pytorch中Tensor.to(device)和model.to(device)的区别及说明
Tensor.to(device)和model.to(device)的区别
区别所在
举例
pytorch学习笔记--to(device)用法
这段代码到底有什么用呢?
为什么要在GPU上做运算呢?
.cuda()和.to(device)的效果一样吗?为什么后者更好?
如果你有多个GPU
Tensor.to(device)和model.to(device)的区别 区别所在使用GPU训练的时候,需要将Module对象和Tensor类型的数据送入到device。通常会使用 to.(device)。但是需要注意的是:
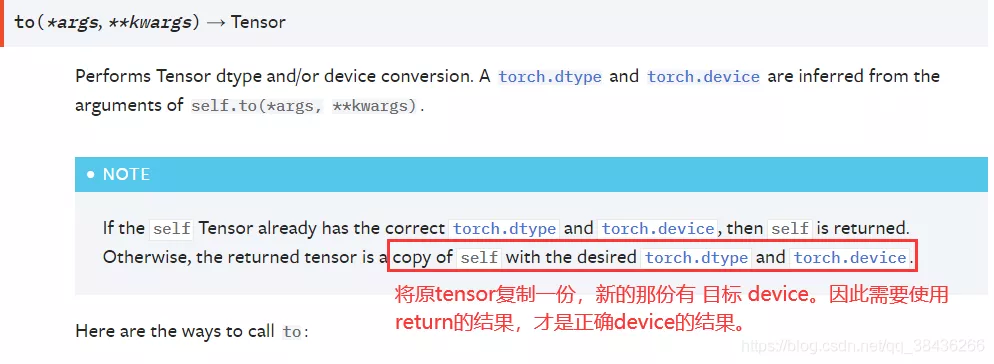
对于Tensor类型的数据,使用to.(device) 之后,需要接收返回值,返回值才是正确设置了device的Tensor。
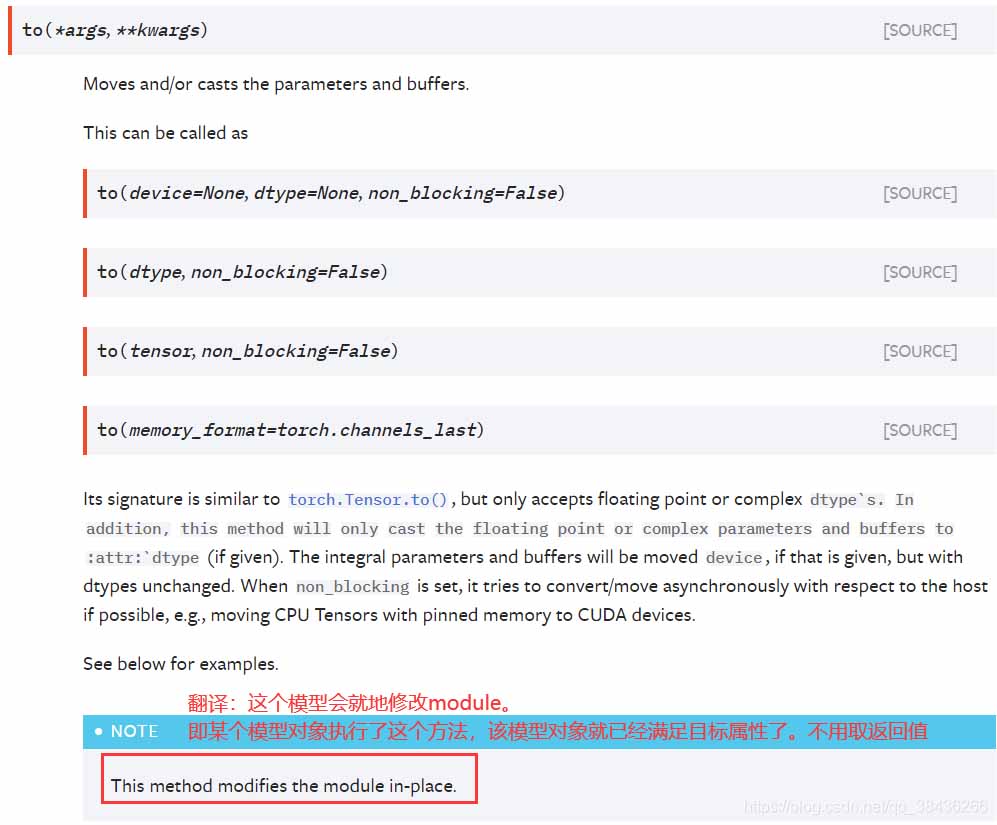
对于Module对象,只用调用to.(device) 就可以将模型设置为指定的device。不必接收返回值。
来自pytorch官方文档的说明:
Tensor.to(device)
Module.to(device)
# Module对象设置device的写法
model.to(device)
# Tensor类型的数据设置 device 的写法。
samples = samples.to(device)
pytorch学习笔记--to(device)用法
在学习深度学习的时候,我们写代码经常会见到类似的代码:
img = img.to(device=torch.device("cuda" if torch.cuda.is_available() else "cpu"))
model = models.vgg16_bn(pretrained=True).to(device=torch.device("cuda" if torch.cuda.is_available() else "cpu"))
也可以先定义device:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
img = img.to(device)
这段代码到底有什么用呢?
这段代码的意思就是将所有最开始读取数据时的tensor变量copy一份到device所指定的GPU上去,之后的运算都在GPU上进行。
为什么要在GPU上做运算呢?首先,在做高维特征运算的时候,采用GPU无疑是比用CPU效率更高,如果两个数据中一个加了.cuda()或者.to(device),而另外一个没有加,就会造成类型不匹配而报错。
tensor和numpy都是矩阵,前者能在GPU上运行,后者只能在CPU运行,所以要注意数据类型的转换。
.cuda()和.to(device)的效果一样吗?为什么后者更好?两个方法都可以达到同样的效果,在pytorch中,即使是有GPU的机器,它也不会自动使用GPU,而是需要在程序中显示指定。调用model.cuda(),可以将模型加载到GPU上去。这种方法不被提倡,而建议使用model.to(device)的方式,这样可以显示指定需要使用的计算资源,特别是有多个GPU的情况下。
如果你有多个GPU那么可以参考以下代码:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Model()
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model,device_ids=[0,1,2])
model.to(device)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持软件开发网。