适合小白的python算法-单词匹配模式【hash练习】
单词匹配模式一、问题描述二、涉及知识点三、问题分析四、代码构建五、运行调试五、相关知识补充
第一项任务是建立哈希表来存储数据,由于不仅需要排除一个模式对应多个字符串的情况还需要排除。多个模式对应一个字符串的情况,我们需要建立两个哈希表。
hash用来存储模式的字符串和目标字符串的对应关系。
used用来记录已经使用过的目标字符串 四、代码构建
作者:f3NWIVKIo@t5

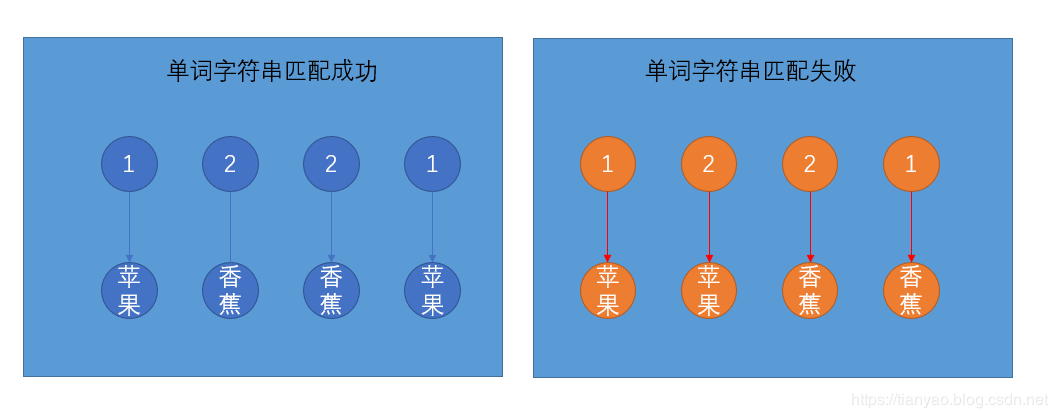
给定两个字符串,一个是单词模式字符串,另一个是目标字符串。之后检查目标字符串是否为给定得单词模式,即求目标字符串中单词出现的规律是否和单词模式字符串中的规律相同。
例如:单词模式字符串为“—二二一”,目标字符串为“苹果香蕉香蕉苹果",二者得规律一样,匹配成功。
第一项任务是建立哈希表来存储数据,由于不仅需要排除一个模式对应多个字符串的情况还需要排除。多个模式对应一个字符串的情况,我们需要建立两个哈希表。
hash用来存储模式的字符串和目标字符串的对应关系。
used用来记录已经使用过的目标字符串 四、代码构建
def wordmatch (word ,input0):
input1 = input0.split(' ') #将目标字符串中单词以空格分开
words = word.split(' ') #模式字符串也以空格分开
if len (input1) != len (words): #判断字符串长度是否一致
return False
hash = {} # 记录连个字符串的对应关系
used = {} #记录使用过的字符串
for i in range(len(words)): # 遍历整个字符串
if words[i] in hash : #判断检查模式的字符串是否被记录过映射关系
if hash[words[i]] != input1[i] : #检查映射关系是否一致
return False
else :
if input1[i] in used: #检查单词是否使用过
return False
hash [words[i]] = input1[i] #第一次出现,加入hash表
used[input1[i]] = True # 记录那些单词使用过
return True
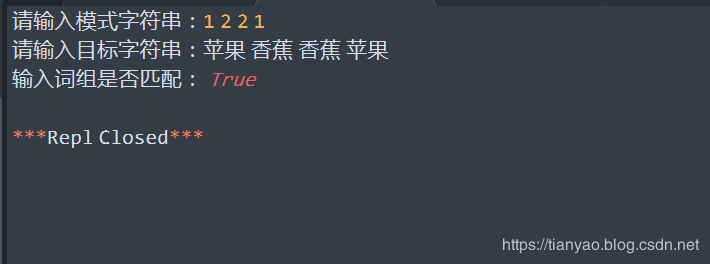
a = input('请输入模式字符串:')
b = input ('请输入目标字符串:')
s = wordmatch(words,b) #调用函数
print('输入词组是否匹配:',s)
五、运行调试
1.一一映射:就是集合A和集合B中的元素可以相互映射,且一一对应,常见一一映射如 学生身份证号和学号
2.字符串转换成列表:
str.split(sep=None, maxsplit=-1)
返回一个由字符串内单词组成的列表,使用 sep 作为分隔字符串。 如果给出了 maxsplit,则最多进行 maxsplit 次拆分(因此,列表最多会有 maxsplit+1 个元素)。 如果 maxsplit 未指定或为 -1,则不限制拆分次数(进行所有可能的拆分)。
如果给出了 sep,则连续的分隔符不会被组合在一起而是被视为分隔空字符串 (例如 ‘1,2’.split(’,’) 将返回 [‘1’, ‘’, ‘2’])。 sep 参数可能由多个字符组成 (例如 ‘123’.split(’’) 将返回 [‘1’, ‘2’, ‘3’])。 使用指定的分隔符拆分空字符串将返回 [’’]。
例如
>>>
>>> '1,2,3'.split(',')
['1', '2', '3']
>>> '1,2,3'.split(',', maxsplit=1)
['1', '2,3']
>>> '1,2,,3,'.split(',')
['1', '2', '', '3', '']
如果 sep 未指定或为 None,则会应用另一种拆分算法:连续的空格会被视为单个分隔符,其结果将不包含开头或末尾的空字符串,如果字符串包含前缀或后缀空格的话。 因此,使用 None 拆分空字符串或仅包含空格的字符串将返回 []。
例如
>>>
>>> '1 2 3'.split()
['1', '2', '3']
>>> '1 2 3'.split(maxsplit=1)
['1', '2 3']
>>> ' 1 2 3 '.split()
['1', '2', '3']
作者:f3NWIVKIo@t5