3.2 机器学习 - NLP和情感分析
案例1:利用贝叶斯方法的多项式模型分析新闻数据
作者:喝醉酒的小白
数据#1
!wget http://qwone.com/~jason/20Newsgroups/20news-bydate.tar.gz
!ls
!tar -xzf 20news-bydate.tar.gz
!ls
!ls 20news-bydate-test
!ls 20news-bydate-train
!ls 20news-bydate-test/rec.autos
!cat 20news-bydate-test/rec.autos/103744
数据#2
!git clone https://github.com/qiwsir/DataSet.git
!ls DataSet
!ls DataSet/20newsbydate
!ls DataSet/movie_data
案例2:情感分析:分析影评数据
NLTK
NLTK是构建Python程序以使用人类语言数据的领先平台。
它为50多种语料库和词汇资源(如WordNet)提供了易于使用的界面,以及用于分类,标记化,词干,标记,解析和语义推理的文本处理库套件。
import nltk
nltk.download('punkt')
sentence = "The Quick brown fox, Jumps over the lazy little dog. Hello World."
word_tokenize(sentence)

sentence.split()

sentence.split(’,’)
![]()
from nltk.corpus import movie_reviews
nltk.download('movie_reviews')
影评类别
movie_reviews.categories()

显示存储影评的文档
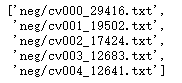
movie_reviews.fileids()[:5]
对所有文档中的词汇进行统计
all_words = movie_reviews.words() # 得到所有词汇
freq_dist = nltk.FreqDist(all_words) # 对单词计数
freq_dist.most_common(20) #

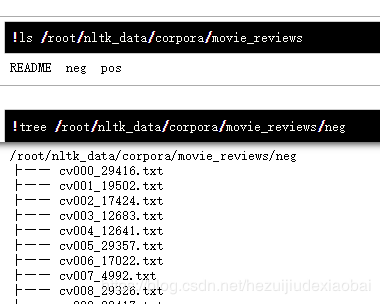
!ls /root/nltk_data/corpora/movie_reviews
!tree /root/nltk_data/corpora/movie_reviews/neg
作者:喝醉酒的小白