统值
NF:记录域的数量
NR:显示当前记录数
FILENAME:保存当前输入文件名
awk 'BEGIN {FS=","} {print NF,NR,$0} END {print FILENAME}' file1
8、格式化输出
产生报表,按照一定格式输出,借鉴printf
awk 'BEGIN {FS=","} {print "%-15s\t%s\n",$1,$3} file1
#对第一个域进行修饰,改字符串长度控制为15为,并且左对其,不够空格补齐
作者:YiSean96
相关文章
Gretel
2020-06-11
Jade
2021-04-16
Nancy
2020-10-25
Rayna
2020-02-28
Tallulah
2023-07-20
Fern
2023-07-20
Ophelia
2023-07-20
Nafisa
2023-07-20
Fawn
2023-07-20
Trixie
2023-07-20
Madeleine
2023-07-20
Rhea
2023-07-21
Malinda
2023-07-21
Kathy
2023-07-21
Nora
2023-07-21
Pandora
2023-07-21
Tanisha
2023-07-21
Diane
2023-07-21
Gitana
2023-07-21