用Scikit-learn进行机器学习(五):使用Scikit-learn进行KNN分析——KNN模型的提升KD-Tree的原理和KD-Tree癌症案例
文章目录KNN算法的模型提升KD-Treekd树是什么kd树的原理1.树的建立;2.最近邻域搜索(Nearest-Neighbor Lookup)3.构造方法4.案例分析4.1 树结构的建立4.2 最近领域的搜索4.2.1 查找点(2.1,3.1)4.2.2 查找点(2,4.5)5.总结KD-Tree案例癌症的数据建立模型
KNN算法的模型提升KD-Tree
k最近邻法的实现是线性扫描(以穷举搜索的方式进行距离测算,加权分类),即要计算输入实例与每一个训练实例的距离。计算并存储好以后,再查找K近邻。 当训练集很大时,计算效率非常的低下。
为了提高KNN最近邻搜索的效率,可以考虑使用特殊的结构存储训练数据,
以减小计算距离的次数。
根据KNN每次需要预测一个点时,我们都需要计算训练数据集里每个点到这个点的距离,然后选出距离最近的k个点进行投票。当数据集很大时,这个计算成本非常高,针对N个样本,D个特征的数据集,其算法复杂度为O(DN^2)。
kd树是什么
为了避免每次都重新计算一遍距离,算法会把距离信息保存在一个树状结构中,这样在计算之前从树结构查询距离信息,尽量避免重复计算。其基本原理是,如果A和B距离很远,B和C距离很近,那么A和C的距离也很远。有了这个信息,就可以在合适的时候跳过距离远的点。(A和B这两个类别是近邻类,B和C是近邻类,A和C不相近)
kd树的原理
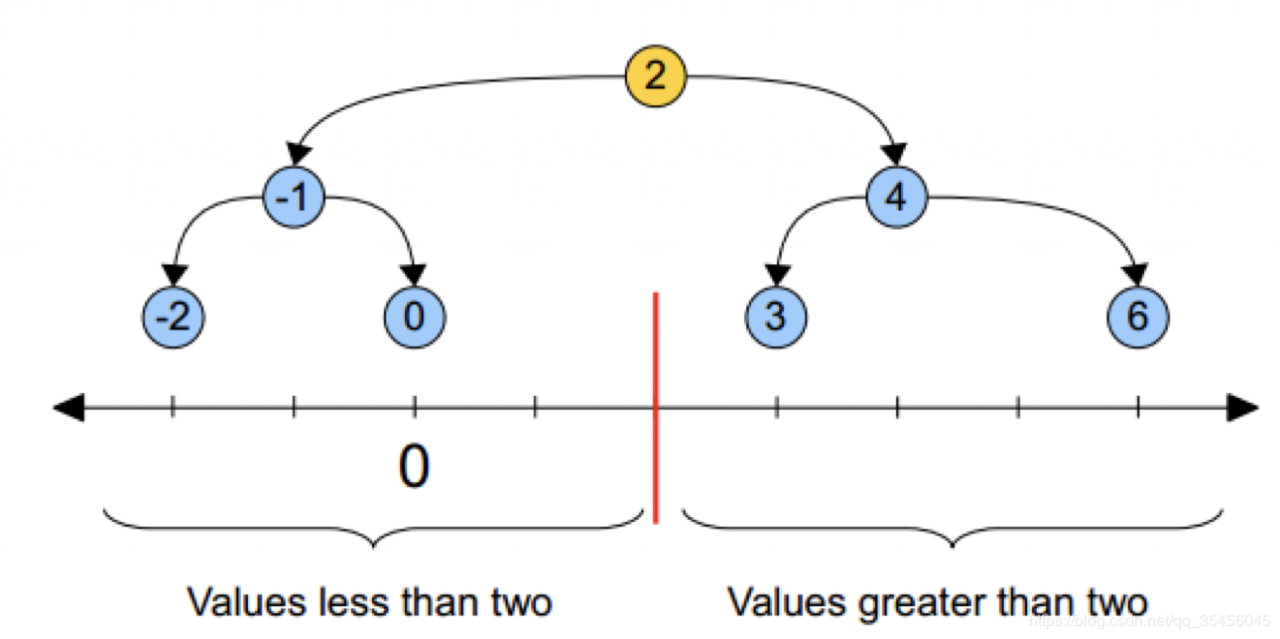 黄色的点作为根节,上面的点归左子树,下面的点归右子树,接下来再不断地划分,分割的那条线叫做分割超平面(splitting hyperplane)
在一维中是一个点,二维中是线,三维的是超平面。
黄色的点作为根节,上面的点归左子树,下面的点归右子树,接下来再不断地划分,分割的那条线叫做分割超平面(splitting hyperplane)
在一维中是一个点,二维中是线,三维的是超平面。
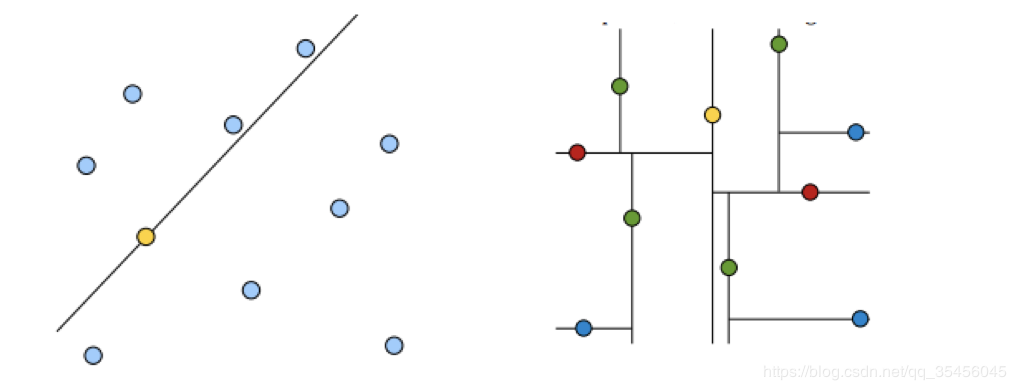 黄色点为根节点,一层子节点是红色,再下一层子节点是绿色,叶子节点为蓝色
黄色点为根节点,一层子节点是红色,再下一层子节点是绿色,叶子节点为蓝色
 1.树的建立;
2.最近邻域搜索(Nearest-Neighbor Lookup)
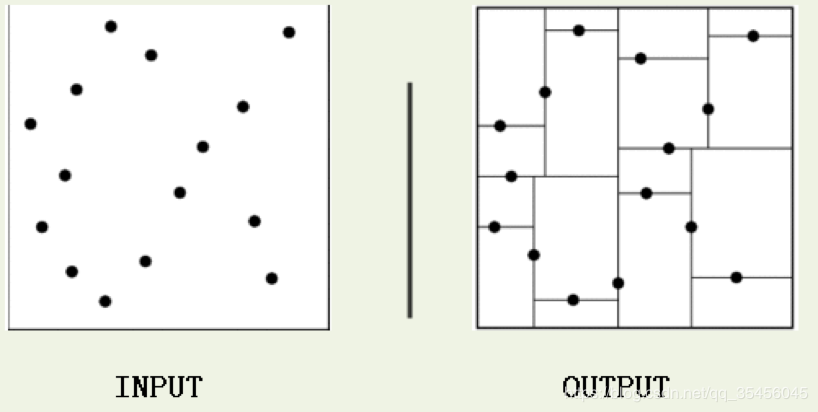
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
1.树的建立;
2.最近邻域搜索(Nearest-Neighbor Lookup)
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
 类比“二分查找”:给出一组数据:[9 1 4 7 2 5 0 3 8],要查找8。如果挨个查 找(线性扫描),那么将会把数据集都遍历一遍。而如果排一下序那数据集 就变成了:[0 1 2 3 4 5 6 7 8 9],按前一种方式我们进行了很多没有必要的 查 找,现在如果我们以5为分界点,那么数据集就被划分为了左右两个“簇” [0 1 2 3 4]和[6 7 8 9]。
因此,根本就没有必要进入第一个簇,可以直接进入第二个簇进行查找。把 二分查找中的数据点换成k维数据点,这样的划分就变成了用超平面对k维空 间的划分。空间划分就是对数据点进行分类,“挨得近”的数据点就在一个空 间 里面。
3.构造方法
(1)构造根结点,使根结点对应于K维空间中包含所有实例点的超矩形区 域;
(2)通过递归的方法,不断地对k维空间进行切分,生成子结点。在超矩形 区域上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这 个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分 为左右两个子区域(子结点);这时,实例被分到两个子区域。
(3)上述过程直到子区域内没有实例时终止(终止时的结点为叶结点)。在 此过程中,将实例保存在相应的结点上。
(4)通常,循环的选择坐标轴对空间切分,选择训练实例点在坐标轴上的中 位数为切分点,这样得到的kd树是平衡的(平衡二叉树:它是一棵空树,或 其左子树和右子树的深度之差的绝对值不超过1,且它的左子树和右子树都是 平衡二叉树)。
KD树中每个节点是一个向量,和二叉树按照数的大小划分不同的是,KD树每 层需要选定向量中的某一维,然后根据这一维按左小右大的方式划分数据。 在构建KD树时,关键需要解决2个问题:
(1)选择向量的哪一维进行划分;
(2)如何划分数据;
第一个问题简单的解决方法可以是随机选择某一维或按顺序选择,但是更好 的方法应该是在数据比较分散的那一维进行划分(分散的程度可以根据方差 来衡量)。好的划分方法可以使构建的树比较平衡,可以每次选择中位数来 进行划分,这样问题2也得到了解决。
4.案例分析
4.1 树结构的建立
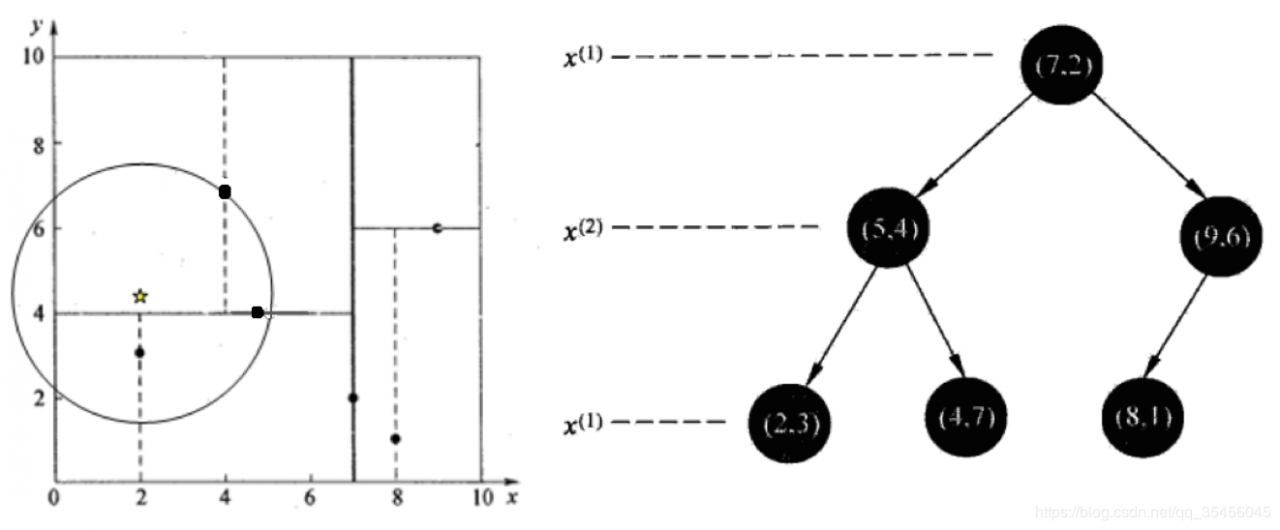
给定一个二维空间数据集:T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构造一个平 衡kd树。
类比“二分查找”:给出一组数据:[9 1 4 7 2 5 0 3 8],要查找8。如果挨个查 找(线性扫描),那么将会把数据集都遍历一遍。而如果排一下序那数据集 就变成了:[0 1 2 3 4 5 6 7 8 9],按前一种方式我们进行了很多没有必要的 查 找,现在如果我们以5为分界点,那么数据集就被划分为了左右两个“簇” [0 1 2 3 4]和[6 7 8 9]。
因此,根本就没有必要进入第一个簇,可以直接进入第二个簇进行查找。把 二分查找中的数据点换成k维数据点,这样的划分就变成了用超平面对k维空 间的划分。空间划分就是对数据点进行分类,“挨得近”的数据点就在一个空 间 里面。
3.构造方法
(1)构造根结点,使根结点对应于K维空间中包含所有实例点的超矩形区 域;
(2)通过递归的方法,不断地对k维空间进行切分,生成子结点。在超矩形 区域上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这 个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分 为左右两个子区域(子结点);这时,实例被分到两个子区域。
(3)上述过程直到子区域内没有实例时终止(终止时的结点为叶结点)。在 此过程中,将实例保存在相应的结点上。
(4)通常,循环的选择坐标轴对空间切分,选择训练实例点在坐标轴上的中 位数为切分点,这样得到的kd树是平衡的(平衡二叉树:它是一棵空树,或 其左子树和右子树的深度之差的绝对值不超过1,且它的左子树和右子树都是 平衡二叉树)。
KD树中每个节点是一个向量,和二叉树按照数的大小划分不同的是,KD树每 层需要选定向量中的某一维,然后根据这一维按左小右大的方式划分数据。 在构建KD树时,关键需要解决2个问题:
(1)选择向量的哪一维进行划分;
(2)如何划分数据;
第一个问题简单的解决方法可以是随机选择某一维或按顺序选择,但是更好 的方法应该是在数据比较分散的那一维进行划分(分散的程度可以根据方差 来衡量)。好的划分方法可以使构建的树比较平衡,可以每次选择中位数来 进行划分,这样问题2也得到了解决。
4.案例分析
4.1 树结构的建立
给定一个二维空间数据集:T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构造一个平 衡kd树。
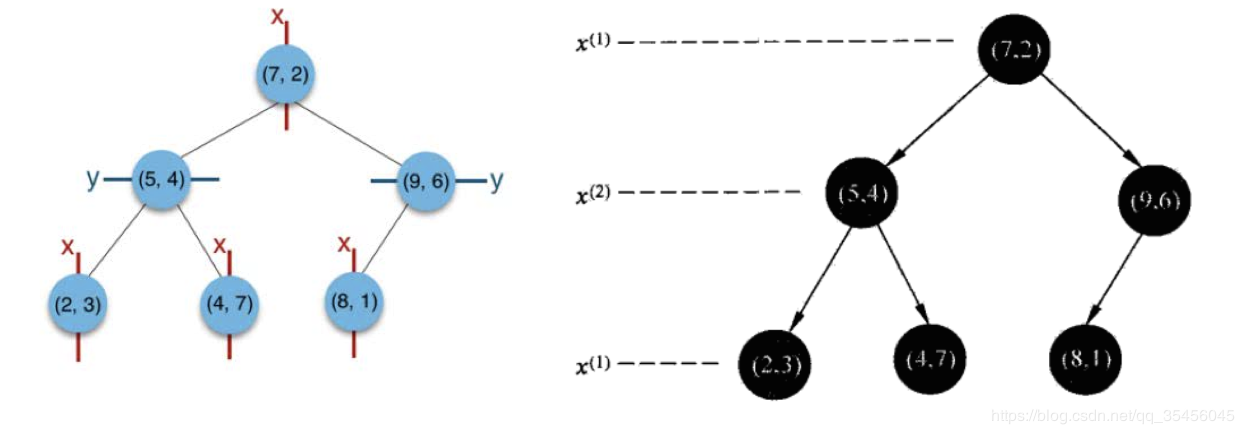 (1)思路引导:
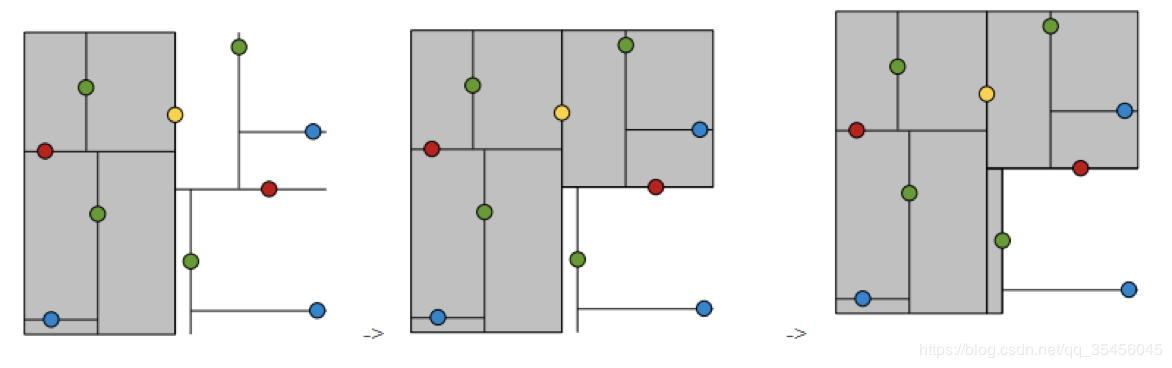
根结点对应包含数据集T的矩形,选择x(1)轴,6个数据点的x(1)坐标中位数 是 6,这里选最接近的(7,2)点,以平面x(1)=7将空间分为左、右两个子矩形 (子 结点);接着左矩形以x(2)=4分为两个子矩形(左矩形中{(2,3),(5,4), (4,7)}点 的x(2)坐标中位数正好为4),右矩形以x(2)=6分为两个子矩形,如此递归, 最后得到如下图所示的特征空间划分和kd树。
(1)思路引导:
根结点对应包含数据集T的矩形,选择x(1)轴,6个数据点的x(1)坐标中位数 是 6,这里选最接近的(7,2)点,以平面x(1)=7将空间分为左、右两个子矩形 (子 结点);接着左矩形以x(2)=4分为两个子矩形(左矩形中{(2,3),(5,4), (4,7)}点 的x(2)坐标中位数正好为4),右矩形以x(2)=6分为两个子矩形,如此递归, 最后得到如下图所示的特征空间划分和kd树。
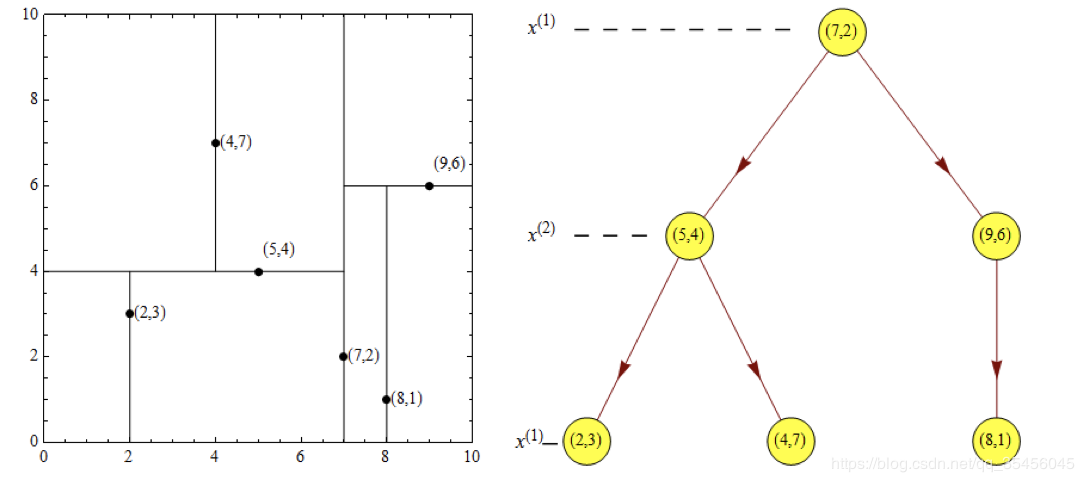 4.2 最近领域的搜索
假设标记为星星的点是 test point, 绿色的点是找到的近似点,在回溯过程 中,需要用到一个队列,存储需要回溯的点,在判断其他子节点空间中是否 有可能有距离查询点更近的数据点时,做法是以查询点为圆心,以当前的最 近距离为半径画圆,这个圆称为候选超球(candidate hypersphere),如果 圆与回溯点的轴相交,则需要将轴另一边的节点都放到回溯队列里面来。
4.2 最近领域的搜索
假设标记为星星的点是 test point, 绿色的点是找到的近似点,在回溯过程 中,需要用到一个队列,存储需要回溯的点,在判断其他子节点空间中是否 有可能有距离查询点更近的数据点时,做法是以查询点为圆心,以当前的最 近距离为半径画圆,这个圆称为候选超球(candidate hypersphere),如果 圆与回溯点的轴相交,则需要将轴另一边的节点都放到回溯队列里面来。
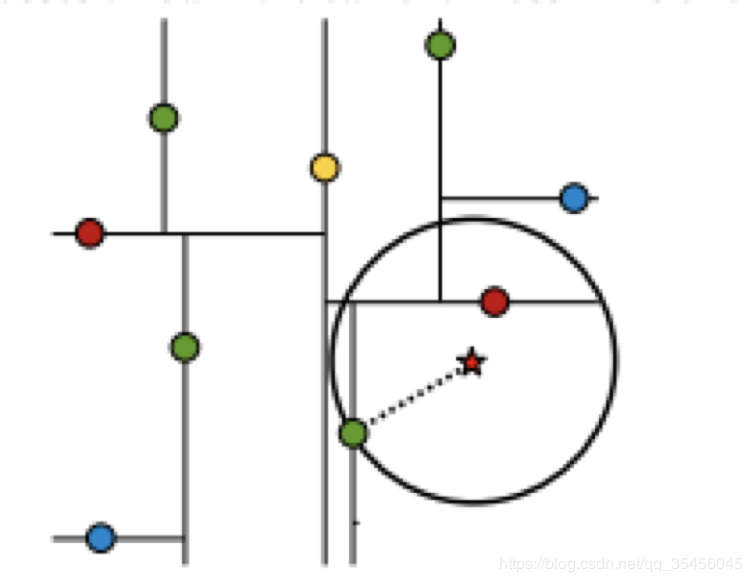 样本集{(2,3),(5,4), (9,6), (4,7), (8,1), (7,2)}
4.2.1 查找点(2.1,3.1)
样本集{(2,3),(5,4), (9,6), (4,7), (8,1), (7,2)}
4.2.1 查找点(2.1,3.1)
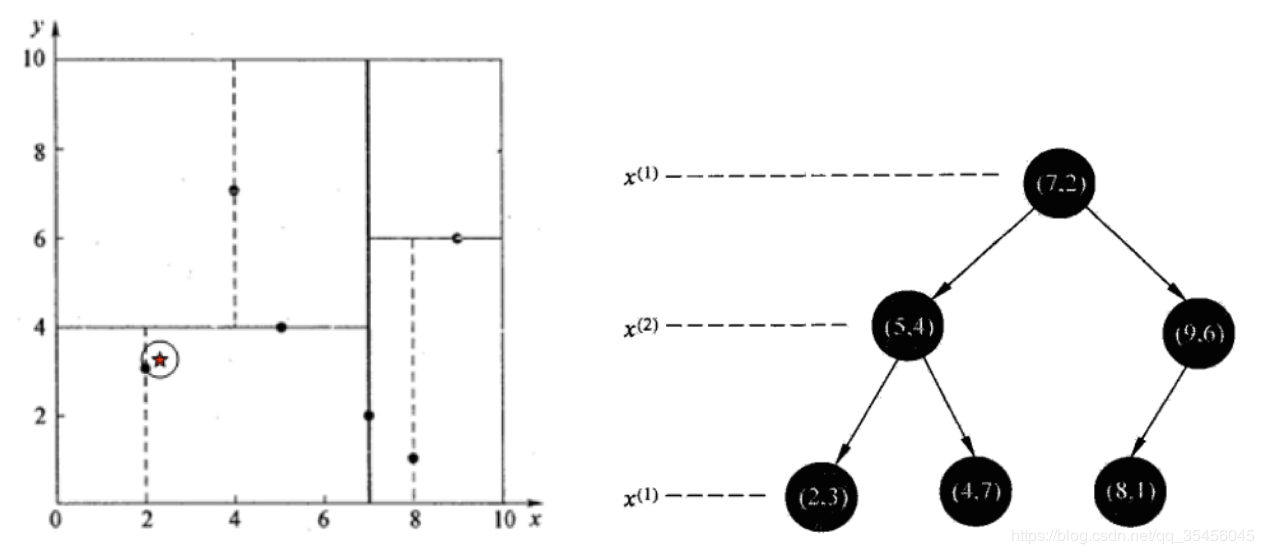 在(7,2)点测试到达(5,4),在(5,4)点测试到达(2,3),然后search_path中的结点 为,从search_path中取出(2,3)作为当前最佳结点nearest, dist为0.141; 然后回溯至(5,4),以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆,并不和 超平面y=4相交,如上图,所以不必跳到结点(5,4)的右子空间去搜索,因为右 子空间中不可能有更近样本点了。
于是再回溯至(7,2),同理,以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆 并不和超平面x=7相交,所以也不用跳到结点(7,2)的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2.1,3.1)的最 近邻点,最近距离为0.141。
4.2.2 查找点(2,4.5)
在(7,2)点测试到达(5,4),在(5,4)点测试到达(2,3),然后search_path中的结点 为,从search_path中取出(2,3)作为当前最佳结点nearest, dist为0.141; 然后回溯至(5,4),以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆,并不和 超平面y=4相交,如上图,所以不必跳到结点(5,4)的右子空间去搜索,因为右 子空间中不可能有更近样本点了。
于是再回溯至(7,2),同理,以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆 并不和超平面x=7相交,所以也不用跳到结点(7,2)的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2.1,3.1)的最 近邻点,最近距离为0.141。
4.2.2 查找点(2,4.5)
 5.总结
首先通过二叉树搜索(比较待查询节点和分裂节点的分裂维的值,小于等于 就进入左子树分支,大于就进入右子树分支直到叶子结点),顺着“搜索路 径” 很快能找到最近邻的近似点,也就是与待查询点处于同一个子空间的叶子结 点;
然后再回溯搜索路径,并判断搜索路径上的结点的其他子结点空间中是否可 能有距离查询点更近的数据点,如果有可能,则需要跳到其他子结点空间中 去搜索(将其他子结点加入到搜索路径)。 重复这个过程直到搜索路径为空。
KD-Tree案例
癌症的数据
5.总结
首先通过二叉树搜索(比较待查询节点和分裂节点的分裂维的值,小于等于 就进入左子树分支,大于就进入右子树分支直到叶子结点),顺着“搜索路 径” 很快能找到最近邻的近似点,也就是与待查询点处于同一个子空间的叶子结 点;
然后再回溯搜索路径,并判断搜索路径上的结点的其他子结点空间中是否可 能有距离查询点更近的数据点,如果有可能,则需要跳到其他子结点空间中 去搜索(将其他子结点加入到搜索路径)。 重复这个过程直到搜索路径为空。
KD-Tree案例
癌症的数据
 建立模型
建立模型
 作者:汪雯琦
作者:汪雯琦
黄色的点作为根节,上面的点归左子树,下面的点归右子树,接下来再不断地划分,分割的那条线叫做分割超平面(splitting hyperplane)
在一维中是一个点,二维中是线,三维的是超平面。
黄色点为根节点,一层子节点是红色,再下一层子节点是绿色,叶子节点为蓝色
1.树的建立;
2.最近邻域搜索(Nearest-Neighbor Lookup)
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
类比“二分查找”:给出一组数据:[9 1 4 7 2 5 0 3 8],要查找8。如果挨个查 找(线性扫描),那么将会把数据集都遍历一遍。而如果排一下序那数据集 就变成了:[0 1 2 3 4 5 6 7 8 9],按前一种方式我们进行了很多没有必要的 查 找,现在如果我们以5为分界点,那么数据集就被划分为了左右两个“簇” [0 1 2 3 4]和[6 7 8 9]。
因此,根本就没有必要进入第一个簇,可以直接进入第二个簇进行查找。把 二分查找中的数据点换成k维数据点,这样的划分就变成了用超平面对k维空 间的划分。空间划分就是对数据点进行分类,“挨得近”的数据点就在一个空 间 里面。
3.构造方法
(1)构造根结点,使根结点对应于K维空间中包含所有实例点的超矩形区 域;
(2)通过递归的方法,不断地对k维空间进行切分,生成子结点。在超矩形 区域上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这 个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分 为左右两个子区域(子结点);这时,实例被分到两个子区域。
(3)上述过程直到子区域内没有实例时终止(终止时的结点为叶结点)。在 此过程中,将实例保存在相应的结点上。
(4)通常,循环的选择坐标轴对空间切分,选择训练实例点在坐标轴上的中 位数为切分点,这样得到的kd树是平衡的(平衡二叉树:它是一棵空树,或 其左子树和右子树的深度之差的绝对值不超过1,且它的左子树和右子树都是 平衡二叉树)。
KD树中每个节点是一个向量,和二叉树按照数的大小划分不同的是,KD树每 层需要选定向量中的某一维,然后根据这一维按左小右大的方式划分数据。 在构建KD树时,关键需要解决2个问题:
(1)选择向量的哪一维进行划分;
(2)如何划分数据;
第一个问题简单的解决方法可以是随机选择某一维或按顺序选择,但是更好 的方法应该是在数据比较分散的那一维进行划分(分散的程度可以根据方差 来衡量)。好的划分方法可以使构建的树比较平衡,可以每次选择中位数来 进行划分,这样问题2也得到了解决。
4.案例分析
4.1 树结构的建立
给定一个二维空间数据集:T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构造一个平 衡kd树。
(1)思路引导:
根结点对应包含数据集T的矩形,选择x(1)轴,6个数据点的x(1)坐标中位数 是 6,这里选最接近的(7,2)点,以平面x(1)=7将空间分为左、右两个子矩形 (子 结点);接着左矩形以x(2)=4分为两个子矩形(左矩形中{(2,3),(5,4), (4,7)}点 的x(2)坐标中位数正好为4),右矩形以x(2)=6分为两个子矩形,如此递归, 最后得到如下图所示的特征空间划分和kd树。
4.2 最近领域的搜索
假设标记为星星的点是 test point, 绿色的点是找到的近似点,在回溯过程 中,需要用到一个队列,存储需要回溯的点,在判断其他子节点空间中是否 有可能有距离查询点更近的数据点时,做法是以查询点为圆心,以当前的最 近距离为半径画圆,这个圆称为候选超球(candidate hypersphere),如果 圆与回溯点的轴相交,则需要将轴另一边的节点都放到回溯队列里面来。
样本集{(2,3),(5,4), (9,6), (4,7), (8,1), (7,2)}
4.2.1 查找点(2.1,3.1)
在(7,2)点测试到达(5,4),在(5,4)点测试到达(2,3),然后search_path中的结点 为,从search_path中取出(2,3)作为当前最佳结点nearest, dist为0.141; 然后回溯至(5,4),以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆,并不和 超平面y=4相交,如上图,所以不必跳到结点(5,4)的右子空间去搜索,因为右 子空间中不可能有更近样本点了。
于是再回溯至(7,2),同理,以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆 并不和超平面x=7相交,所以也不用跳到结点(7,2)的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2.1,3.1)的最 近邻点,最近距离为0.141。
4.2.2 查找点(2,4.5)
5.总结
首先通过二叉树搜索(比较待查询节点和分裂节点的分裂维的值,小于等于 就进入左子树分支,大于就进入右子树分支直到叶子结点),顺着“搜索路 径” 很快能找到最近邻的近似点,也就是与待查询点处于同一个子空间的叶子结 点;
然后再回溯搜索路径,并判断搜索路径上的结点的其他子结点空间中是否可 能有距离查询点更近的数据点,如果有可能,则需要跳到其他子结点空间中 去搜索(将其他子结点加入到搜索路径)。 重复这个过程直到搜索路径为空。
KD-Tree案例
癌症的数据
#读取数据
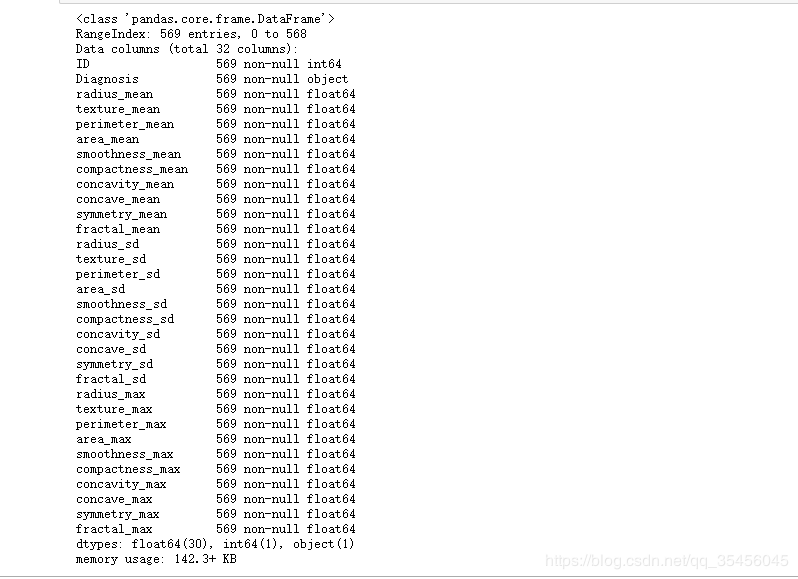
cancer = pd.read_csv('cancer.csv',sep='\t')
cancer.info()
#抽取数据
feature = cancer.select_dtypes(include=['float64'])
labels = cancer.select_dtypes(include=['object']).Diagnosis
#观察
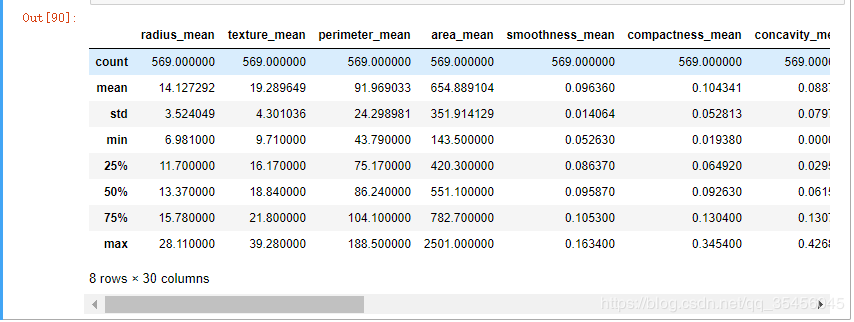
feature.describe()
plt.figure(figsize=(18,6))
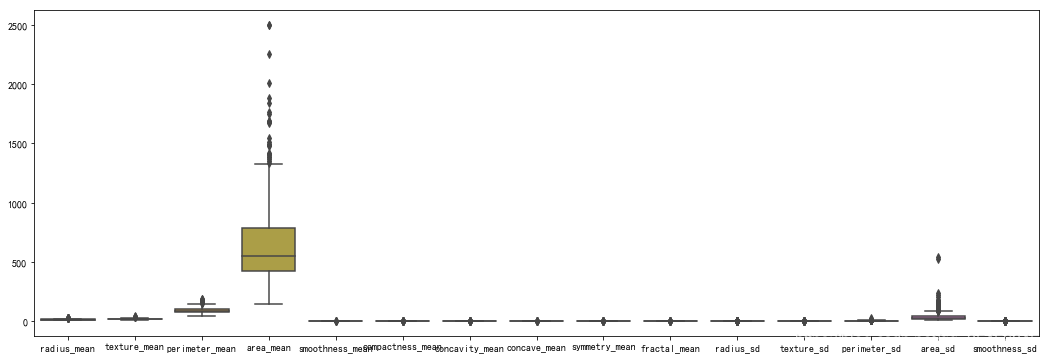
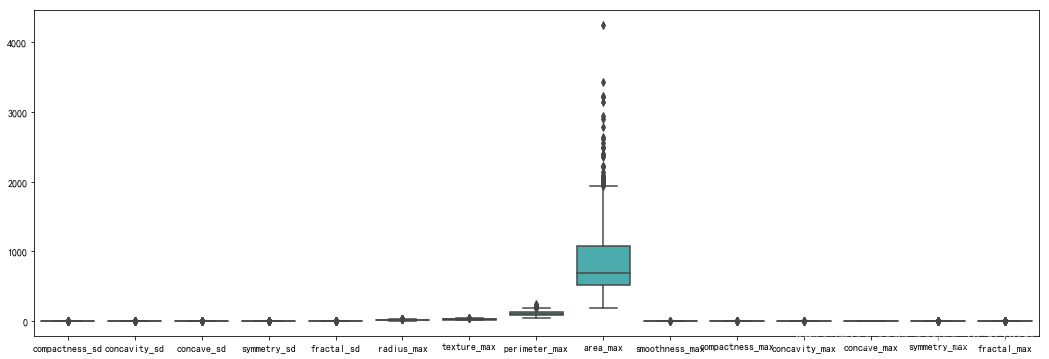
sns.boxplot(data=feature.iloc[:,:15])
plt.figure(figsize=(18,6))
sns.boxplot(data=feature.iloc[:,15:])
#30个特征,30*30
sns.pairplot(data=feature)
建立模型
from sklearn.preprocessing import MinMaxScaler,StandardScaler
#1.先示例化
#feature_range = 压缩范围
MinMax = MinMaxScaler()
#训练数据 分别提取每列中的最大值和最小
MinMax.fit(feature)
#转换数据 返回
MinMax.transform(feature)
#换一种写法
#直接训练加转换
mm_fea = MinMax.fit_transform(feature)
STD = StandardScaler()
std_fea = STD.fit_transform(feature)
#数据切分
X_train,X_test,y_train,y_test = train_test_split(std_fea,labels,test_size=69)
kdtree = KNeighborsClassifier(algorithm='kd_tree').fit(X_train,y_train)
#评估
kdtree.score(X_train,y_train),kdtree.score(X_test,y_test)
相关文章
Eilene
2020-01-19
Quirita
2021-04-07
Netany
2020-02-06
Iris
2021-08-03
Ula
2023-05-13
Jacinda
2023-05-13
Winona
2023-05-13
Fawn
2023-05-13
Echo
2023-05-13
Maha
2023-05-13
Kande
2023-05-15
Tani
2023-05-17
Viridis
2023-05-17
Pandora
2023-07-07
Tallulah
2023-07-17
Janna
2023-07-20
Ophelia
2023-07-20