用PCA、LDA、LR做人脸识别代码实现
'''机器学习-面部识别示例'''
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.preprocessing import StandardScaler
from time import time
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.metrics import classification_report, confusion_matrix,accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
# 第一步:The Data 准备数据
lfw_people = fetch_lfw_people(min_faces_per_person=9, resize=0.4)
n_samples, h, w = lfw_people.images.shape
n_samples, h, w
X = lfw_people.data
y = lfw_people.target
n_features = X.shape[1]
'''分类准确率baseline 0.45 '''
# 第二步:Some data exploration 数据探索
target_names = lfw_people.target_names
n_classes = target_names.shape[0]
print ("Total dataset size:")
print ("n_samples: %d" % n_samples)
print ("n_features: %d" % n_features)
print ("n_classes: %d" % n_classes )
#第三步:特征学习,创建面部识别模型的机器学习pipeline
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.25, random_state=1)
# instantiate the PCA module
pca = PCA(n_components=30, whiten=True)
preprocessing = Pipeline([('scale', StandardScaler()), ('pca', pca)])
preprocessing.fit(X_train)
extracted_pca = preprocessing.steps[1][1]
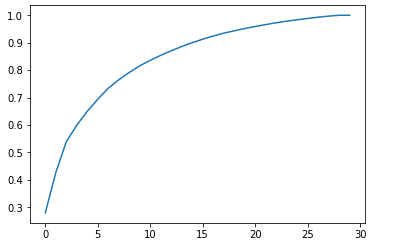
# Scree Plot陡坡图
plt.plot(np.cumsum(extracted_pca.explained_variance_ratio_))
#第四步,创建网格搜索,寻找最优模型和参数
#创建函数打印最优准确率、最优参数、训练和预测时间
def get_best_model_and_accuracy(model, params, X, y):
grid = GridSearchCV(model, params, error_score=0.)
grid.fit(X, y)
print ("Best Accuracy: {}".format(grid.best_score_))
print ("Best Parameters: {}".format(grid.best_params_))
print( "Average Time to Fit (s):{}".format(round(grid.cv_results_['mean_fit_time'].mean(), 3)))
print ("Average Time to Score (s):{}".format(round(grid.cv_results_['mean_score_time'].mean(), 3)))
# Create a larger pipeline to gridsearch
face_params = {'logistic__C':[1e-2, 1e-1, 1e0, 1e1, 1e2],
'preprocessing__pca__n_components':[5 ,10, 15, 20, 25,26],
'preprocessing__pca__whiten':[True, False],
'preprocessing__lda__n_components':range(1, 3)
}
pca = PCA()
lda = LinearDiscriminantAnalysis()
preprocessing = Pipeline([('scale', StandardScaler()), ('pca', pca),('lda', lda)])
logreg = LogisticRegression()
face_pipeline = Pipeline(steps=[('preprocessing', preprocessing),('logistic', logreg)])
get_best_model_and_accuracy(face_pipeline, face_params, X, y)
'''output:
Best Accuracy: 0.675
Best Parameters: {'logistic__C': 10.0, 'preprocessing__lda__n_components': 2, 'preprocessing__pca__n_components': 20, 'preprocessing__pca__whiten': True}
Average Time to Fit (s):0.008
Average Time to Score (s):0.001
'''
#confusion matrix
0.5 Accuracy score for best estimator
precision recall f1-score support
George HW Bush 0.50 0.50 0.50 2
Michael Schumacher 0.43 1.00 0.60 3
Paul ONeill 1.00 0.20 0.33 5
micro avg 0.50 0.50 0.50 10
macro avg 0.64 0.57 0.48 10
weighted avg 0.73 0.50 0.45 10
None
0.4 seconds to grid search and predict the test set


作者:夜已.入深