【深度强化学习 一】Q-Learning初识(1)(李宏毅老师学习视频笔记)
首先放视频链接:李宏毅老师深度强化学习课程——Q-Learning
Q-Learning简介Q-Learning是一种value-based的方法,在这种方法中,不是直接学习policy,而是利用值函数评价现在行为的好坏,即AC算法中的critic。比如state value function
state-action value function 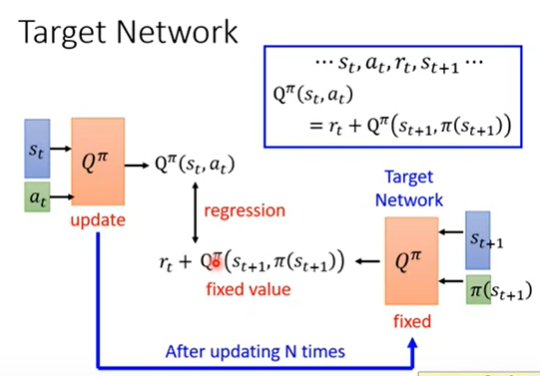
loss的设计和之前一样,只不过targe network delay了一下,牛批。
explore 问题epsilon greedy (的概率随机,随着训练进行而递减)
![]()
![]()
简单来讲就是把过程中的transition存到replay buffer中,然后每次取出一个batch,取出的transition其实是不同policy下的。这种方法和深度学习中常见技巧比较类似。这里有一个问题,mc的方法可以用replay buffer吗?
作者:greyduan
相关文章
Iris
2021-08-03
Laraine
2020-04-28
Heidi
2020-04-15
Adelaide
2020-03-28
Kande
2023-05-13
Ula
2023-05-13
Jacinda
2023-05-13
Winona
2023-05-13
Fawn
2023-05-13
Echo
2023-05-13
Maha
2023-05-13
Kande
2023-05-15
Viridis
2023-05-17
Pandora
2023-07-07
Tallulah
2023-07-17
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20