初识python正则表达式和re模块
正则表达式和re模块
作者:pretext1923834375
介绍:按照一定的规则,从某个字符串中匹配出想要的数据。这个规则就是正则表达式
match只能从开始匹配
search从全部匹配
正则表达式规则:| 表达式 | 作用 |
|---|---|
| . | 匹配任意的字符,不能匹配到换行符 |
| \d | 匹配任意的数字 |
| \D | 匹配任意的非数字 |
| \s | 匹配空白字符(包括:\n,\t,\r,空格) |
| \w | 匹配a-z和A-Z以及数字.下划线 |
| \W | 匹配和\w相反的东西 |
| + | 匹配一个或多个 |
| * | 匹配0个或多个 |
| ? | 匹配的字符可以出现一次或0次 |
| {m} | 匹配m个字符 |
| {m,n} | 匹配m到n个 |
| ^(脱字号) | 中括号中表示取反, 外面表以什么开始 |
| $ | 表示以什么结 尾, 在最后添加$ |
| | | 匹配多个字符串或表达式 |
转义字符
如果符号有特殊意义,在前面加一个\表示转义
原生字符串
python中自带转义字符\
text = '\\n'
print(text) #\n
text = r'\n' #raw 生的
print(text) #\n
text = "\\c"
#在python中等价\n
#正则表达式中:\n
ret = re.match('\\\\c', text)
#ret = re.match(r'\\c', text)
print(ret.group()) #\c
组合方式[]
等价带换
\d: [0-9] \D:[^0-9]
\w [0-9a-zA-Z_]
\W [^0-9a-zA-Z_]
贪婪模式
匹配全部
text = ' title
''
ret = re.match('', text)
print(ret) # title
非贪婪模式
匹配部分
text = ' title
''
ret = re.match('', text)
print(ret) #
正则案例
1.验证手机号码:手机号码的规则是以1开头,第二位可以是34587 ,后面那9位就可以随意了。示例代码如下:
text = 12345678943
ret = re.match('1[34578]\d{9}',text)
2.验证邮箱
re.match('\w+@[a-z0-9]+\.[a-z]+',text) #对点进行了转义
3.验证URL
re.match('(http|https|ftp)://[^\s]+', text)
4.验证身份证
regex = '\d{17}[\dxX]'
5.匹配0-100的数字
不能出现的.08, 101
regex = '[1-9]\d?$|100$'
re模块中的函数
match:从开始找
search:整个字符串找
分组group
在正则表达式中,可以对过滤到的字符串进行分组。分组使用圆括号的方式。
group :和group(0)是等价的,返回的是整个满足条件的字符串。 groups :返回的是里面的子组。索引从1开始。 group(1) :返回的是第一个子组,可以传入多个。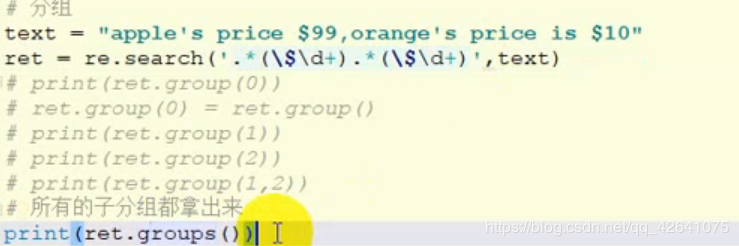
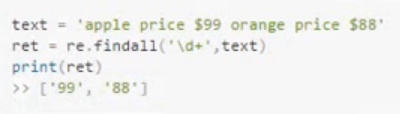
findall
找出所有满足条件的,返回的是一个列表
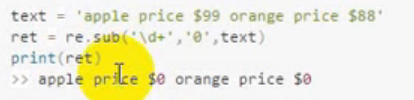
sub
用来替换字符串,将匹配到的字符串替换为其他字符串
split
分隔字符串,返回一个列表
compile
对于一些经常要用到的正则表达式,可以使用compile进行编译,后期再使用的时候可以直接拿过来用,执行效率会更快。而且compile 还可以指定flag=re.VERBOSE ,在写正则表达式的时候可以做好注释。示例代码如下:
text = 'the number is 20.50'
r = re.compile('\d+\.?\d*')
ret = re.search(r, text)
print(ret.group())
下面这种方式可以添加注释
text = 'the number is 20.50'
r = re.compile(r"""
\d+ #小数点前面的数字
\.? #小数点本身
\d* #小数点后面的数字
""",re.VERBOSE)
ret = re.search(r, text)
print(ret.group())
作者:pretext1923834375