python算法学习双曲嵌入论文代码实现数据集介绍
1. 目标
Python 代码依赖库
2. 数据集
数据展示
学习的文章:
Poincaré Embeddings for Learning Hierarchical Representations
主要参考的代码:
poincare_embeddings
gensim – Topic Modelling in Python - poincare.py
由于有些代码难以运行,有些比较难读(封装程度非常高)甚至有些代码写得存在一些问题。因此我们重新按照论文的设置,利用Python重现了对应的方法,并成功运行,同时进行绘图展示。
我们有一些层级结构的网络类型数据,如何能够根据每个词的上下结构路径,将每个词语能够用一个向量来替换,换句话说,就是将词映射为实数域中的向量(词嵌入,word embedding)。最简单的想法是使用one-hot词向量,其构造起来很容易,但通常并不是一个好选择。主要的原因是,one-hot词向量无法准确表达不同词之间的相似度,同时也不能刻画词语之间的层次结构。而在另外的方法中,采用最多的是在欧式空间里进行嵌入(word2vec),这种方式的embedding可以有效表示出词语间的相似性,但却依旧难以刻画出词语之间的层次结构。
这时候为了既能够衡量词与词之间的相似性,又能衡量这种词与词之间的层次结构,引入了双曲几何的思想,在双曲空间中进行嵌入。双曲嵌入表征层级结构的能力就要比欧氏空间嵌入的能力高得多,同时需要的维数却更少。
Python 代码依赖库为了能够顺利跑通后面的代码,这里先展示出代码需要依赖的库:
import nltk
# nltk.download('wordnet') # 第一次运行需运行此命令,安装wordnet数据集
from nltk.corpus import wordnet as wn
from math import *
import random
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
import networkx as nx
2. 数据集
训练数据集采用wordnet中的数据进行实现,相关的数据说明在上周的文档中已经进行了介绍,这里不再进行赘述。
由于整个的wordnet数据集比较大,为了测试代码,我们只使用哺乳动物(mammal)及其相关的分支进行学习。首先我们看看数据集长什么样。由于我们只需要用到层次结构信息,因此我们只需将数据集里面每个哺乳动物相关名词的子节点与父节点的关系进行读取与构建。
network = {} # 构建层级网络
last_level = 8 # 最深的层设置为8层
levelOfNode = {} # 数据的层级信息,0为哺乳动物(根节点),1为哺乳动物下一结构
# 递归构建network
def get_hyponyms(synset, level):
if (level == last_level):
levelOfNode[str(synset)] = level
return
if not str(synset) in network:
network[str(synset)] = [str(s) for s in synset.hyponyms()]
levelOfNode[str(synset)] = level
for hyponym in synset.hyponyms():
get_hyponyms(hyponym, level + 1)
# 构建以哺乳动物为根节点的层次结构数据集
mammal = wn.synset('mammal.n.01')
get_hyponyms(mammal, 0)
levelOfNode[str(mammal)] = 0
# 将终端叶子节点补到network字典中
for a in levelOfNode:
if not a in network:
network[a] = []
数据展示
运行完成上述代码后,可以得到对应的节点层级,以及总体的网络分支。
节点层级(数值表示层级数,最深的层设置为6,0为根节点)

网络分支情况

为了更清晰地将树的结构进行刻画,用一个代码进一步将相关的层次结构直接进行展示。
def norm(x):
return np.dot(x, x)
def traverse(graph, start, node):
node_name = node.name().split(".")[0]
graph.depth[node_name] = node.shortest_path_distance(start)
for child in node.hyponyms():
child_name = child.name().split(".")[0]
graph.add_edge(node_name, child_name) # 添加边
traverse(graph, start, child) # 递归构建
def hyponym_graph(start):
G = nx.Graph() # 定义一个图
G.depth = {}
traverse(G, start, start)
return G
def graph_draw(graph):
plt.figure(figsize=(10, 10)) # 展示整体的网络
# plt.figure(figsize=(3, 3)) # 展示大象网络
nx.draw(graph,
node_size = [10 * graph.degree(n) for n in graph],
node_color = [graph.depth[n] for n in graph],
alpha = 0.8,
font_size = 4,
width = 0.5,
with_labels = True)
def get_keys(d, value):
return [k for k,v in d.items() if v == value]
root_name = get_keys(graph.depth, 0)[0]
plt.savefig("~/hyperE/fig/" + root_name + ".png", dpi = 300)
graph = hyponym_graph(mammal)
graph_draw(graph)
绘制出来的哺乳动物(mammal)全体的结构如下(此时没有空间信息,只有层级信息,为了展示才显示为下图所示的样式):
其中,颜色越深,节点越大,表示节点的层级越接近根节点(哺乳动物)。
由于数据非常多,展示的不是很清楚,这里我们单纯的提出出来大象(elephant)的结构,进一步看看数据集的情况。
elephant = wn.synset('elephant.n.01')
graph = hyponym_graph(elephant)
graph_draw(graph)
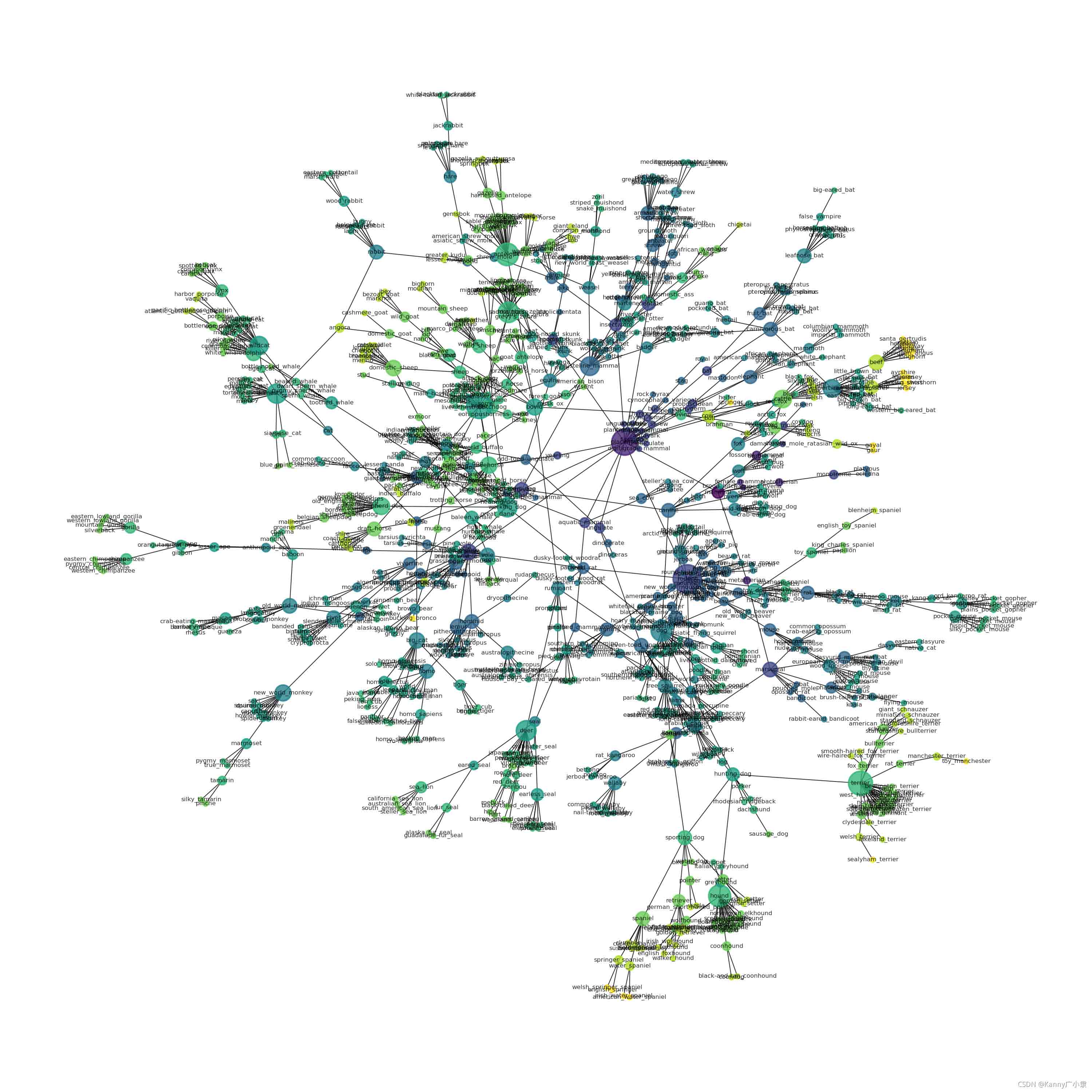
后面我们将利用这份数据集,进行方法的介绍,以及双曲嵌入模型的训练。
请见:python算法学习双曲嵌入论文方法与代码解析说明
以上就是python算法学习双曲嵌入论文代码实现数据集介绍的详细内容,更多关于python算法数据集双曲嵌入论文代码的资料请关注软件开发网其它相关文章!