学成在线day11,全文检索 Elasticearch- 搜索管理的11个方法,部署ES集群的步骤,学成_搜索服务,win系统的Logstash的安装测试,课程搜索
测试类依赖的jar
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.index.query.*;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import javax.naming.directory.SearchResult;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
@SpringBootTest
@RunWith(SpringRunner.class)
public class TestSearch {
@Autowired
RestHighLevelClient client;
@Autowired
RestClient restClient;
1.搜索全部记录 matchAllQuery 查询所有索引库的文档。
@Test
//搜索全部记录
public void testSearchAll() throws IOException, ParseException {
//新建一个搜索请求的对象,指向ES中xc_course这张表
SearchRequest searchRequest = new SearchRequest("xc_course");
//指定表的类型,就是那个无意义的type,字段
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//指定搜索源的搜索方式
//matchAllQuery搜索全部
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求,搜索时通过io流去操作,所以需要抛IO异常
//得到结果
SearchResponse searchResponse = client.search(searchRequest);
//把结果解析
SearchHits hits = searchResponse.getHits();
//取匹配到的结果总记录数
long totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//先创建日期格式化对象
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//遍历高度匹配的文档
for (SearchHit hit : searchHits) {
//文档的主键
String id = hit.getId();
//源文档内容,源中的数据,封装为map返回
Map sourceAsMap = hit.getSourceAsMap();
//取name这个列的数据,里面的数据你知道是String,所以Object可以强转
String name = (String)sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期,(String)sourceAsMap.get("timestamp")是取得一个时间字符串
// ,需要提前准备好的日期格式化对象,并且抛日期的异常
Date timestamp = simpleDateFormat.parse((String) sourceAsMap.get("timestamp"));
System.err.println(name);
System.err.println(studymodel);
System.err.println(description);
}
}//搜索全部记录
2.分页查询 搜索源设置分页参数
ES支持分页查询,传入两个参数:from和size。
form:表示起始文档的下标,从0开始。
size:查询的文档数量。
@Test
//2.分页查询
public void testSearchPage() throws IOException, ParseException {
//新建一个搜索请求的对象,指向ES中xc_course这张表
SearchRequest searchRequest = new SearchRequest("xc_course");
//指定表的类型,就是那个无意义的type,字段
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//设置分页参数
//页码
int page = 1;
//每页记录数
int size = 1;
//计算出记录起始下标
int from = (page-1)*size;
//起始记录下标,从0开始
searchSourceBuilder.from(from);
//每页显示的记录数
searchSourceBuilder.size(size);
//指定搜索源的搜索方式
//matchAllQuery搜索全部
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求,搜索时通过io流去操作,所以需要抛IO异常
//得到结果
SearchResponse searchResponse = client.search(searchRequest);
//把结果解析
SearchHits hits = searchResponse.getHits();
//取匹配到的结果总记录数
long totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//先创建日期格式化对象
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//遍历高度匹配的文档
for (SearchHit hit : searchHits) {
//文档的主键
String id = hit.getId();
//源文档内容,源中的数据,封装为map返回
Map sourceAsMap = hit.getSourceAsMap();
//取name这个列的数据,里面的数据你知道是String,所以Object可以强转
String name = (String)sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期,(String)sourceAsMap.get("timestamp")是取得一个时间字符串
// ,需要提前准备好的日期格式化对象,并且抛日期的异常
Date timestamp = simpleDateFormat.parse((String) sourceAsMap.get("timestamp"));
System.err.println(name);
System.err.println(studymodel);
System.err.println(description);
System.err.println("搜索到条数:"+totalHits);
}
}//分页搜索结束
3.TermQuery,精确查询某个列(常用)
@Test
public void testTermQuery() throws IOException, ParseException {
//新建一个搜索请求的对象,指向ES中xc_course这张表
SearchRequest searchRequest = new SearchRequest("xc_course");
//指定表的类型,就是那个无意义的type,字段
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//设置分页参数
//页码
int page = 1;
//每页记录数
int size = 1;
//计算出记录起始下标
int from = (page-1)*size;
//起始记录下标,从0开始
searchSourceBuilder.from(from);
//每页显示的记录数
searchSourceBuilder.size(size);
//指定搜索源的搜索方式
//搜索方式
//******termQuery,精确查询某个列,内容为spring的字符*******
searchSourceBuilder.query(QueryBuilders.termQuery("name","spring"));
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求,搜索时通过io流去操作,所以需要抛IO异常
//得到结果
SearchResponse searchResponse = client.search(searchRequest);
//把结果解析
SearchHits hits = searchResponse.getHits();
//取匹配到的结果总记录数
long totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//先创建日期格式化对象
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//遍历高度匹配的文档
for (SearchHit hit : searchHits) {
//文档的主键
String id = hit.getId();
//源文档内容,源中的数据,封装为map返回
Map sourceAsMap = hit.getSourceAsMap();
//取name这个列的数据,里面的数据你知道是String,所以Object可以强转
String name = (String)sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期,(String)sourceAsMap.get("timestamp")是取得一个时间字符串
// ,需要提前准备好的日期格式化对象,并且抛日期的异常
Date timestamp = simpleDateFormat.parse((String) sourceAsMap.get("timestamp"));
System.err.println(name);
System.err.println(studymodel);
System.err.println(description);
System.err.println("搜索到条数:"+totalHits);
}
}
4.TermsQuery 根据id精确匹配(常用)
@Test
public void testTermQueryByIds() throws IOException, ParseException {
//新建一个搜索请求的对象,指向ES中xc_course这张表
SearchRequest searchRequest = new SearchRequest("xc_course");
//指定表的类型,就是那个无意义的type,字段
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//设置分页参数
//页码
int page = 1;
//每页记录数
int size = 5;
//计算出记录起始下标
int from = (page-1)*size;
//起始记录下标,从0开始
searchSourceBuilder.from(from);
//每页显示的记录数
searchSourceBuilder.size(size);
//指定搜索源的搜索方式
//搜索方式
//根据id查询
//*******定义id数组*******
String[] ids = new String[]{"1","2"};
//通过 _id 这个列,查询数组内的所有id,返回符合的数据
//*******termsQuery,注意这个方法,比列精确查询多个s。要注意看*******
searchSourceBuilder.query(QueryBuilders.termsQuery("_id",ids));
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求,搜索时通过io流去操作,所以需要抛IO异常
//得到结果
SearchResponse searchResponse = client.search(searchRequest);
//把结果解析
SearchHits hits = searchResponse.getHits();
//取匹配到的结果总记录数
long totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//先创建日期格式化对象
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//遍历高度匹配的文档
for (SearchHit hit : searchHits) {
//文档的主键
String id = hit.getId();
//源文档内容,源中的数据,封装为map返回
Map sourceAsMap = hit.getSourceAsMap();
//取name这个列的数据,里面的数据你知道是String,所以Object可以强转
String name = (String)sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期,(String)sourceAsMap.get("timestamp")是取得一个时间字符串
// ,需要提前准备好的日期格式化对象,并且抛日期的异常
Date timestamp = simpleDateFormat.parse((String) sourceAsMap.get("timestamp"));
System.err.println(name);
System.err.println(studymodel);
System.err.println(description);
System.err.println("搜索到条数:"+totalHits);
}
}
5.MatchQuery,把搜索的词,先划分词,之后再去索引找,
or:划分后的词,只要有一个就算匹配(用得多一些)
and:划分后的词,需要全部匹配到
@Test
public void testMatchQueryOR() throws IOException, ParseException {
//搜索请求对象
SearchRequest searchRequest = new SearchRequest("xc_course");
//指定类型
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//搜索方式
//MatchQuery, .operator(Operator.OR)划分后的词,只要索引中,有一个就成
searchSourceBuilder.query(QueryBuilders.matchQuery("description","spring开发框架")
.operator(Operator.OR));
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
//理解为指定要显示哪几个列
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求
SearchResponse searchResponse = client.search(searchRequest);
//搜索结果
SearchHits hits = searchResponse.getHits();
//匹配到的总记录数
long totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//日期格式化对象
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for(SearchHit hit:searchHits){
//文档的主键
String id = hit.getId();
//源文档内容
Map sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期
Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp"));
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
6.MatchQuery,minimum_should_match 匹配词的占比的搜索模式
设置"minimum_should_match": "80%"表示,三个词在文档的匹配占比为80%,即3*0.8=2.4,向上取整得2,表示至少有两个词在文档中要匹配成功。
@Test
public void testMatchQuery() throws IOException, ParseException {
//搜索请求对象
SearchRequest searchRequest = new SearchRequest("xc_course");
//指定类型
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//搜索方式*******
//MatchQuery,.minimumShouldMatch("80%")搜索划分后的词,假如有3个,每条数据,就必须要有2个才能匹配
searchSourceBuilder.query(QueryBuilders.matchQuery("description","spring开发框架")
.minimumShouldMatch("80%"));
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求
SearchResponse searchResponse = client.search(searchRequest);
//搜索结果
SearchHits hits = searchResponse.getHits();
//匹配到的总记录数
long totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//日期格式化对象
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for(SearchHit hit:searchHits){
//文档的主键
String id = hit.getId();
//源文档内容
Map sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期
Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp"));
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
7.multiMatchQuery(常用):
1.搜索的分词,匹配多个列。
2.提升boost,匹配多个字段时可以提升字段的 boost(权重)来提高得分
3.“列名^10” 表示该列的权重提升10倍
@Test
public void testMultiMatchQuery() throws IOException, ParseException {
//搜索请求对象
SearchRequest searchRequest = new SearchRequest("xc_course");
//指定类型
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//搜索方式*******
//MultiMatchQuery,multiMatchQuery(参数1:搜索的分词,参数2:列名1,列名2)
//multiMatchQuery(常用):
// 1.搜索的分词,匹配多个列。
// 2.提升boost,匹配多个字段时可以提升字段的 boost(权重)来提高得分
// 3.“列名^10” 表示该列的权重提升10倍
searchSourceBuilder.query(QueryBuilders.multiMatchQuery("spring css","name","description")
//.minimumShouldMatch("50%"),至少要找到搜索分词的50%才行
.minimumShouldMatch("50%")
//.field("name",10));name这个列的得分权重提高10倍
.field("name",10));
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求
SearchResponse searchResponse = client.search(searchRequest);
//搜索结果
SearchHits hits = searchResponse.getHits();
//匹配到的总记录数
long totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//日期格式化对象
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for(SearchHit hit:searchHits){
//文档的主键
String id = hit.getId();
//源文档内容
Map sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期
Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp"));
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
8.BoolQuery 布尔查询(常用):
布尔查询对应于Lucene的BooleanQuery查询,实现将多个查询组合起来。
三个参数:
must:表示必须,多个查询条件必须都满足。(通常使用must)
should:表示或者,多个查询条件只要有一个满足即可。
must_not:表示非。
@Test
public void testBoolQuery() throws IOException, ParseException {
//搜索请求对象
SearchRequest searchRequest = new SearchRequest("xc_course");
//指定类型
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//搜索方式,用布尔查询,简单来说,就是把多个查询方式组合一起使用*******
//1.自定义的查询对象,MultiMatchQuery
MultiMatchQueryBuilder field = QueryBuilders.multiMatchQuery("spring css", "name", "description")
//.minimumShouldMatch("50%"),至少要找到搜索分词的50%才行
.minimumShouldMatch("50%")
//.field("name",10));name这个列的得分权重提高10倍*******
.field("name", 10);
//2.精确列查询对象,termQuery
TermQueryBuilder termQuery = QueryBuilders.termQuery("studymodel", "201001");
//3.把2个查询对象组装在一个布尔查询的对象中
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//往里面扔查询对象
// must:表示必须,多个查询条件必须都满足。(通常使用must)
//should:表示或者,多个查询条件只要有一个满足即可。
//must_not:表示非。
boolQueryBuilder.must(field);
boolQueryBuilder.must(termQuery);
//4.通过布尔查询对象,获取值
searchSourceBuilder.query(boolQueryBuilder);
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求
SearchResponse searchResponse = client.search(searchRequest);
//搜索结果
SearchHits hits = searchResponse.getHits();
//匹配到的总记录数
long totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//日期格式化对象
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for(SearchHit hit:searchHits){
//文档的主键
String id = hit.getId();
//源文档内容
Map sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期
Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp"));
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
9.BoolQuery 布尔查询中搭配过滤器查询(常用):
使用场景:过虑是针对搜索的结果进行过虑,过虑器主要判断的是文档是否匹配,不去计算和判断文档的匹配度得分,所以过虑器性能比查询要高,且方便缓存,推荐尽量使用过虑器去实现查询或者过虑器和查询共同使用。
@Test
public void testFilter() throws IOException, ParseException {
//搜索请求对象
SearchRequest searchRequest = new SearchRequest("xc_course");
//指定类型
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//搜索方式,用布尔查询,简单来说,就是把多个查询方式或者过滤器组合一起使用
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//1.自定义的查询对象,MultiMatchQuery
MultiMatchQueryBuilder field = QueryBuilders.multiMatchQuery("spring css", "name", "description")
//.minimumShouldMatch("50%"),至少要找到搜索分词的50%才行
.minimumShouldMatch("50%")
//.field("name",10));name这个列的得分权重提高10倍
.field("name", 10);
//2.********通过布尔的过滤器,精确列查询对象,termQuery********
boolQueryBuilder.filter(QueryBuilders.termQuery("studymodel", "201001"));
//2.1:通过布尔的过滤器,:判断价格列的值大于80小于100
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte("60").lte("100"));
//3.********把自定义查询对象组装在一个布尔查询的对象中********
//往里面扔查询对象
boolQueryBuilder.must(field);
//4.通过布尔查询对象,获取值
searchSourceBuilder.query(boolQueryBuilder);
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求
SearchResponse searchResponse = client.search(searchRequest);
//搜索结果
SearchHits hits = searchResponse.getHits();
//匹配到的总记录数
long totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//日期格式化对象
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for(SearchHit hit:searchHits){
//文档的主键
String id = hit.getId();
//源文档内容
Map sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期
Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp"));
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
9.搜索源对象+排序功能(常用):searchSourceBuilder.sort() 上加排序
可以在字段上添加一个或多个排序,支持在keyword、date、float等类型上添加,text类型的字段上不允许添加排序。
@Test
public void testSort() throws IOException, ParseException {
//搜索请求对象
SearchRequest searchRequest = new SearchRequest("xc_course");
//指定类型
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//1.搜索方式,用布尔查询,简单来说,就是把多个查询方式或者过滤器组合一起使用
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//2:通过布尔的过滤器,:判断价格列的值大于0小于100
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte("0").lte("100"));
//3.通过布尔查询对象,获取值
searchSourceBuilder.query(boolQueryBuilder);
//4.********把结果,按照列名,依次进行排序********
searchSourceBuilder.sort("studymodel", SortOrder.DESC);
searchSourceBuilder.sort("price", SortOrder.ASC);
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求
SearchResponse searchResponse = client.search(searchRequest);
//搜索结果
SearchHits hits = searchResponse.getHits();
//匹配到的总记录数
long totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//日期格式化对象
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for(SearchHit hit:searchHits){
//文档的主键
String id = hit.getId();
//源文档内容
Map sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期
Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp"));
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
10.Highlight 高亮显示匹配的字符
高亮显示可以将搜索结果一个或多个字突出显示,以便向用户展示匹配关键字的位置。
@Test
public void testHighlight() throws IOException, ParseException {
//搜索请求对象
SearchRequest searchRequest = new SearchRequest("xc_course");
//指定类型
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//boolQuery搜索方式
//先定义一个MultiMatchQuery
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("开发框架", "name", "description")
.minimumShouldMatch("50%")
.field("name", 10);
//定义一个boolQuery布尔查询对象
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//添加一个通过开发框架,4个字符,匹配name这个列,附加10倍权重
boolQueryBuilder.must(multiMatchQueryBuilder);
//定义过虑器,价格区间过滤
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(0).lte(100));
searchSourceBuilder.query(boolQueryBuilder);
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});
//**********在查询之前,设置高亮对象*********
HighlightBuilder highlightBuilder = new HighlightBuilder();
//设置高亮的前半截标签
highlightBuilder.preTags("");
//设置高亮的后半截标签
highlightBuilder.postTags("");
//对name列进行添加高亮标签
highlightBuilder.fields().add(new HighlightBuilder.Field("name"));
//*********把高亮对象,给搜索源*********
searchSourceBuilder.highlighter(highlightBuilder);
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求
SearchResponse searchResponse = client.search(searchRequest);
//搜索结果
SearchHits hits = searchResponse.getHits();
//匹配到的总记录数
long totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//日期格式化对象
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for(SearchHit hit:searchHits){
//文档的主键
String id = hit.getId();
//源文档内容
Map sourceAsMap = hit.getSourceAsMap();
//源文档的name字段内容
String name = (String) sourceAsMap.get("name");
//*********遍历得到的文档,并且取出高亮字段*********
Map highlightFields = hit.getHighlightFields();
if(highlightFields!=null){
//取出name这个列的高亮字段
HighlightField nameHighlightField = highlightFields.get("name");
if(nameHighlightField!=null){
//Text,导入ES的Text包:org.elasticsearch.common.text.Text;
//取出匹配到的列数据,其中含有高亮字段,
Text[] fragments = nameHighlightField.getFragments();
//遍历字段,进行拼接
StringBuffer stringBuffer = new StringBuffer();
for(Text text:fragments){
stringBuffer.append(text);
}
name = stringBuffer.toString();
System.err.println(name);
}
}//*************取高亮字段结束**************
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期
Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp"));
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
//方法结束
}
8 集群管理
1、结点
ES集群由多个服务器组成,每个服务器即为一个Node结点(该服务只部署了一个ES进程)。
2、分片
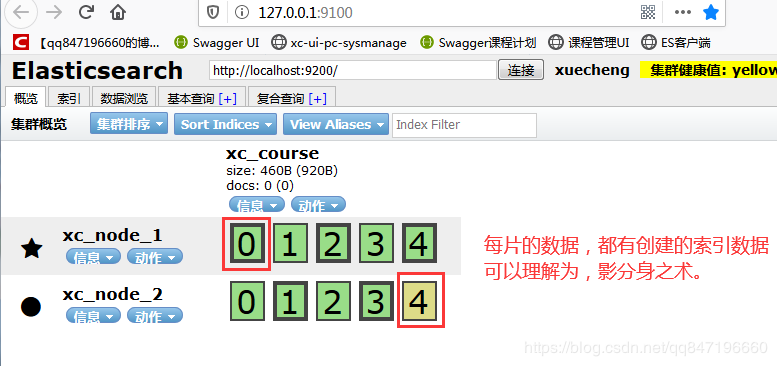
当我们的文档量很大时,由于内存和硬盘的限制,同时也为了提高ES的处理能力、容错能力及高可用能力,我们将
索引分成若干分片,每个分片可以放在不同的服务器,这样就实现了多个服务器共同对外提供索引及搜索服务。
一个搜索请求过来,会分别从各各分片去查询,最后将查询到的数据合并返回给用户。
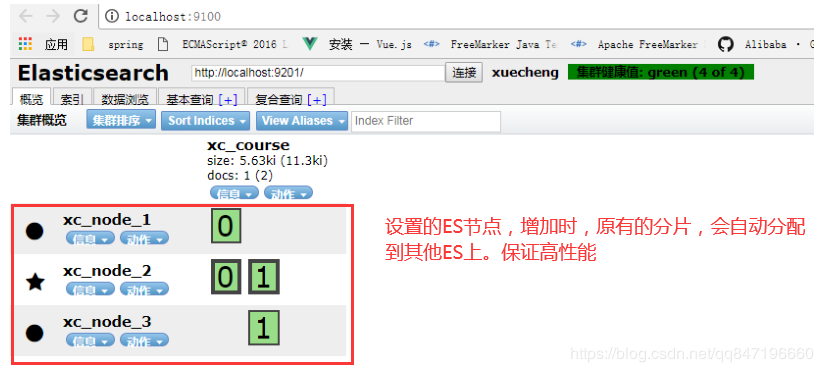
3、副本
为了提高ES的高可用同时也为了提高搜索的吞吐量,我们将分片复制一份或多份存储在其它的服务器,这样即使当
前的服务器挂掉了,拥有副本的服务器照常可以提供服务。
4、主结点
一个集群中会有一个或多个主结点,主结点的作用是集群管理,比如增加节点,移除节点等,主结点挂掉后ES会重
新选一个主结点。
5、结点转发
每个结点都知道其它结点的信息,我们可以对任意一个结点发起请求,接收请求的结点会转发给其它结点查询数
据。
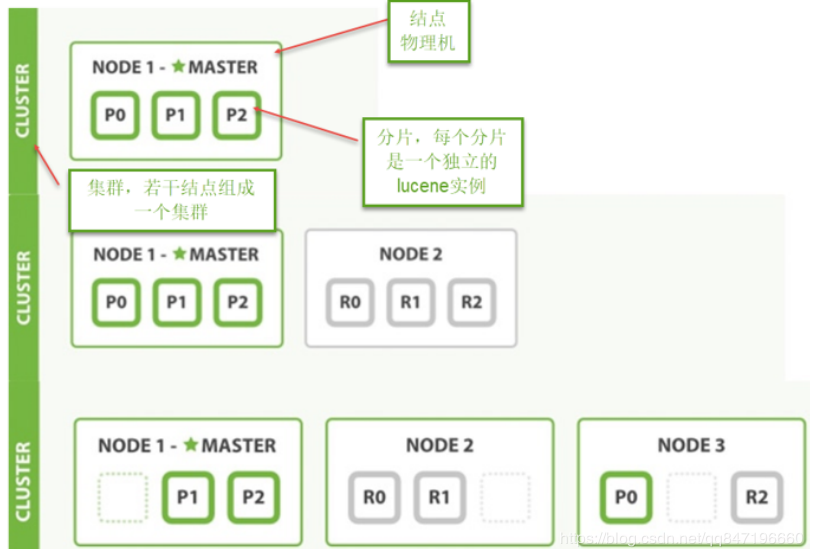
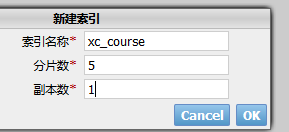
下边的例子实现创建一个2结点的集群,并且索引的分片我们设置2片,每片一个副本。
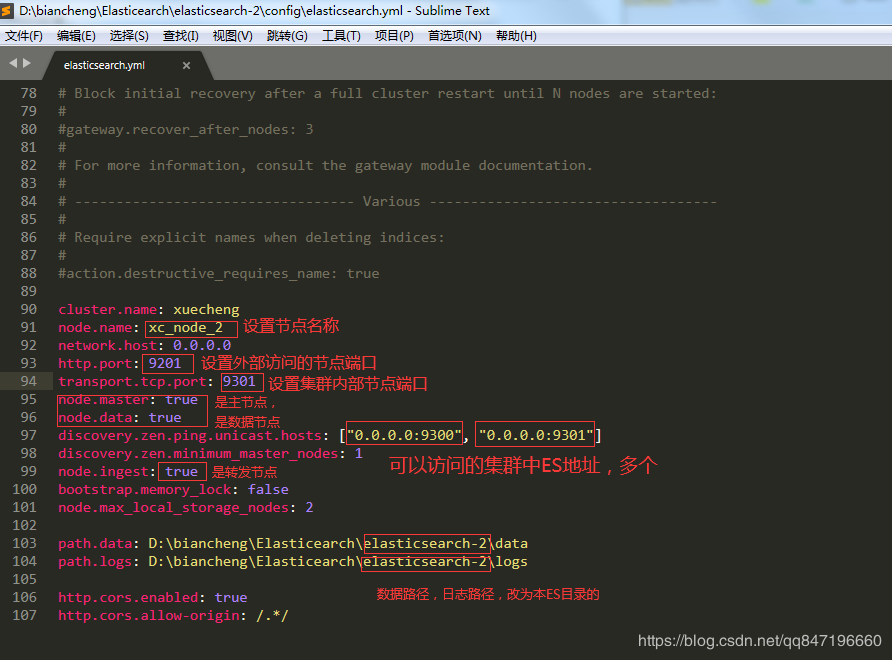
8.2.1 结点的三个角色主结点:master节点主要用于集群的管理及索引 比如新增结点、分片分配、索引的新增和删除等。 数据结点:
data 节点上保存了数据分片,它负责索引和搜索操作。 客户端结点:client 节点仅作为请求客户端存在,client的
作用也作为负载均衡器,client 节点不存数据,只是将请求均衡转发到其它结点。
通过下边两项参数来配置结点的功能:
node.master: #是否允许为主结点
node.data: #允许存储数据作为数据结点
node.ingest: #是否允许成为协调节点,
四种组合方式:
master=true,data=true:即是主结点又是数据结点
master=false,data=true:仅是数据结点
master=true,data=false:仅是主结点,不存储数据
master=false,data=false:即不是主结点也不是数据结点,此时可设置ingest为true表示它是一个客户端。
复制的ES中已经配置好了我们自己的IK分词器,需要知晓。
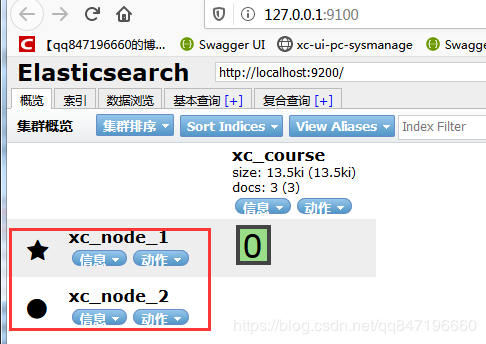
刷新head客户端查看:http://127.0.0.1:9100/
1.主副节点的自动更替,
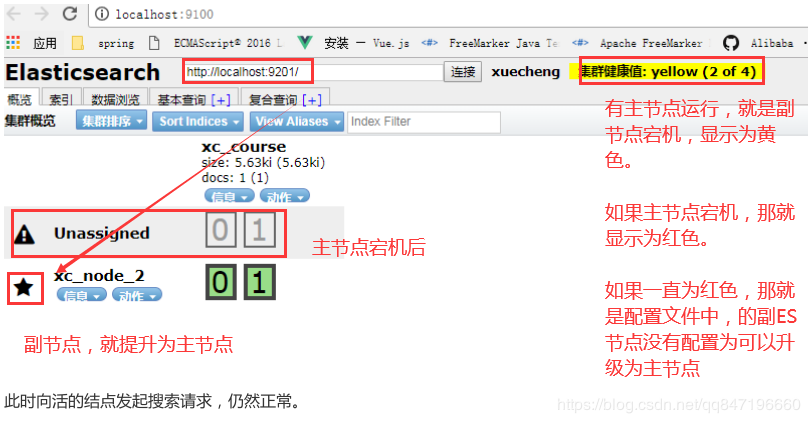
2.自动分片备份,
3.自动转发分片里面的资料,
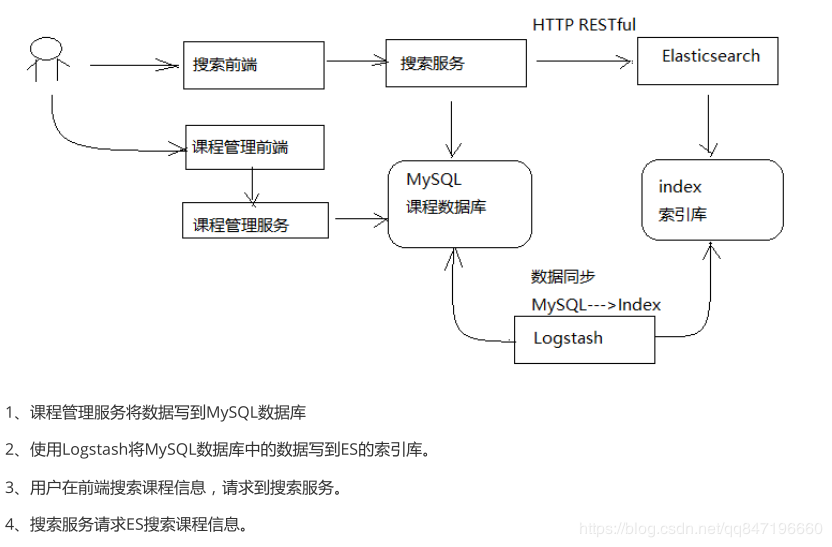
1.2 搜索流程
3.2.1创建课程索引发布表
这张表构成:课程Base+课程营销+课程图片+课程计划
创建course_pub表
课程发布表模型,对应实体类
@Data
@ToString
@Entity
@Table(name="course_pub")
@GenericGenerator(name = "jpa-assigned", strategy = "assigned")
public class CoursePub implements Serializable {
private static final long serialVersionUID = -916357110051689487L;
@Id
@GeneratedValue(generator = "jpa-assigned")
@Column(length = 32)
private String id;
private String name;
private String users;
private String mt;
private String st;
private String grade;
private String studymodel;
private String teachmode;
private String description;
private String pic;//图片
private Date timestamp;//时间戳
private String charge;
private String valid;
private String qq;
private Float price;
private Float price_old;
private String expires;
private String teachplan;//课程计划
@Column(name="pub_time")
private String pubTime;//课程发布时间
}
课程索引的dao:
public interface CoursePubRepository extends JpaRepository {
}
修改课程发布service,再发布课程的收,更新课程索引表。
//保存课程索引信息
//先创建一个coursePub对象
CoursePub coursePub = createCoursePub(id);
//将coursePub对象保存到数据库
saveCoursePub(id,coursePub);
//缓存课程的信息
//...
//把得到的url,返回
String pageUrl = cmsPostPageResult.getPageUrl();
return new CoursePublishResult(CommonCode.SUCCESS,pageUrl);
}
/***
* 将coursePub对象保存到数据库
* @param id 课程id
* @param coursePub 课程索引对象
*/
private CoursePub saveCoursePub(String id,CoursePub coursePub){
// 先准备一个新的索引
CoursePub coursePubNew = null;
//先通过id,查询有没有这个索引
Optional optionalPub = coursePubRepository.findById(id);
if (optionalPub.isPresent()){
//有这个索引就取出来备用
coursePubNew = optionalPub.get();
}else {
//如果没有这个索引,就创建一个新的索引对象
coursePubNew = new CoursePub();
}
//得到索引对象后,执行覆盖索引的操作。穿进来的新的覆盖旧的或者新new的
BeanUtils.copyProperties(coursePubNew,coursePub);
//最后把课程的id,设置一下
coursePubNew.setId(id);
//设置时间戳,给logstach使用
coursePubNew.setTimestamp(new Date());
//发布时间
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String format = simpleDateFormat.format(new Date());
//设置课程发布的时间
coursePubNew.setPubTime(format);
//最后执行保存
coursePubRepository.save(coursePubNew);
return coursePubNew;
}
//创建课程索引的方法,这张表构成:课程Base+课程营销+课程图片+课程计划
private CoursePub createCoursePub(String id){
//先创建空索引对象,再拼接每张表的参数,注入把数据复制进去的时候,2个对象都不能为null。
CoursePub coursePub = new CoursePub();
//根据课程id查询course_base
Optional baseOptional = courseBaseRepository.findById(id);
if(baseOptional.isPresent()){
CourseBase courseBase = baseOptional.get();
//将courseBase属性拷贝到CoursePub中
BeanUtils.copyProperties(courseBase,coursePub);
}
//查询课程图片
Optional picOptional = coursePicRepository.findById(id);
if(picOptional.isPresent()){
CoursePic coursePic = picOptional.get();
BeanUtils.copyProperties(coursePic, coursePub);
}
//课程营销信息
Optional marketOptional = courseMarketRepository.findById(id);
if(marketOptional.isPresent()){
CourseMarket courseMarket = marketOptional.get();
BeanUtils.copyProperties(courseMarket, coursePub);
}
//课程计划信息
TeachplanNode teachplanNode = teachplanMapper.selectList(id);
//表中的结构是通过json串定义的,所以需要转为json串
String jsonString = JSON.toJSONString(teachplanNode);
//将课程计划信息json串保存到 course_pub中
coursePub.setTeachplan(jsonString);
return coursePub;
}
3.3 搭建ES环境
开发环境使用ES单机环境,不用集群,所以关掉一个节点。
3.3.2 创建索引库
创建xc_course索引库,一个分片,0个副本。
3.3.3 创建映射
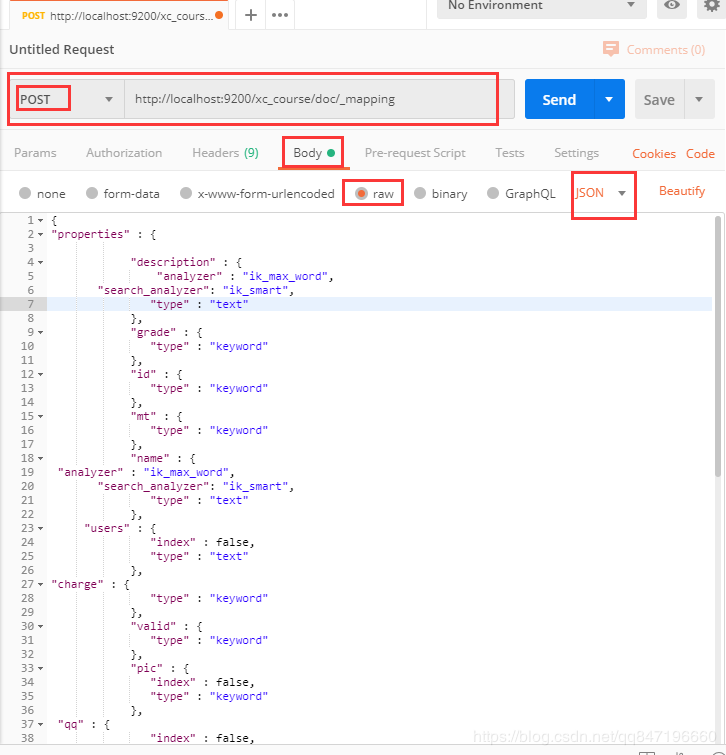
请求和映射字段:
http://localhost:9200/xc_course/doc/_mapping
{
"properties" : {
"description" : {
"analyzer" : "ik_max_word",
"search_analyzer": "ik_smart",
"type" : "text"
},
"grade" : {
"type" : "keyword"
},
"id" : {
"type" : "keyword"
},
"mt" : {
"type" : "keyword"
},
"name" : {
"analyzer" : "ik_max_word",
"search_analyzer": "ik_smart",
"type" : "text"
},
"users" : {
"index" : false,
"type" : "text"
},
"charge" : {
"type" : "keyword"
},
"valid" : {
"type" : "keyword"
},
"pic" : {
"index" : false,
"type" : "keyword"
},
"qq" : {
"index" : false,
"type" : "keyword"
},
"price" : {
"type" : "float"
},
"price_old" : {
"type" : "float"
},
"st" : {
"type" : "keyword"
},
"status" : {
"type" : "keyword"
},
"studymodel" : {
"type" : "keyword"
},
"teachmode" : {
"type" : "keyword"
},
"teachplan" : {
"analyzer" : "ik_max_word",
"search_analyzer": "ik_smart",
"type" : "text"
},
"expires" : {
"type" : "date",
"format": "yyyy‐MM‐dd HH:mm:ss"
},
"pub_time" : {
"type" : "date",
"format": "yyyy‐MM‐dd HH:mm:ss"
},
"start_time" : {
"type" : "date",
"format": "yyyy‐MM‐dd HH:mm:ss"
},
"end_time" : {
"type" : "date",
"format": "yyyy‐MM‐dd HH:mm:ss"
}
}
}
3.4 Logstash 创建索引(巨坑章节,注意步骤)
Logstash是ES下的一款开源软件,它能够同时 从多个来源采集数据、转换数据,然后将数据发送到Eleasticsearch中创建索引。
本项目使用Win系统的Logstash将MySQL中的数据采用到ES索引中。
3.4.1 下载Logstash
下载Logstash6.2.1版本,和本项目使用的Elasticsearch6.2.1 版本必须保持一致。
Elasticsearch和Logstash的官网:
https://elasticsearch.cn/download/
安装Ruby-2.5-X64和logstash-input-jdbc,6.2.1必须搭配 2.5版本,必须(巨坑)
logstash-input-jdbc 是ruby开发的,先下载ruby并安装,傻瓜安装,不用配置环境变量
ruby的所有历史版本地址:
https://rubyinstaller.org/downloads/archives/
ruby-2.5.0.1-x64地址:
https://github.com/oneclick/rubyinstaller2/releases/download/rubyinstaller-2.5.0-1/rubyinstaller-2.5.0-1-x64.exe
安装完成查看是否安装成功
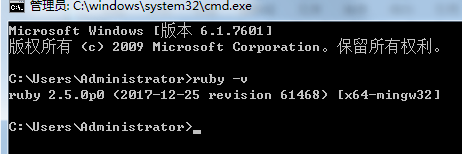
Logstash5.x以上版本本身自带有logstash-input-jdbc,6.x版本本身不带logstash-input-jdbc插件,需要手动安装(备注:我没安装成功过,而且下载下来的6.2.1里面有这个jdbc插件,具体不知道。也可以直接使用学成的那个资料logstach6.2.1)

我们使用的是:老师给的资料
3.4.3 创建模板文件和配置数据的连接池信息
Logstash的工作是从MySQL中读取数据,向ES中创建索引,这里需要提前创建mapping的模板文件以便logstash
使用。
在logstach的config目录创建xc_course_template.json,内容如下:
注意,我们是直接复制老师给的模板json和mysql.conf配置文件
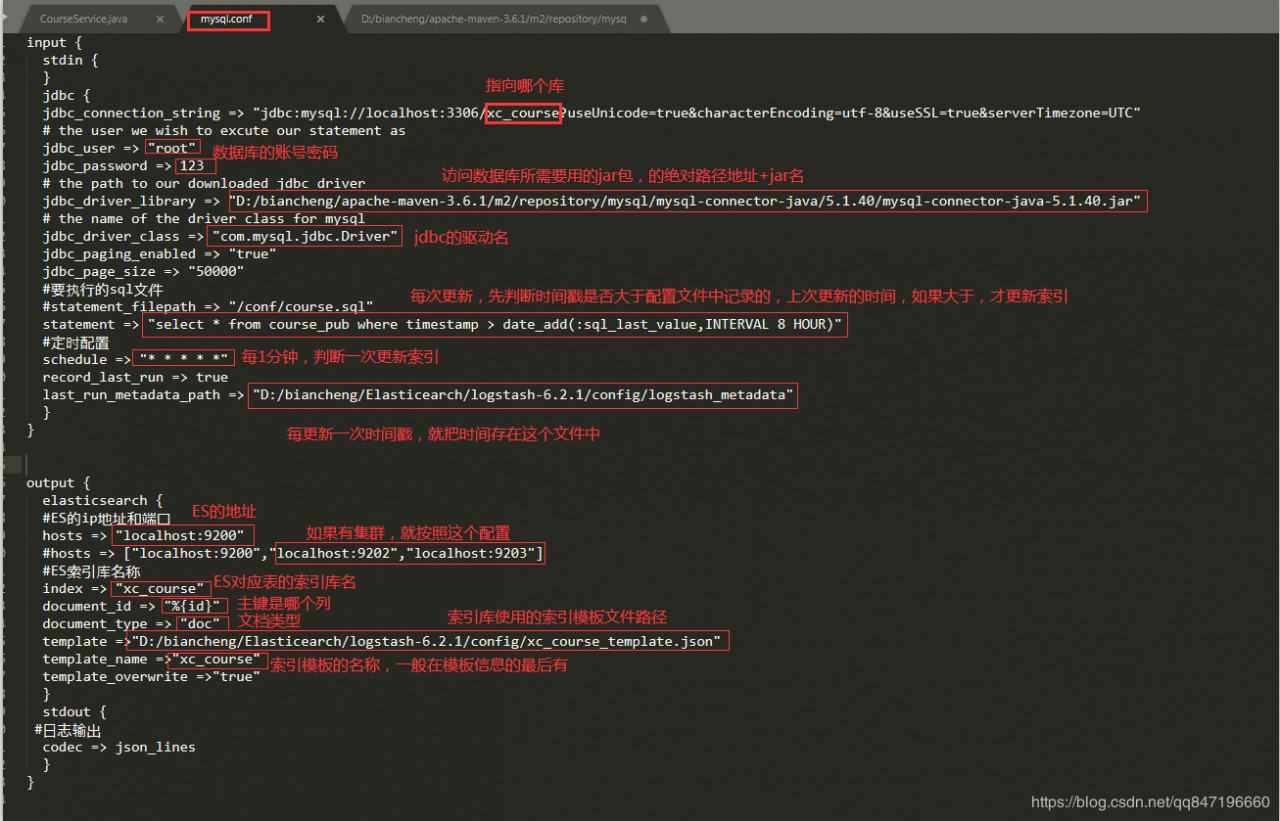
配置数据库mysql.conf的连接池信息:
在logstash的config目录下配置mysql.conf文件供logstash使用,logstash会根据mysql.conf文件的配置的地址从MySQL中读取数据向ES中写入索引
最后成型的配置文件:
input {
stdin {
}
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/xc_course?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC"
# the user we wish to excute our statement as
jdbc_user => "root"
jdbc_password => "123"
# the path to our downloaded jdbc driver
jdbc_driver_library => "D:/biancheng/apache-maven-3.6.1/m2/repository/mysql/mysql-connector-java/5.1.41/mysql-connector-java-5.1.41.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#要执行的sql文件
#statement_filepath => "/conf/course.sql"
statement => "select * from course_pub where timestamp > date_add(:sql_last_value,INTERVAL 8 HOUR)"
#定时配置
schedule => "* * * * *"
record_last_run => true
last_run_metadata_path => "D:/biancheng/Elasticearch/logstash-6.2.1/config/logstash_metadata"
}
}
output {
elasticsearch {
#ES的ip地址和端口
hosts => "localhost:9200"
#hosts => ["localhost:9200","localhost:9202","localhost:9203"]
#ES索引库名称
index => "xc_course"
document_id => "%{id}"
document_type => "doc"
template =>"D:/biancheng/Elasticearch/logstash-6.2.1/config/xc_course_template.json"
template_name =>"xc_course"
template_overwrite =>"true"
}
stdout {
#日志输出
codec => json_lines
}
}
说明:
1、ES采用UTC时区问题
ES采用UTC 时区,比北京时间早8小时,所以ES读取数据时让最后更新时间加8小时
where timestamp > date_add(:sql_last_value,INTERVAL 8 HOUR)
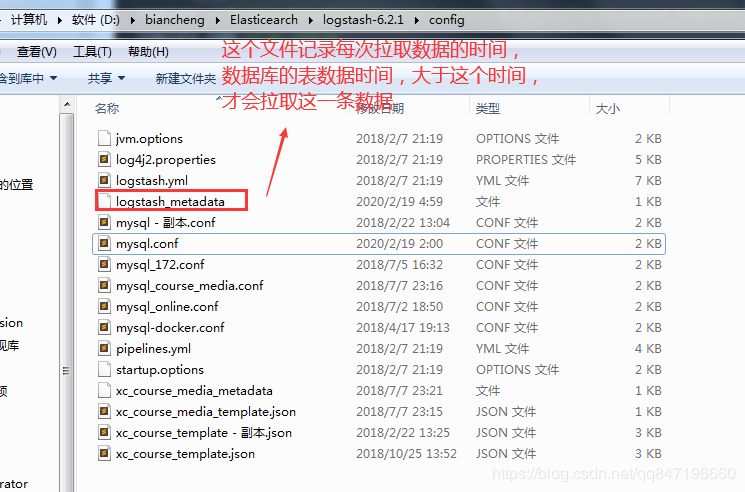
2、logstash每个执行完成会在D:/ElasticSearch/logstash-6.2.1/config/logstash_metadata记录执行时间下次以此
时间为基准进行增量同步数据到索引库。
3.4.5 测试
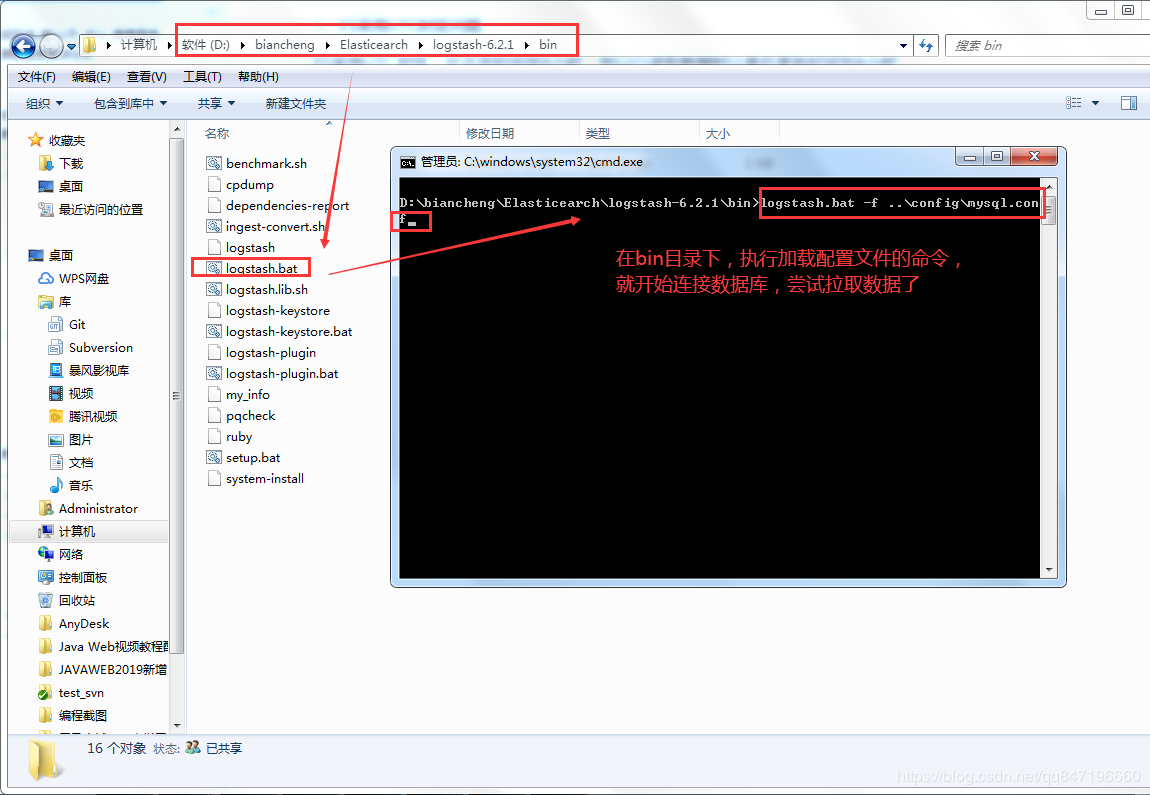
logstash.bat -f ..\config\mysql.conf
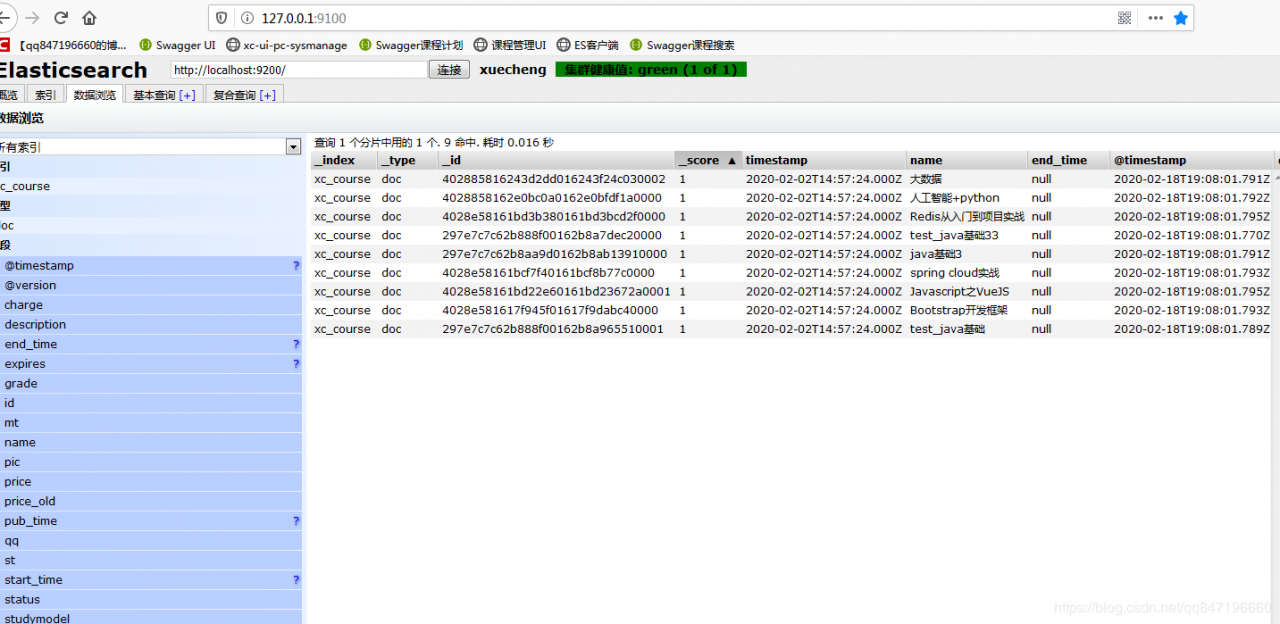
出现这些字样,并且索引库中有数据,就是拉取成功了

4.1 需求分析

创建xc-service-search搜索服务工程
1、配置appliction.yml
server:
port: ${port:40100}
spring:
application:
name: xc-search-service
xuecheng:
elasticsearch:
hostlist: ${eshostlist:127.0.0.1:9200} #多个结点中间用逗号分隔
course:
#ES的索引库名,理解为表名就行
index: xc_course
#ES表的类型。无意义字段:doc
type: doc
#ES搜索要显示的字段
source_field: id,name,grade,mt,st,charge,valid,pic,qq,price,price_old,status,studymodel,teachmode,expires,pub_time,start_time,end_time
2、写ES的2个高低性能的客户端配置类,测试搜索Api的时候,其实已经写好了
/**
* ES的2个高低性能的客户端配置类
**/
@Configuration
public class ElasticsearchConfig {
//取ES得配置地址和端口
@Value("${xuecheng.elasticsearch.hostlist}")
private String hostlist;
@Bean
public RestHighLevelClient restHighLevelClient(){
//解析hostlist配置信息,如果有集群,就把全部地址切分为数组
String[] split = hostlist.split(",");
//创建HttpHost数组,其中存放es主机和端口的配置信息
HttpHost[] httpHostArray = new HttpHost[split.length];
for(int i=0;i<split.length;i++){
String item = split[i];
httpHostArray[i] = new HttpHost(item.split(":")[0], Integer.parseInt(item.split(":")[1]), "http");
}
//创建RestHighLevelClient客户端,通过所有的地址,来创建,高可用的客户端。
return new RestHighLevelClient(RestClient.builder(httpHostArray));
}
//项目主要使用RestHighLevelClient,对于低级的客户端暂时不用,但最好配着
@Bean
public RestClient restClient(){
//解析hostlist配置信息
String[] split = hostlist.split(",");
//创建HttpHost数组,其中存放es主机和端口的配置信息
HttpHost[] httpHostArray = new HttpHost[split.length];
for(int i=0;i<split.length;i++){
String item = split[i];
httpHostArray[i] = new HttpHost(item.split(":")[0], Integer.parseInt(item.split(":")[1]), "http");
}
return RestClient.builder(httpHostArray).build();
}
}
写API接口:
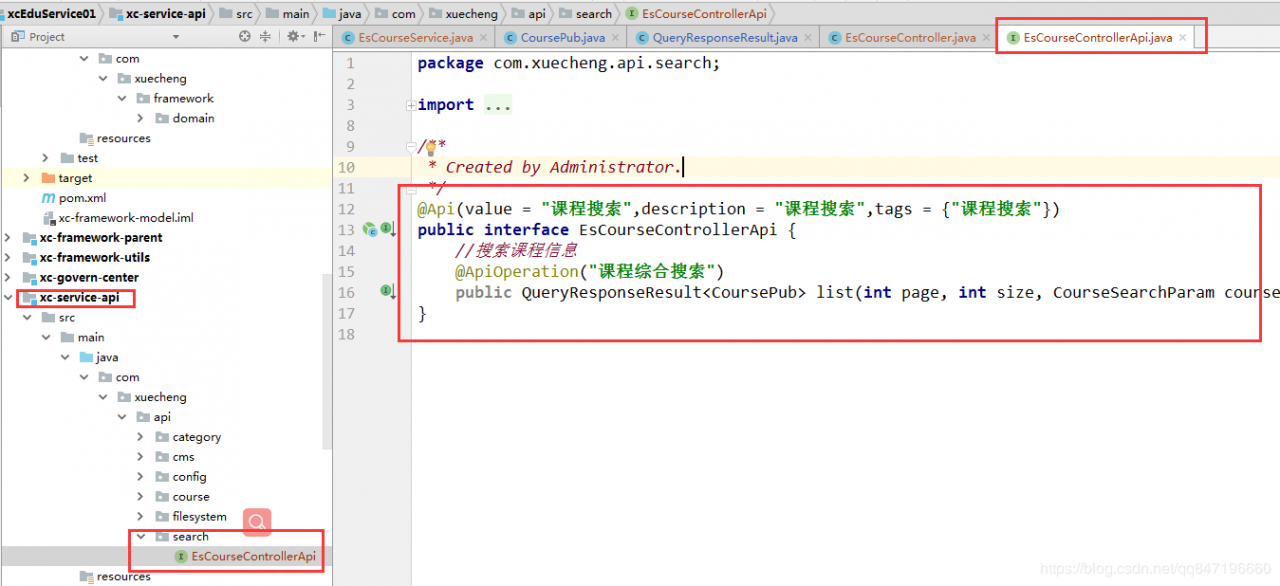
@Api(value = "课程搜索",description = "课程搜索",tags = {"课程搜索"})
public interface EsCourseControllerApi {
//搜索课程信息
@ApiOperation("课程综合搜索")
public QueryResponseResult list(int page, int size, CourseSearchParam courseSearchParam);
}
Service
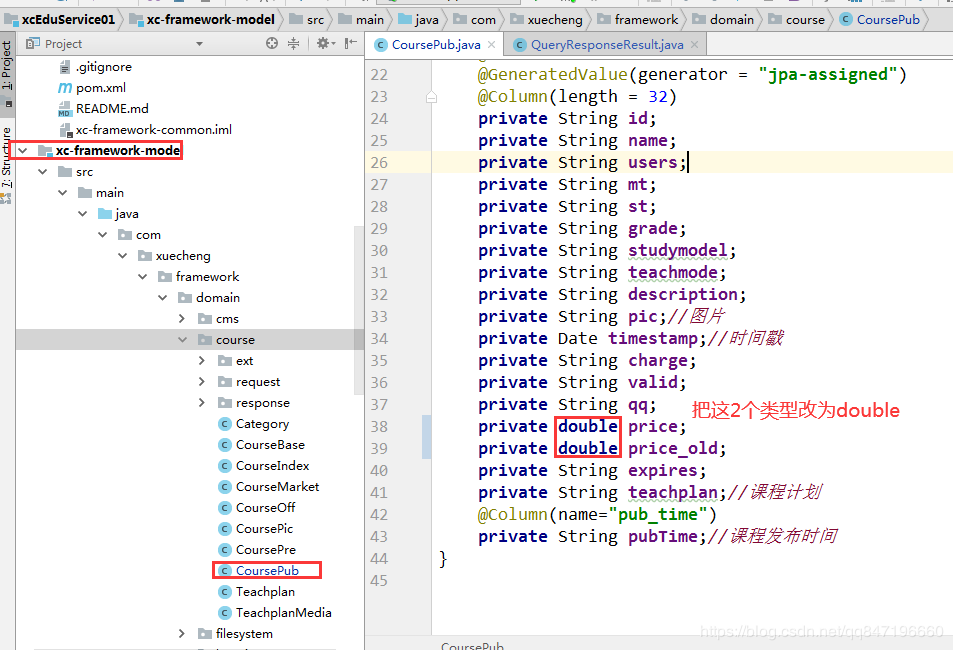
介绍1:对应实体类的改造
索引实体类,的价格类型是float,改为double
返回分页数据的集合泛型要改,不然报错
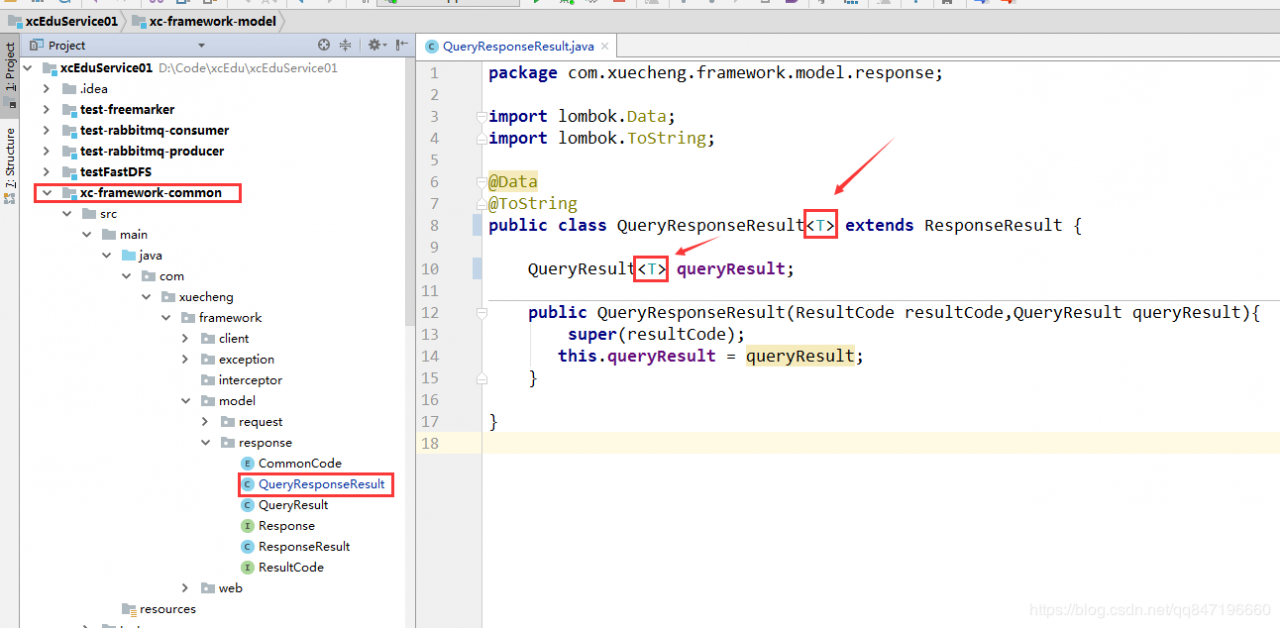
Service方法代码复杂,这里分三步完成。
import com.xuecheng.framework.domain.course.CoursePub;
import com.xuecheng.framework.domain.search.CourseSearchParam;
import com.xuecheng.framework.model.response.CommonCode;
import com.xuecheng.framework.model.response.QueryResponseResult;
import com.xuecheng.framework.model.response.QueryResult;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MultiMatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.beans.factory.annotation.Value;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Service
public class EsCourseService {
//先注入相关的配置参数,索引库名,索引库类型,索引显示字段
@Value("${xuecheng.course.index}")
private String index;
@Value("${xuecheng.course.type}")
private String type;
@Value("${xuecheng.course.source_field}")
private String source_field;
//高可用的ES请求客户端
@Autowired
RestHighLevelClient restHighLevelClient;
/***
* 课程索引搜索
* @param page 当前页码
* @param size 显示条数
* @param courseSearchParam 综合查询条件,把所有查询条件,封装为一个条件查询的对象
* @return 分页索引表的集合对象
*/
public QueryResponseResult list(int page, int size, CourseSearchParam courseSearchParam) {
//判断进来的条件查询,为空,就无参构造一个查询对象
if(courseSearchParam == null){
courseSearchParam = new CourseSearchParam();
}
//创建搜索请求对象,参数是:xc_course
SearchRequest searchRequest = new SearchRequest(index);
//设置搜索类型:doc
searchRequest.types(type);
//创建搜索源,也就是所有查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//过虑源字段,把配置好要显示的字段,切割为数组
String[] source_field_array = source_field.split(",");
//设置搜索源,要显示的字段。参数1:要显示的字段,参数2:不显示的字段
searchSourceBuilder.fetchSource(source_field_array,new String[]{});
//创建布尔查询对象,可以添加很多的查询条件,满足综合查询的要求
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//搜索条件
//根据关键字搜索
if(StringUtils.isNotEmpty(courseSearchParam.getKeyword())){
//通过关键字,自定义搜索名称,描述,课程计划,这三个字段
MultiMatchQueryBuilder multiMatchQueryBuilder =
QueryBuilders.multiMatchQuery(courseSearchParam.getKeyword(),
"name", "description", "teachplan")
// 其中3个字段中匹配到2个就能符合要求
.minimumShouldMatch("70%")
// 名称这个列,匹配的权重得分*10倍
.field("name", 10);
//把这个自定义的查询添加进布尔查询,且最后返回的结果必须满足这个查询机制的要求。
boolQueryBuilder.must(multiMatchQueryBuilder);
}
if(StringUtils.isNotEmpty(courseSearchParam.getMt())){
//根据一级分类,根具字段名称,精确匹配
boolQueryBuilder.filter(QueryBuilders.termQuery("mt",courseSearchParam.getMt()));
}
if(StringUtils.isNotEmpty(courseSearchParam.getSt())){
//根据二级分类,根具字段名称,精确匹配
boolQueryBuilder.filter(QueryBuilders.termQuery("st",courseSearchParam.getSt()));
}
if(StringUtils.isNotEmpty(courseSearchParam.getGrade())){
//根据难度等级,根具字段名称,精确匹配
boolQueryBuilder.filter(QueryBuilders.termQuery("grade",courseSearchParam.getGrade()));
}
//设置布尔查询到搜索源对象
searchSourceBuilder.query(boolQueryBuilder);
//搜索请求对象,把设置好的搜索源,拿去索引库查
searchRequest.source(searchSourceBuilder);
//提前准备一个总分页的索引集合对象
QueryResult queryResult = new QueryResult();
//准备一个装分页索引数据的集合
List list = new ArrayList();
try {
//用高可用的ES请求客户端,执行搜索
SearchResponse searchResponse = restHighLevelClient.search(searchRequest);
//获取响应结果
SearchHits hits = searchResponse.getHits();
//匹配的总记录数
long totalHits = hits.totalHits;
//把搜