前端面试题收集整理ಠᴗಠ 查漏补缺刷一波
自由变量和作用域和闭包 ლ(´ڡ`ლ)
2. jwt-token的优缺点JWT的优点:
体积小,因而传输速度更快 多样化的传输方式,可以通过URL传输、POST传输、请求头Header传输(常用)
简单方便,服务端拿到jwt后无需再次查询数据库校验token可用性,也无需进行redis缓存校验
在分布式系统中,很好地解决了单点登录问题
很方便的解决了跨域授权问题,因为跨域无法共享cookie
JWT的缺点:
因为JWT是无状态的,因此服务端无法控制已经生成的Token失效,这是不可控的
获取到JWT也就拥有了登录权限,因此JWT是不可泄露的,网站最好使用https,防止中间攻击偷取JWT
实现登录状态保持的方法:cookie session token jwt
3. vue的生命周期每个vue实例在被创建之前,都要经过一系列的初始化过程,这个过程就是vue的生命周期。
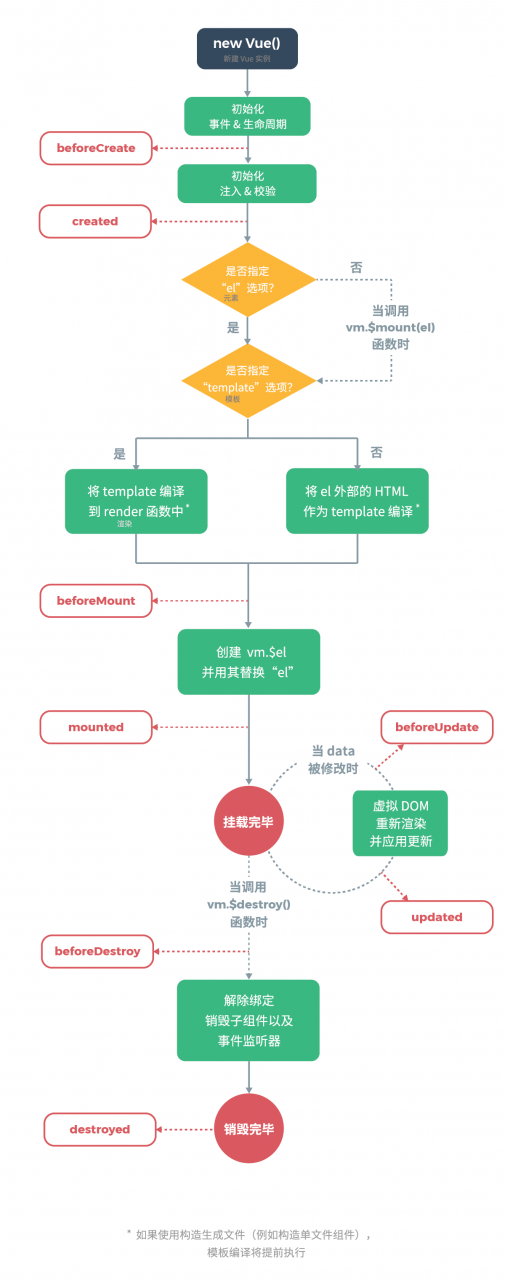
vue整个生命周期中的钩子函数如下:
| 钩子函数 | 组件状态 | 最佳实践 |
|---|---|---|
| beforeCreate | 实例初始化之后,this指向创建的实例,不能访问到data,computed,watch,methods上的方法和数据 | 常用于初始化非响应式变量 |
| created | 实例创建完成,可访问data,computed,watch,methods上的方法和数据,未挂载到DOM,不能访问到el属性,ref属性内容为空数组 | 常用于简单的ajax请求,页面的初始化 |
| beforeMount | 在挂载开始之前被调用,beforeMount之前,会找到对应的template,并编译成render函数 | |
| mounted | 实例挂载在DOM上,此时可以通过DOM API获取到DOM节点,$ref属性可以访问 | 常用于获取VNode信息和操作,ajax请求 |
| beforeupdate | 响应式数据更新时调用,发生在虚拟DOM打补丁之前 | 适合在更新之前访问现有的DOM,比如手动移除已添加的事件监听器 |
| updated | 虚拟DOM重新渲染和打补丁之后调用,组件DOM已经更新,可执行依赖于DOM的操作 | 避免在这个钩子函数中操作数据,可能陷入死循环 |
| beforeDestroy | 实例销毁之前调用。这一步,实例仍然完全可用,this仍能获取到实例 | 常用于销毁定时器,解绑全局事件,销毁插件对象等操作 |
| destroyed | 实例销毁后调用,调用后,Vue实例指示的所有东西都会解绑,所有的事件监听器会被移除,所有的子实例也会被销毁 |
注意:
created阶段的ajax请求与mounted请求的区别:前者页面视图未出现,如果请求信息过多,页面会长时间处于白屏状态
mounted不会承诺所有的子组件也都一起被挂载。如果你希望等到整个视图都渲染完毕,可以用 vm.$nextTick
vue2.0之后主动调用$destroy()不会移除dom节点,作者不推荐直接destroy这种做法,如果实在需要这样用可以在这个生命周期钩子中手动移除dom节点
4. vue数据双向绑定的底层实现
vue实现数据双向绑定主要是:采用 数据劫持结合发布者-订阅者模式的方式,通过 Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应监听回调。当把一个普通 Javascript对象传给 Vue 实例来作为它的 data 选项时,Vue将遍历它的属性,用 Object.defineProperty()将它们转为getter/setter。用户看不到 getter/setter,但是在内部它们让 Vue 追踪依赖,在属性被访问和修改时通知变化。
vue的数据双向绑定 将MVVM作为数据绑定的入口,整合Observer,Compile和Watcher三者,通过Observer来监听自己的model的数据变化,通过Compile来解析编译模板指令(vue中是用来解析 {{}}),最终利用watcher搭起observer和Compile之间的通信桥梁,达到数据变化 —>视图更新;视图交互变化(input)—>数据model变更双向绑定效果。
传统的回调函数
当一个函数需要依赖上一个回调函数的值的时候,就会形成回调函数嵌套(如setTimeout,ajax等)
传统的回调函数处理方式会产生“回调地狱”,代码横向发展
setTimeout(function () {
//do something
setTimeout(function () {
//do something
setTimeout(function () {
//do something
setTimeout(function () {
//do something
}, 1000)
}, 1000)
}, 1000)
}, 1000)
Promise
Promise(ES2015) 是异步编程的一种解决方案,其实是一个构造函数,自己身上有all、reject、resolve这几个方法,原型上有then、catch等方法。
如下,链式操作,代码纵向发展
let p = new Promise(function(resolve,reject){
resolve(1)
})
p.then(function(value){
console.log(value) // 1
return value*2
}).then(function(value){
console.log(value) // 2
}).then(function(value){
console.log(value) // undefined
return Promise.resolve('resolve')
}).then(function(value){
console.log(value) // resolve
return Promise.reject('reject')
}).then(function(value){
console.log(value)
},function(err){
console.log(err) // reject
})
async/await
尽管Promise解决了地狱回调问题,但是还是不够简洁,一个是横向发展,一个是纵向发展。
所以ES2017增加了异步函数,async/await使代码看起来像是同步的,但它在后台是异步和非阻塞的。
async是一个修饰符,async定义的函数会默认的返回一个Promise对象resolve的值,因此对async函数可以直接进行then操作,返回的值即为then方法的传入函数
async function funa() {
console.log('a')
return 'a'
}
funa().then( x => { console.log(x) }) // 输出: a a
async function funp() {
console.log('Promise')
return new Promise(function(resolve, reject){
resolve('Promise')
})
}
funp().then( x => { console.log(x) }) // 输出: Promise Promise
await也是一个修饰符,
await 关键字 只能放在 async函数内部, await关键字的作用 就是获取 Promise中返回的内容, 获取的是Promise函数中resolve或者reject的值
如果await后面并不是一个Promise的返回值,则会按照同步程序返回值处理
const text1 = () => {
return new Promise(resolve => {
setTimeout(() => resolve('I did something'), 10000)
})
}
const text2 = async () => {
const something = await text1()
return something + ' and I watched'
}
const text3 = async () => {
const something = await text2()
const s = await '啊'
return something + ' and I watched as well'+ s
}
text3().then((res) => {
console.log(res) //I did something and I watched and I watched as well啊
})
6. Vue-Router模式
vue-router中的模式选项主要在router实例化的时候定义:
示例代码:
export default new Router({
mode: 'history', // 两种类型:history 或者 hash
routes
})
| 模式 | 优点 | 缺点 |
|---|---|---|
| hash | 使用简单,无需后台支持 | 在url中以hash形式存在,不会传到后台 |
| history | 地址明确,便于理解和后台处理 | 需要后台配合 |
vue-router 默认 hash 模式 ;例如:
http://yoursite.com/#/index,hash值为#/index。hash模式的特点在于hash出现在url中,但是不会被包括在HTTP请求中,对后端没有影响,不会重新加载页面。
当你使用 history 模式时,URL 就像正常的 url,例如 http://yoursite.com/user/id,相比hash模式更加好看
不过这种模式要玩好,还需要后台配置支持。因为我们的应用是个单页客户端应用,如果后台没有正确的配置,当用户在浏览器直接访问 http://oursite.com/user/id 就会返回 404,这就不好看了。
所以呢,你要在服务端增加一个覆盖所有情况的候选资源:如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面,这个页面就是你 app依赖的页面。
7. 前端测试和web压力测试
 这方面还没涉及到,好像是使用很多测试工具的样子,容我缓缓,后续补上。。。
8. XSS和CSRF以及如何防范
这方面还没涉及到,好像是使用很多测试工具的样子,容我缓缓,后续补上。。。
8. XSS和CSRF以及如何防范
XSS,CSRF,SQL注入
9. SPA如何计算PV单页面应用 SPA(Single Page Application)
概念: Web应用即使不刷新也在不同的页面间切换,解决浏览器前进,后退等机制被破坏等问题
实现方法:
Node+Html5实现
React/Vue等MVVM框架
页面访问量 PV(PageView)
那么,SPA如何计算PV?
利用 Page Visibility和History API来准确统计 Page View的基本思路如下(这种思路适用于传统网站、SPA、PWA):
visibilityState 是可见的,发送 Page View统计;
如果页面的 visibilityState 是隐藏的,就监听 visibilitychange 事件,并在 visibilityState 变为可见时发送 Page View 统计;
如果 visibilityState 由隐藏变为可见,并且自上次用户交互之后已经过了“足够长”的时间,就发送新的Page View统计;
如果 URL 发生变化(仅限于 pathname 或 search 部分发送变化, hash 部分则应该忽略,因为它是用来标记页面内跳转的) 发送新的Page View统计;
以上内容来源自:为什么你统计 PV 的方式是错的?感兴趣的可以看看
总结: 统计PV,可以自己写脚本,可以用别人写的脚本,也可以使用一些平台的API(如:百度统计开放平台等)
1
2
3
4
var allP = document.querySelectorAll('p')
console.log(allP)
console.log([...allP])
控制台输出如下:


作者:zoyoy