deeplearning_class3:过拟合、欠拟合、梯度消失、梯度爆炸
1 过拟合、欠拟合及解决方案
1.1 训练误差和泛化误差
训练误差:指模型在训练数据集上表现出的误差
泛化误差:值模型在任意一个测试数据样本上表现出的误差的期望,并通过测试数据集上的误差来近似
1.2 过拟合和欠拟合
欠拟合:模型无法得到较低的训练误差
过拟合:模型的训练误差远小于他在测试数据集上的误差
1.3 模型复杂度
课程里讲的模糊不清,笔者的理解就是模型的复杂程度,参数多的,复杂度高,训练时间长,参数少的,复杂度地,训练时间短,复杂度和误差的关系如图。
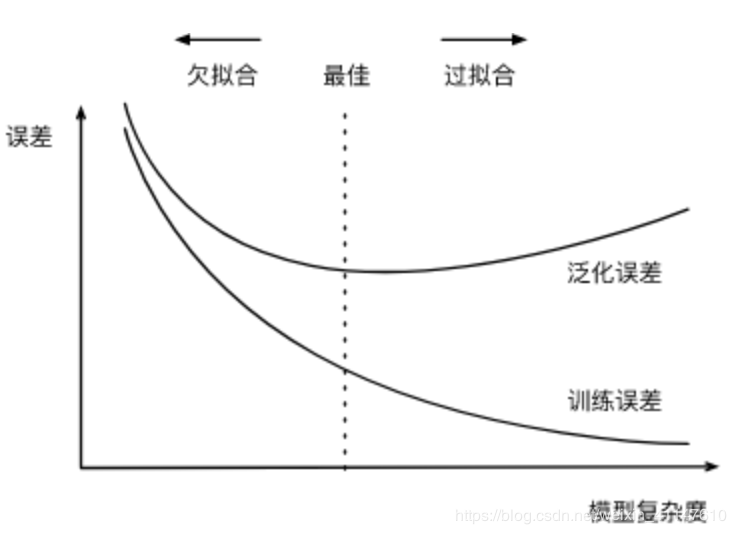
训练集的大小会影响拟合结果,一般来说,训练集小,过拟合容易发生。泛化误差不会碎训练集增大而增大,所以我们通常希望训练集大一些,特别是模型复杂度较高时。
1.5 解决方案 1.5.1 权重衰减权重衰减等价于L2L_2L2范数正则化。正则化通过为模型损失函数添加惩罚项使训练出的模型参数值小,是应对过拟合的常用手段。
1.5.2 L2L_2L2范数正则化L2L_2L2范数正则化在模型损失函数基础上添加L2L_2L2范数惩罚项,从而得到训练所需要的最小化的函数。L2L_2L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。以现行回归中的线性回归损失函数为例
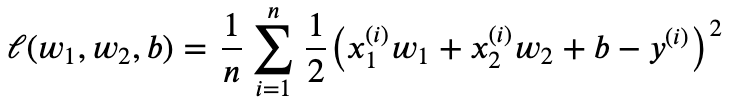
其中