轻量级网络:减少参数量的几种方法
从 Inception 到 Xception 的发展一路看来,出现了很多精巧的结构设计和理念思想:
1、多个不同尺寸的卷积核,提高对不同尺度特征的适应能力
2、PW 卷积,降维或升维的同时,提高网络的表达能力
PW卷积:Pointwise Convolution,俗称 1x1 卷积,主要用于数据降维,减少参数量。
使用 1x1 卷积核对输入的特征图进行降维处理,这样就会极大地减少参数量,从而减少计算。例如,输入数据的维度是 256 维,经过 1x1 卷积之后,我们输出的维度是 64 维,参数量是原来的 1/4 。
PW 也可以用做升维,MobileNet V2 中使用 PW 将 3 个特征图变成 6 个特征图,丰富输入数据的特征。
3、多个小尺寸卷积核替代大卷积核,加深网络的同时减少参数量
4、精巧的 Bottleneck 结构,大大减少网络参数量
参考链接:https://blog.csdn.net/duan19920101/article/details/104349188
5、精巧的 Depthwise Separable Conv 设计,再度减少参数量
输入的是 2 维的数据,我们要进行 3x3 卷积并输出 3 维的数据,与正常卷积对比:
对于某一个卷积层,它的参数个数为:(Kh * Kw * Cin) * Cout + Cout,参数Kh 和Kw表示卷积核的高和宽,Cin 表示输入通道数, Cout表示输出通道数。
1> 标准卷积
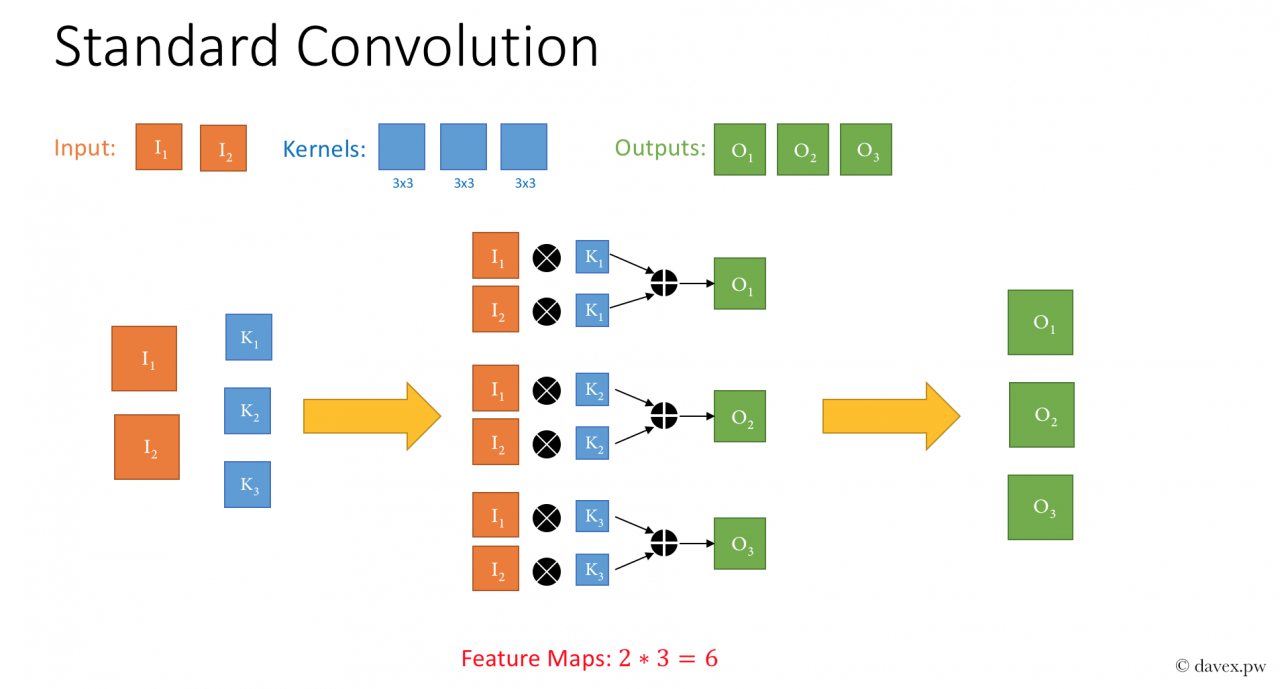
参数个数:2*3*3*3=54
2> DW 卷积
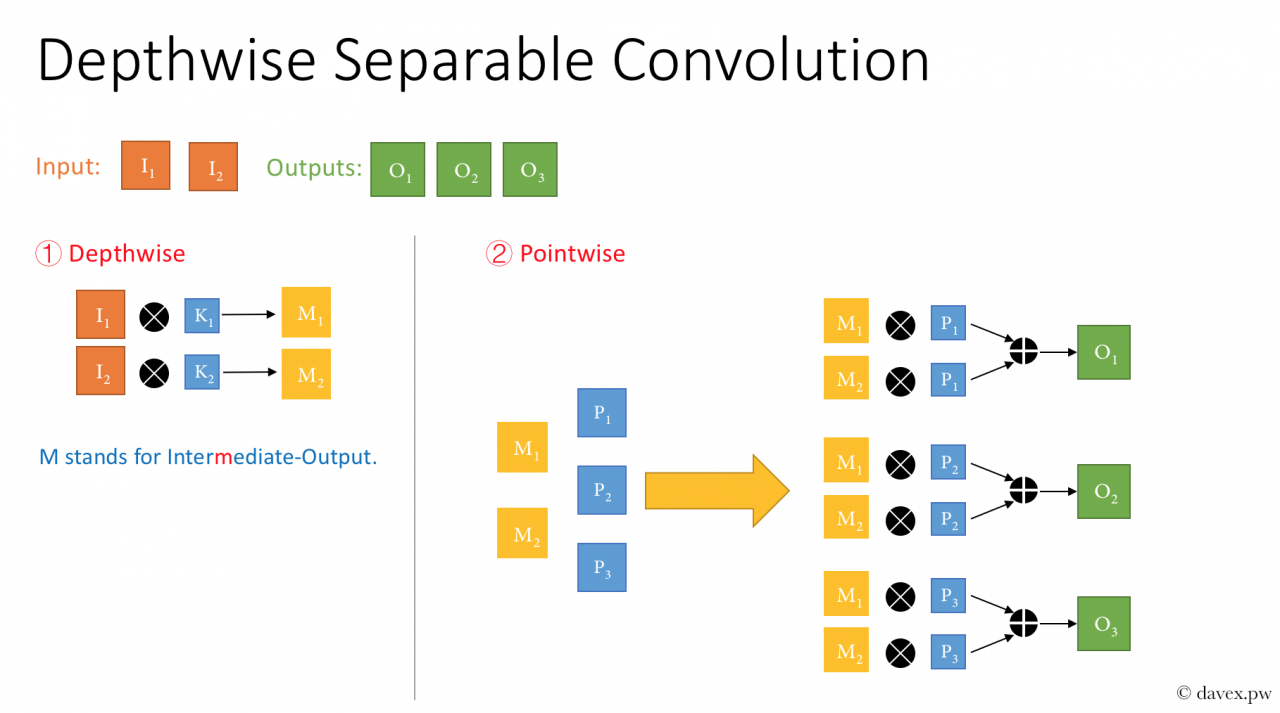
参数个数:2*3*3+2*1*1*3=18+6=24
参数量对比:24/54=0.444
我们可以看到,参数量是正常卷积的一半,但实际上可以更少,只不过在输入输出维度相差不大的情况下,效果没那么明显。
参考链接:https://www.jianshu.com/p/4708a09c4352
作者:那年聪聪
相关文章
Danica
2020-09-03
Hope
2021-03-01
Serwa
2020-03-20
Hester
2023-07-22
Grace
2023-07-22
Vanna
2023-07-22
Peony
2023-07-22
Dorothy
2023-07-22
Dulcea
2023-07-22
Zandra
2023-07-22
Serafina
2023-07-24
Kathy
2023-08-08
Olivia
2023-08-08
Oria
2023-08-08
Elina
2023-08-08
Jacinthe
2023-08-08
Viridis
2023-08-08
Hana
2023-08-08
Cybill
2023-08-08
Elsa
2023-08-08